Как выполнить одномерный анализ в r (с примерами)
Термин одномерный анализ относится к анализу одной переменной. Вы можете это запомнить, потому что приставка «уни» означает «один».
Существует три распространенных способа выполнения одномерного анализа переменной:
1. Сводная статистика – измеряет центр и распределение значений.
2. Таблица частот – описывает, как часто появляются разные значения.
3. Диаграммы — используются для визуализации распределения значений.
В этом руководстве представлен пример выполнения одномерного анализа для следующей переменной:
#create variable with 15 values
x <- c(1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2)
Сводные статистические данные
Мы можем использовать следующий синтаксис для расчета различной сводной статистики для нашей переменной:
#find means mean(x) [1] 5.706667 #find median median(x) [1] 5 #find range max(x) - min(x) [1] 13.2 #find interquartile range (spread of middle 50% of values) IQR(x) [1] 3.45 #find standard deviation sd(x) [1] 3.858287
Таблица частот
Мы можем использовать следующий синтаксис для создания таблицы частот для нашей переменной:
#produce frequency table
table(s)
1 2 3.5 4 5 6.5 7 7.4 8 13 14.2
2 1 1 3 2 1 1 1 1 1 1
Это говорит нам о том, что:
- Значение 1 появляется дважды
- Значение 2 появляется 1 раз
- Значение 3,5 появляется 1 раз
И так далее.
Графика
Мы можем создать коробчатую диаграмму , используя следующий синтаксис:
#produce boxplot
boxplot(x)
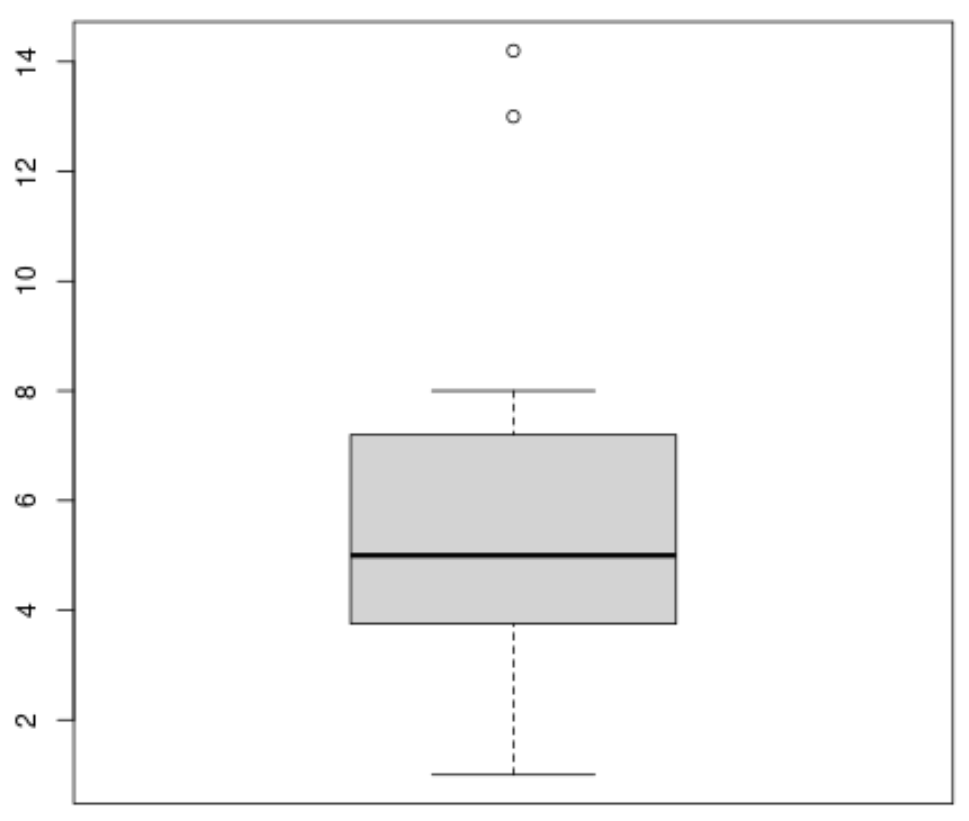
Мы можем создать гистограмму, используя следующий синтаксис:
#produce histogram
hist(x)
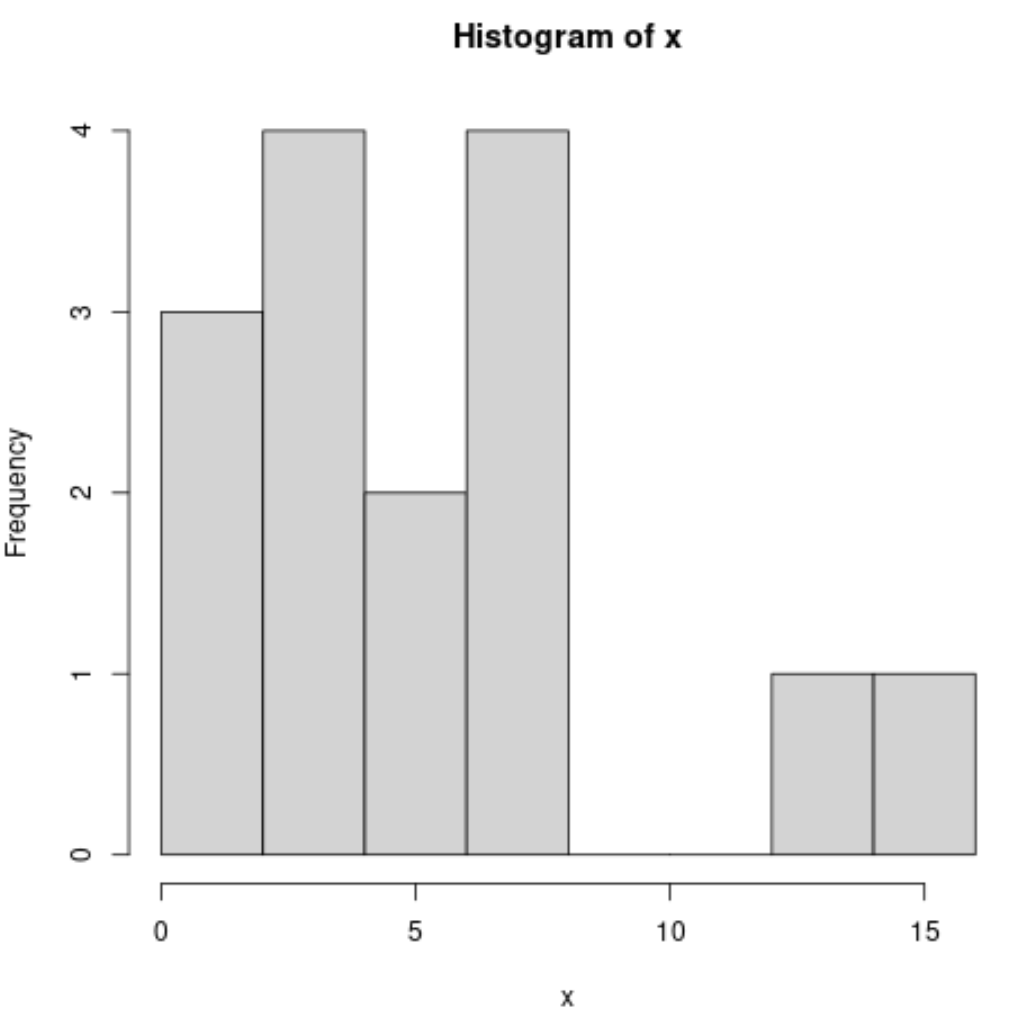
Мы можем построитькривую плотности , используя следующий синтаксис:
#produce density curve
plot(density(x))
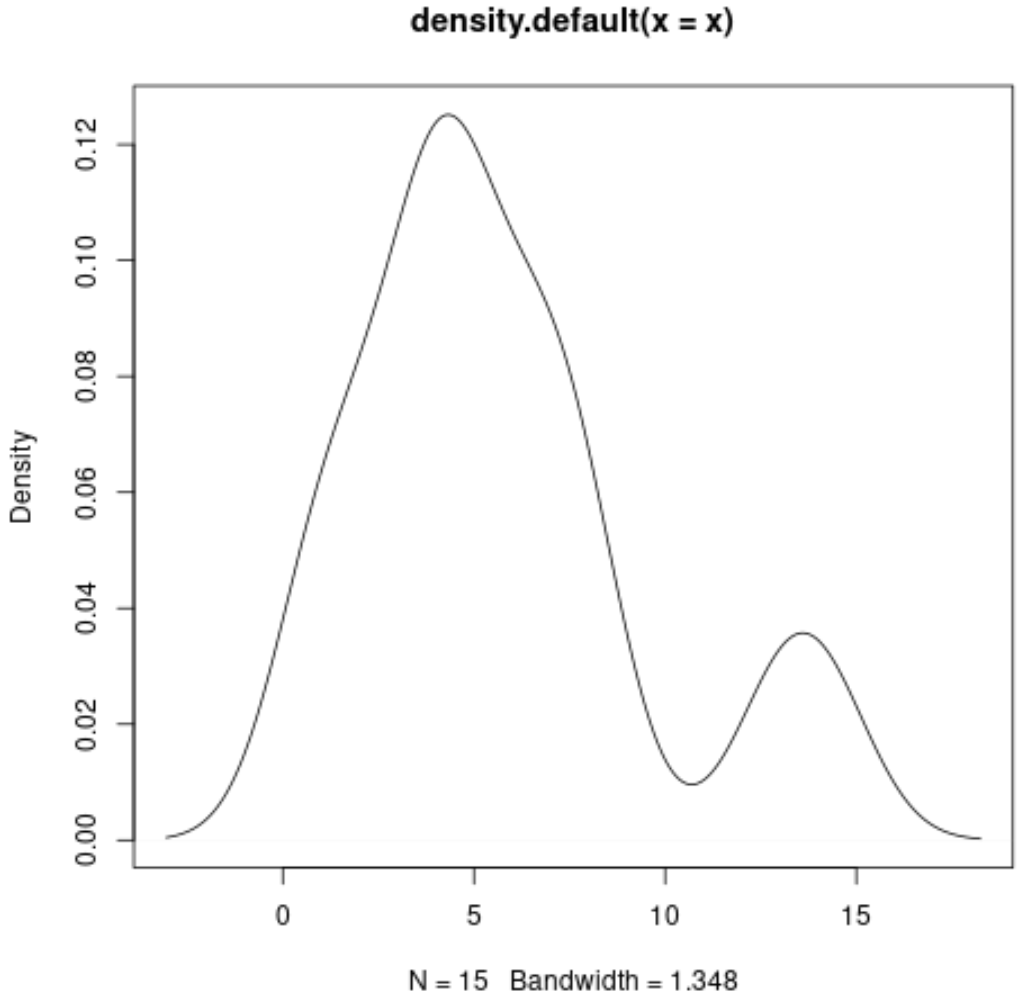
Каждый из этих графиков дает нам уникальный способ визуализировать распределение значений нашей переменной.
Дополнительные руководства по R вы можете найти на этой странице .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше