Как выполнить многомерное масштабирование в python
В статистике многомерное масштабирование — это способ визуализировать сходство наблюдений в наборе данных в абстрактном декартовом пространстве (обычно в двумерном пространстве).
Самый простой способ выполнить многомерное масштабирование в Python — использовать функцию MDS() подмодуля sklearn.manifold .
В следующем примере показано, как использовать эту функцию на практике.
Пример: многомерное масштабирование в Python
Предположим, у нас есть следующий DataFrame pandas, содержащий информацию о различных баскетболистах:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Мы можем использовать следующий код для выполнения многомерного масштабирования с помощью функции MDS() модуля sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Каждая строка исходного DataFrame была уменьшена до координаты (x, y).
Мы можем использовать следующий код для визуализации этих координат в 2D-пространстве:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
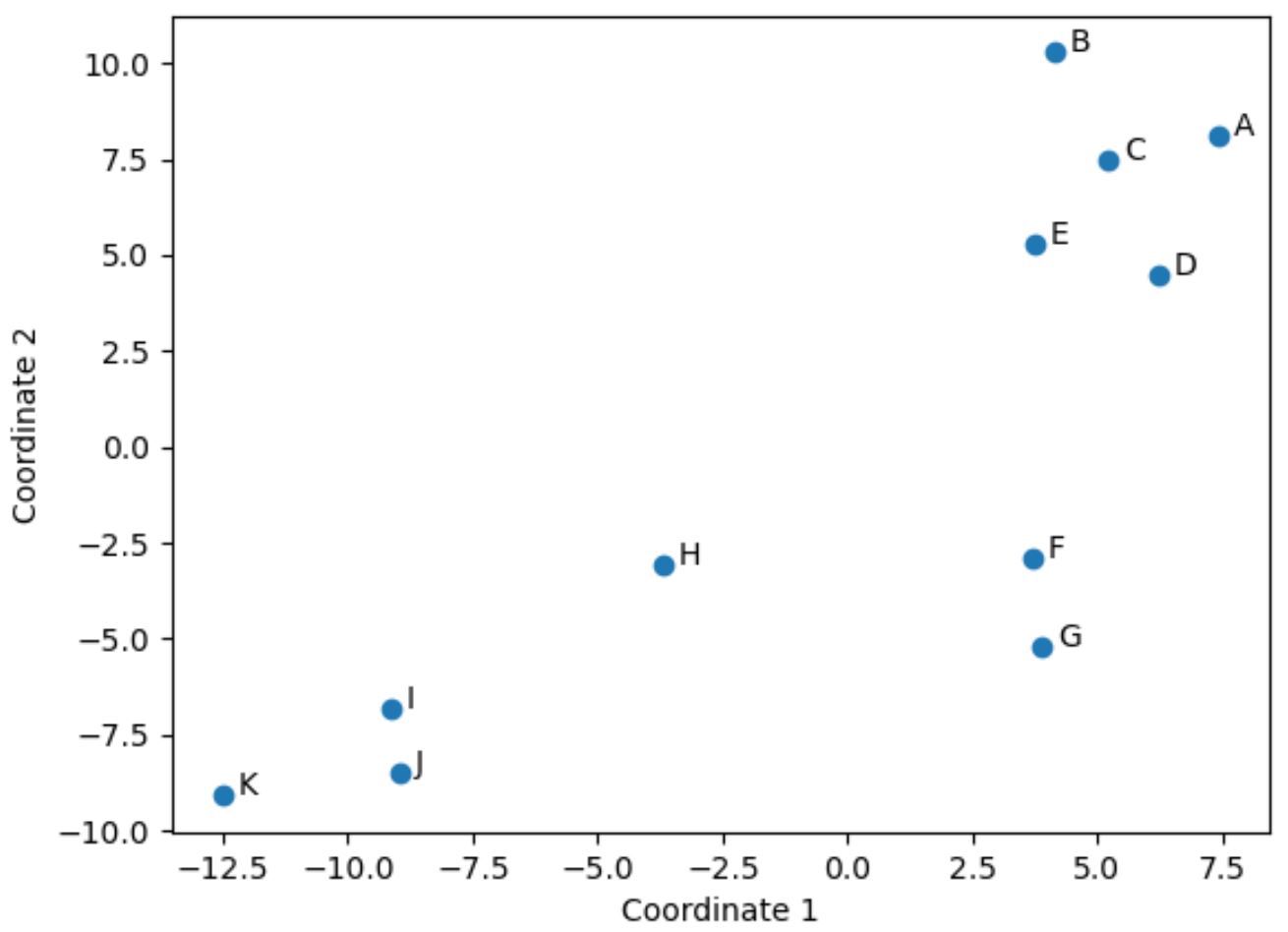
Игроки в исходном DataFrame, у которых в исходных четырех столбцах одинаковые значения (очки, передачи, блоки и подборы), находятся на графике близко друг к другу.
Например, игроки F и G закрыты друг для друга. Вот их значения из исходного DataFrame:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
Их значения очков, передач, блоков и подборов очень похожи, что объясняет, почему они так близки друг к другу на 2D-графике.
Напротив, рассмотрим игроков B и K , которые находятся далеко друг от друга в сюжете.
Если мы обратимся к их значениям в исходном DataFrame, то увидим, что они совершенно разные:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Таким образом, двухмерный график — хороший способ визуализировать, насколько похожи каждый игрок по всем переменным в DataFframe.
Игроки со схожими характеристиками группируются близко друг к другу, а игроки с очень разными характеристиками находятся дальше друг от друга по сюжету.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи на Python:
Как нормализовать данные в Python
Как удалить выбросы в Python
Как проверить нормальность в Python
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше