Как создавать и интерпретировать диаграммы рассеяния в spss
Диаграмма рассеяния — это тип диаграммы, которую мы можем использовать для отображения взаимосвязи между двумя переменными. Это помогает нам визуализировать как направление (положительное или отрицательное), так и силу (слабая, умеренная, сильная) связи между двумя переменными.
В этом руководстве объясняется, как создавать и интерпретировать диаграммы рассеяния в SPSS.
Как создать диаграммы рассеяния в SPSS
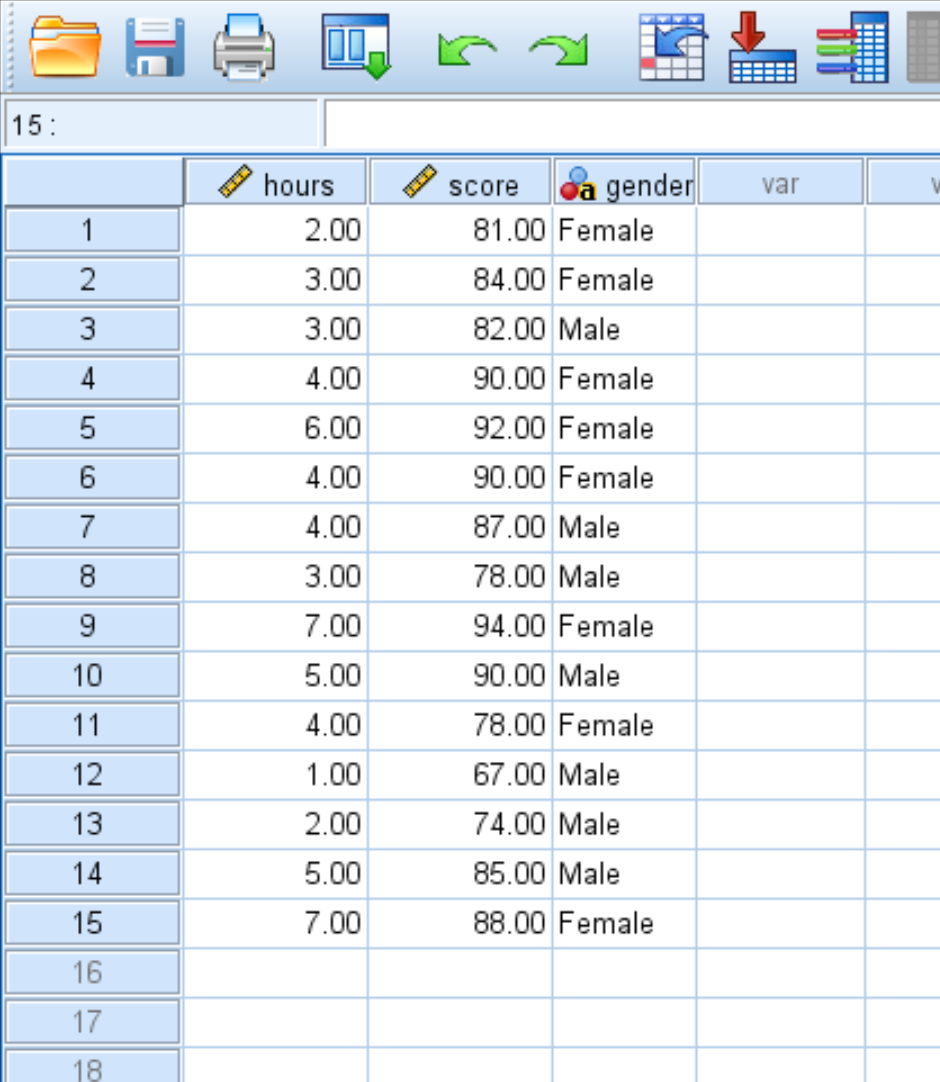
Предположим, у нас есть следующий набор данных, который отображает часы обучения и результаты экзаменов, полученные 15 студентами:
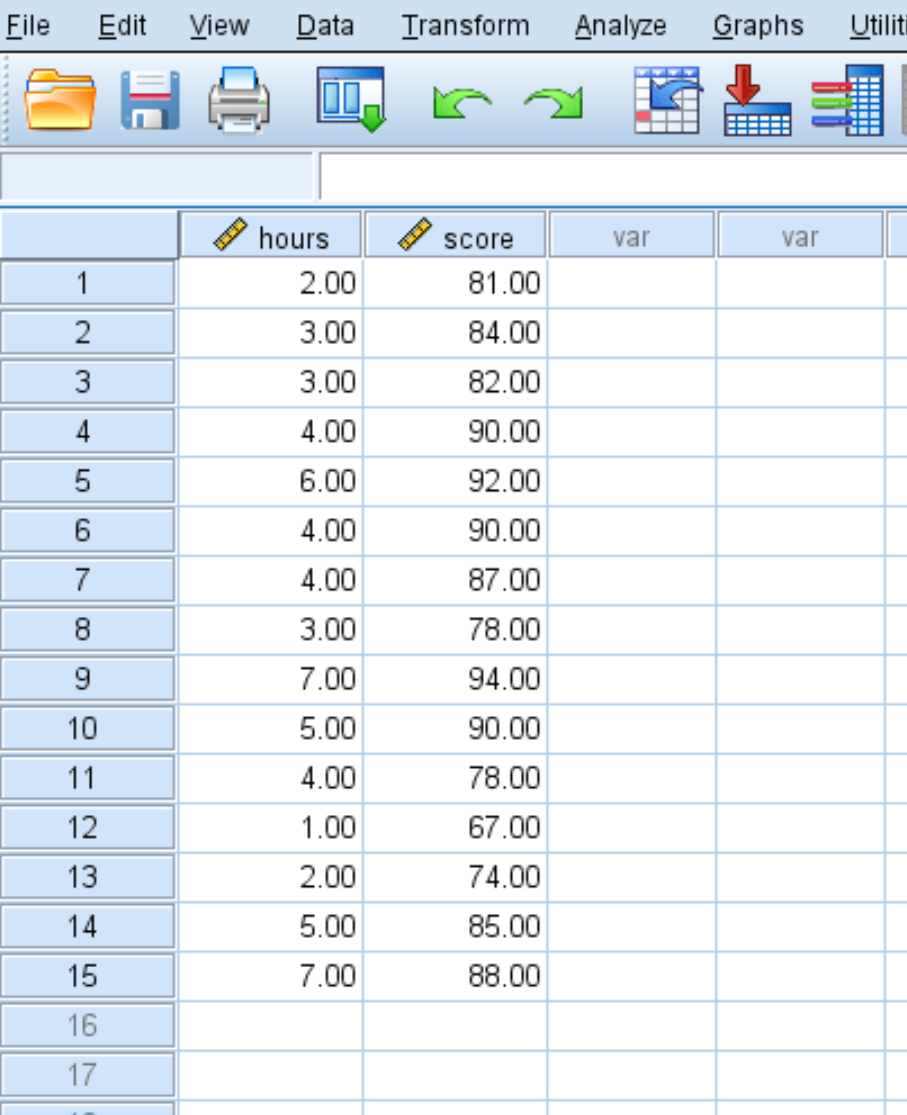
Мы можем создать диаграмму рассеяния, чтобы визуализировать взаимосвязь между учебными часами и баллами на экзамене.
Базовая диаграмма рассеяния
Мы можем создать базовую диаграмму рассеяния в SPSS, щелкнув вкладку «Диаграммы» , затем «Построитель диаграмм» :
В появившемся окне нажмите Scatter/Point в списке Choose from:. Затем перетащите первый вариант с надписью Simple Scatter в окно редактирования. Перетащите переменное время по оси X и счет по оси Y:
Как только вы нажмете «ОК» , появится следующая диаграмма рассеяния:
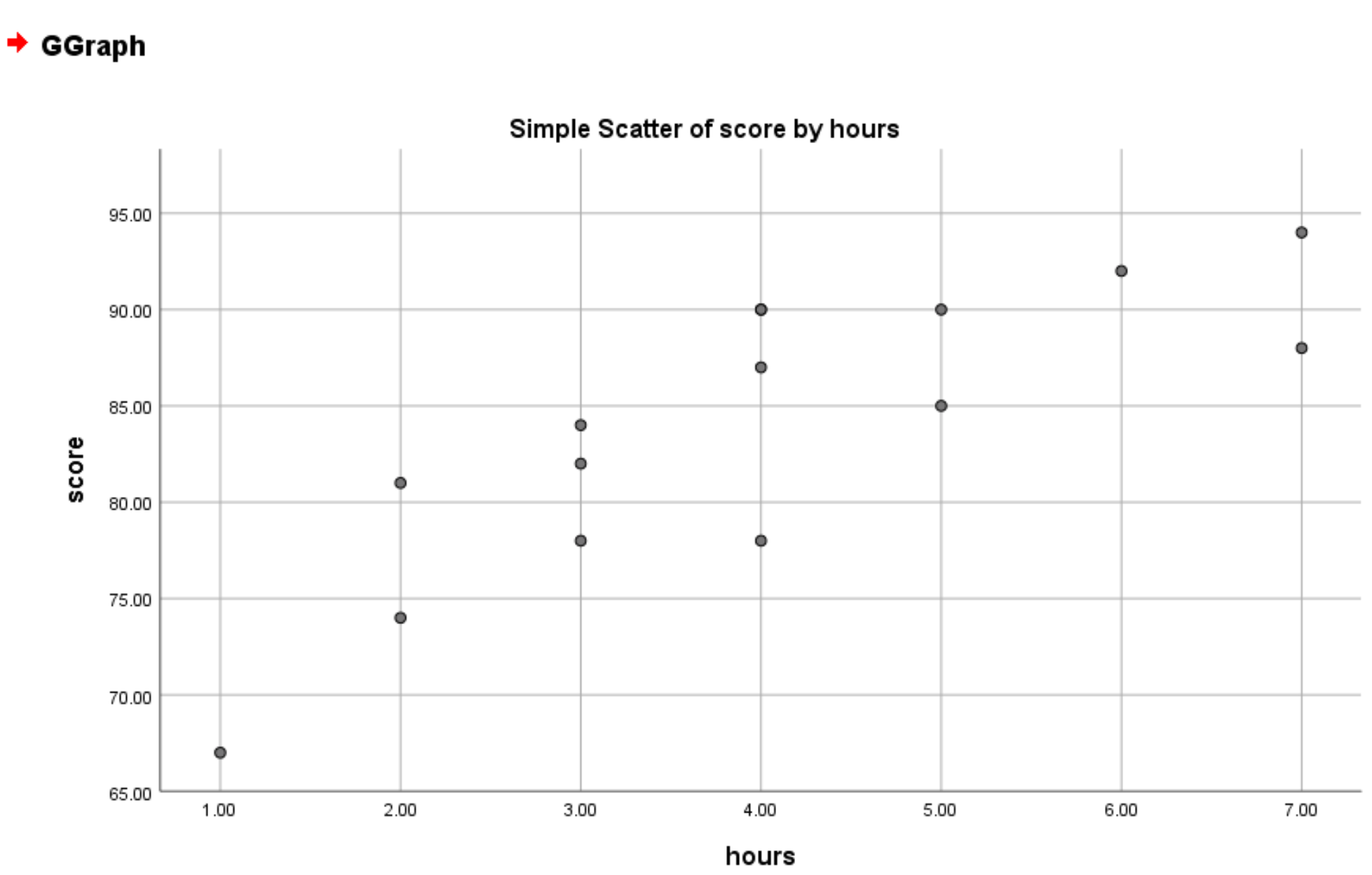
По умолчанию SPSS выбирает минимальную точку для оси Y на основе наименьшего значения в вашем наборе данных. В этом примере минимальная точка на оси Y равна 65. Чтобы изменить ее на 0, щелкните Ось Y1 (Точка1) в поле «Свойства элемента» и установите минимальное значение на 0:
Как только вы нажмете «ОК» , появится новая диаграмма рассеяния с минимальным значением оси Y, равным 0:
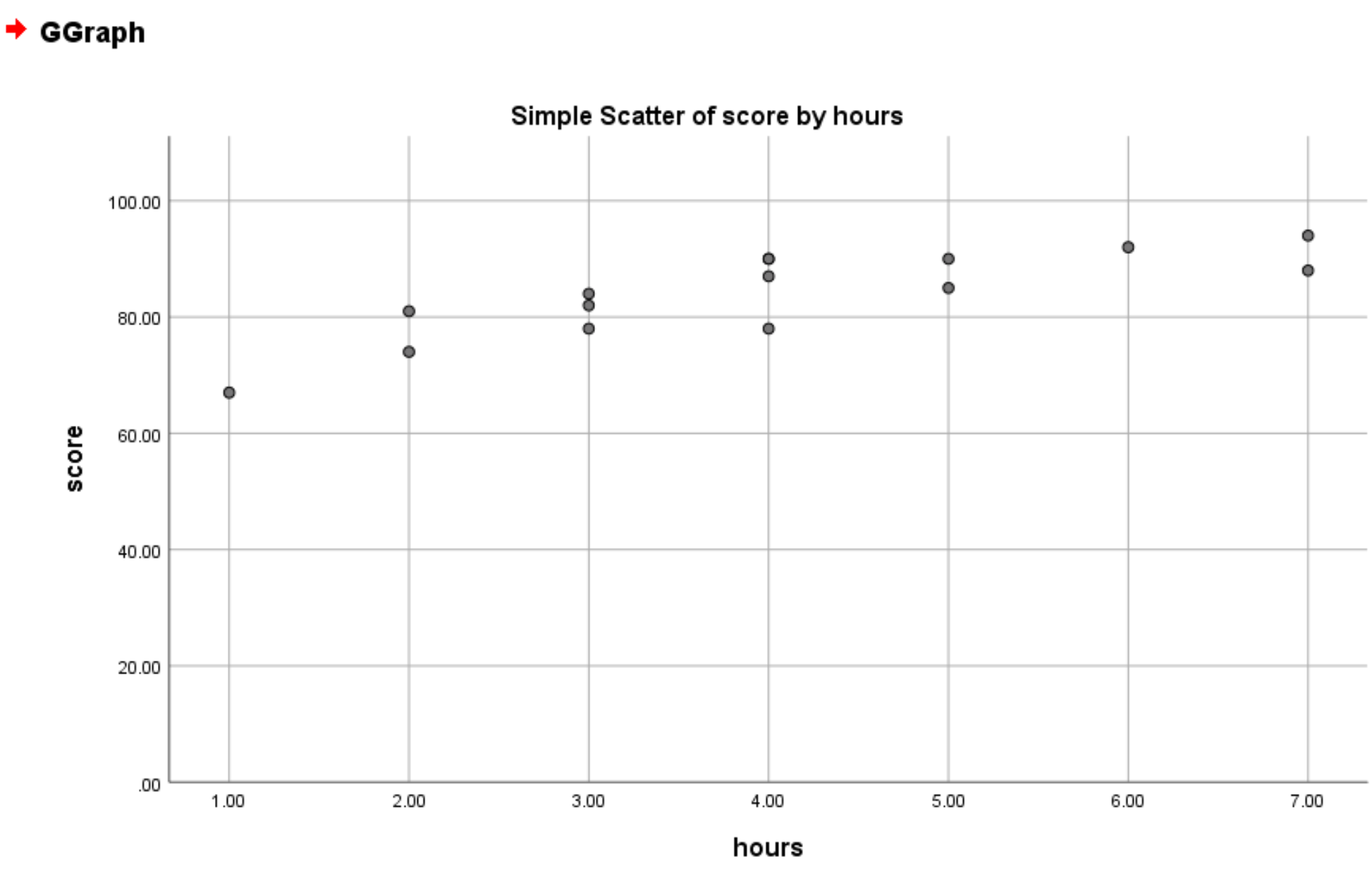
Диаграмма рассеяния с линией регрессии
Мы также можем создать диаграмму рассеяния с линией наилучшего соответствия, выбрав опцию « Простое рассеяние с подходящей линией» в окне «Построитель диаграмм»:
Как только мы нажмем «ОК» , появится диаграмма рассеяния с линией наилучшего соответствия:
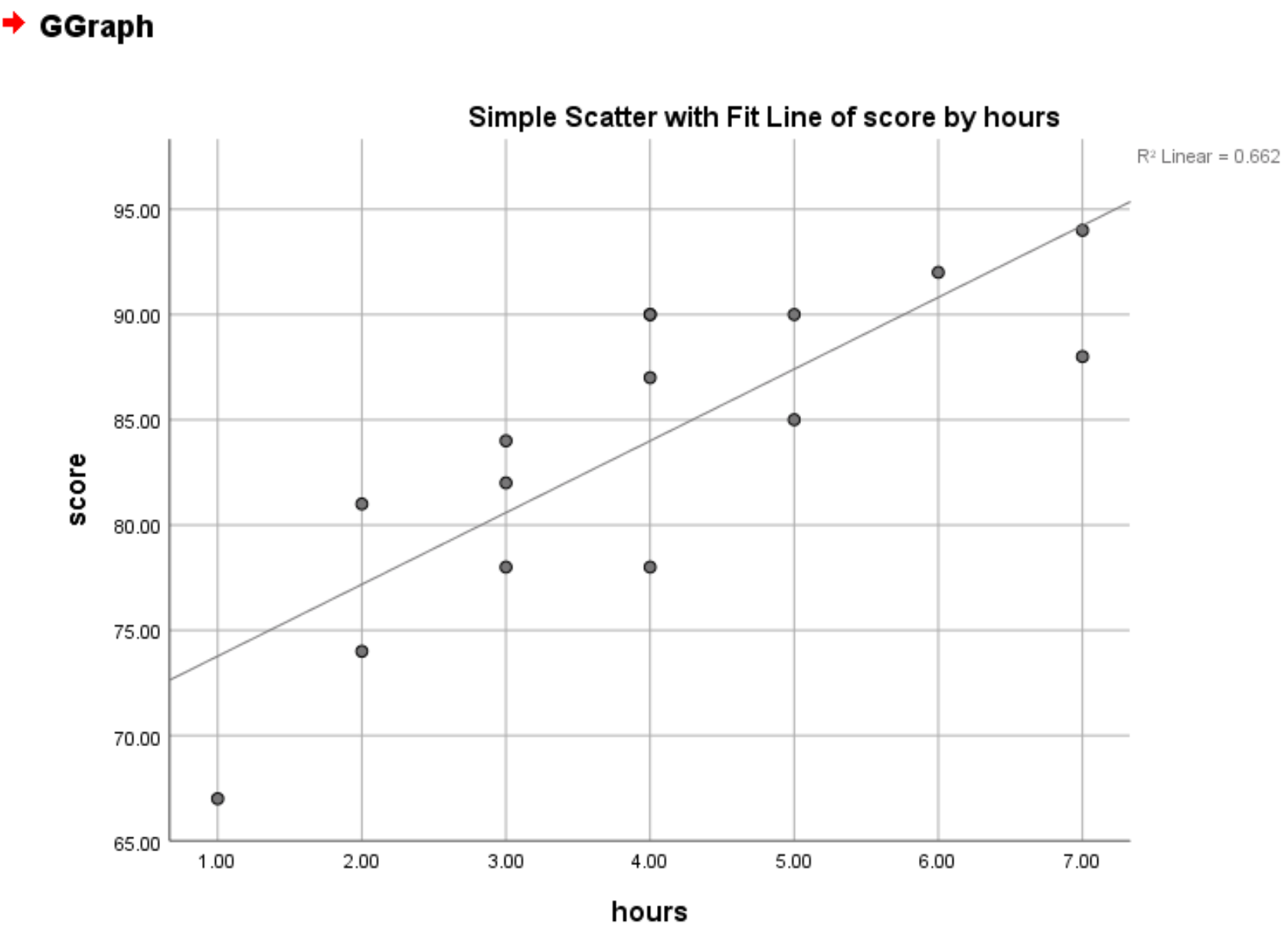
Значение R 2 также отображается в правом верхнем углу графика. Это представляет собой процент изменения переменной ответа, который можно объяснить переменной-предиктором. В данном случае это означает, что 66,2% разницы в экзаменационных баллах можно объяснить количеством часов, потраченных на учебу.
Кластеризованное облако точек
Предположим, в нашем наборе данных также есть категориальная переменная, например пол:
В этом случае мы могли бы создать диаграмму рассеяния учебных часов и результатов экзаменов, сгруппированных по полу.
Для этого мы можем снова открыть «Построитель диаграмм» и выбрать «Группированное рассеяние» в качестве типа диаграммы. Опять же, мы разместим переменную часов на оси X, а счет — на оси Y, но на этот раз мы добавим пол в качестве переменной в разделе «Задать цвет» :
Как только мы нажмем «ОК» , появится следующая сгруппированная диаграмма рассеяния:
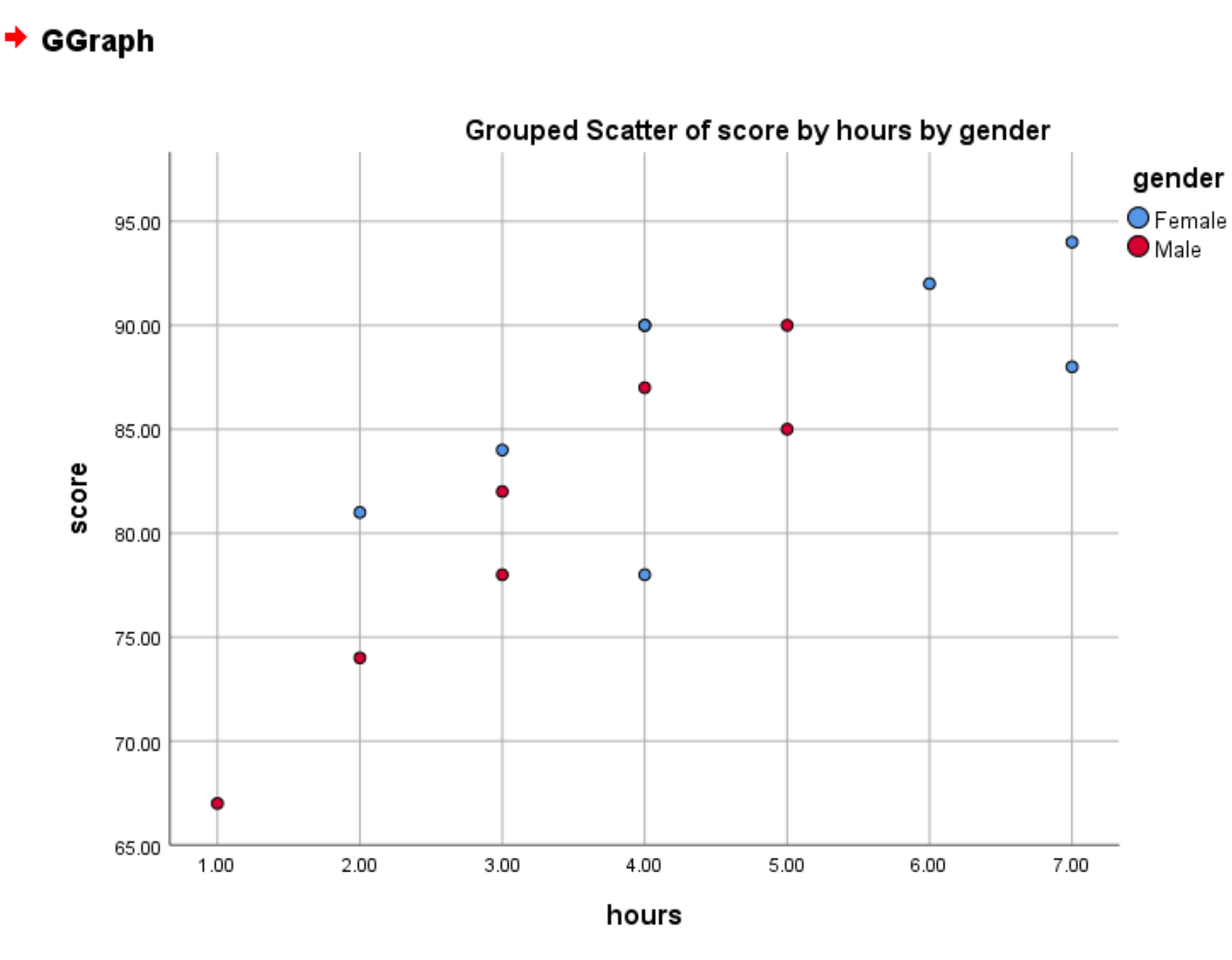
Красные круги представляют мужчин, а синие круги — женщин.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше