Как выполнить множественную линейную регрессию в sas
Множественная линейная регрессия — это метод, который мы можем использовать, чтобы понять взаимосвязь между двумя или более переменными-предикторами и переменной отклика .
В этом руководстве объясняется, как выполнить множественную линейную регрессию в SAS.
Шаг 1. Создайте данные
Предположим, мы хотим подогнать модель множественной линейной регрессии, которая использует количество часов, потраченных на обучение, и количество сданных практических экзаменов для прогнозирования итоговой оценки студента на экзамене:
Оценка экзамена = β 0 + β 1 (часы) + β 2 (подготовительные экзамены)
Сначала мы будем использовать следующий код, чтобы создать набор данных, содержащий эту информацию для 20 студентов:
/*create dataset*/ data exam_data; input hours prep_exams score; datalines ; 1 1 76 2 3 78 2 3 85 4 5 88 2 2 72 1 2 69 5 1 94 4 1 94 2 0 88 4 3 92 4 4 90 3 3 75 6 2 96 5 4 90 3 4 82 4 4 85 6 5 99 2 1 83 1 0 62 2 1 76 ; run ;
Шаг 2. Выполните множественную линейную регрессию
Далее мы будем использовать proc reg , чтобы подогнать к данным модель множественной линейной регрессии:
/*fit multiple linear regression model*/ proc reg data =exam_data; model score = hours prep_exams; run ;
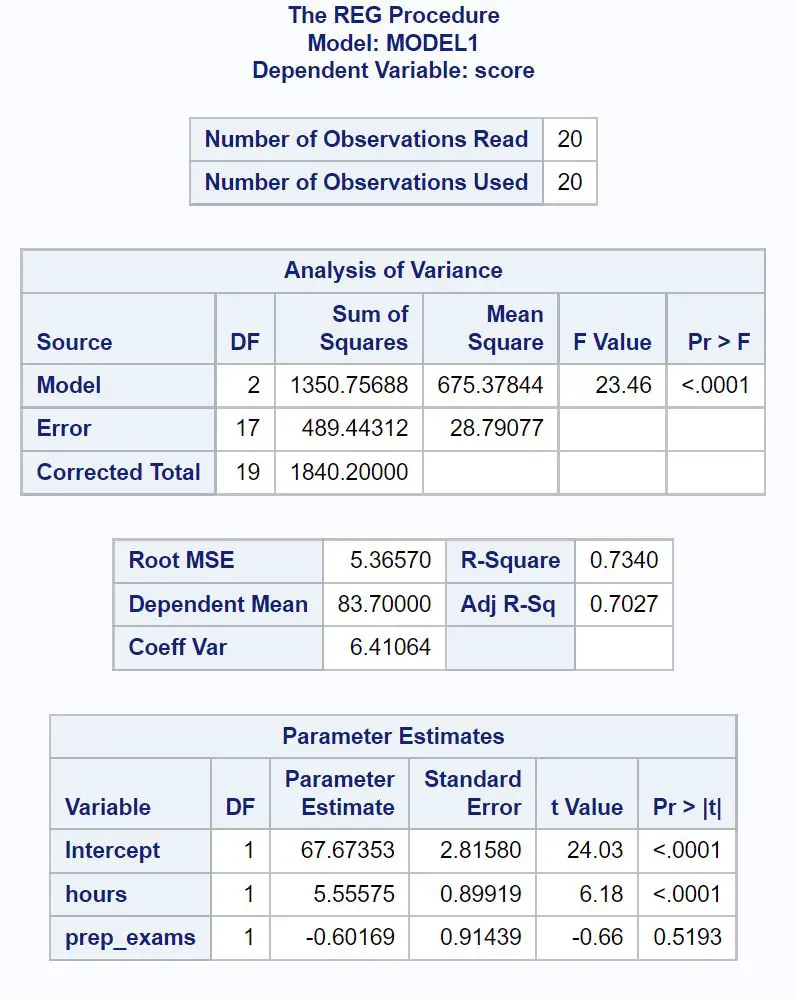
Вот как интерпретировать наиболее релевантные цифры в каждой таблице:
Таблица анализа пробелов:
Общее значение F регрессионной модели составляет 23,46 , а соответствующее значение p составляет <0,0001 .
Поскольку это значение p меньше 0,05, мы заключаем, что регрессионная модель в целом статистически значима.
Таблица соответствия модели:
Значение R-квадрата показывает нам процент вариации результатов экзаменов, который можно объяснить количеством учебных часов и количеством сданных подготовительных экзаменов.
В общем, чем больше значение R-квадрата регрессионной модели, тем лучше переменные-предикторы прогнозируют значение переменной отклика.
При этом 73,4% разброса экзаменационных баллов можно объяснить количеством учебных часов и количеством сданных подготовительных экзаменов.
Также полезно знать значение Root MSE . Это представляет собой среднее расстояние между наблюдаемыми значениями и линией регрессии.
В этой регрессионной модели наблюдаемые значения отклоняются в среднем на 5,3657 единиц от линии регрессии.
Таблица оценок параметров:
Мы можем использовать значения оценки параметров в этой таблице, чтобы написать подобранное уравнение регрессии:
Оценка экзамена = 67,674 + 5,556*(часы) – 0,602*(prep_exams)
Мы можем использовать это уравнение, чтобы найти ориентировочный балл студента на экзамене, исходя из количества часов обучения и количества сданных практических экзаменов.
Например, студент, который учится 3 часа и сдает 2 подготовительных экзамена, должен получить экзаменационный балл 83,1 :
Предполагаемый балл на экзамене = 67,674 + 5,556*(3) – 0,602*(2) = 83,1
Значение p для часов (<0,0001) составляет менее 0,05, что означает, что оно имеет статистически значимую связь с результатом экзамена.
Однако значение p для подготовительных экзаменов (0,5193) составляет не менее 0,05, что означает, что оно не имеет статистически значимой связи с результатом экзамена.
Мы можем решить удалить из модели подготовительные экзамены, поскольку они не являются статистически значимыми, и вместо этого выполнить простую линейную регрессию, используя часы обучения в качестве единственной предикторной переменной.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в SAS:
Как рассчитать корреляцию в SAS
Как выполнить простую линейную регрессию в SAS
Как выполнить односторонний дисперсионный анализ в SAS
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше