Как использовать распределение t в python
Распределение t — это распределение вероятностей, подобное нормальному распределению , за исключением того, что оно имеет более тяжелые «хвосты», чем нормальное распределение.
Другими словами, больше значений в распределении расположено на концах, чем в центре по сравнению с нормальным распределением:
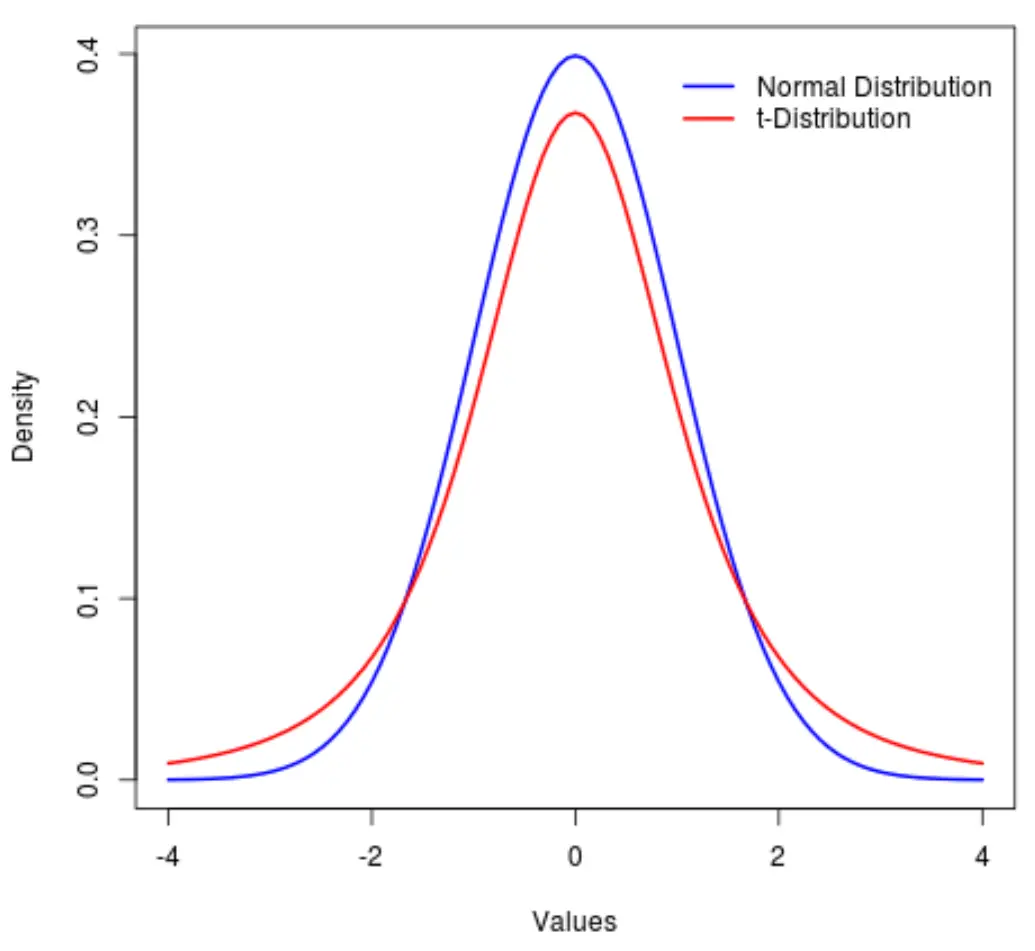
В этом руководстве объясняется, как использовать распределение t в Python.
Как создавать, чтобы распространять
Вы можете использовать функцию t.rvs(df, size) для генерации случайных значений из распределения с определенными степенями свободы и размером выборки:
from scipy. stats import t #generate random values from t distribution with df=6 and sample size=10 t. rvs (df= 6 , size= 10 ) array([-3.95799716, -0.01099963, -0.55953846, -1.53420055, -1.41775611, -0.45384974, -0.2767931, -0.40177789, -0.3602592, 0.38262431])
В результате получается таблица из 10 значений, следующих друг за другом согласно распределению с 6 степенями свободы.
Как рассчитать значения P, используя распределение t
Мы можем использовать функцию t.cdf(x, df, loc=0, Scale=1), чтобы найти значение p, связанное со статистикой t-теста.
Пример 1. Поиск одностороннего P-значения
Предположим, мы выполняем одностороннюю проверку гипотезы и получаем статистику теста -1,5 и степени свободы = 10 .
Мы можем использовать следующий синтаксис для расчета значения p, соответствующего этой тестовой статистике:
from scipy. stats import t #calculate p-value t. cdf (x=-1.5, df=10) 0.08225366322272008
Одностороннее значение p, соответствующее тестовой статистике -1,5 с 10 степенями свободы, составляет 0,0822 .
Пример 2. Поиск двустороннего P-значения
Предположим, мы выполняем двустороннюю проверку гипотезы и получаем статистику теста 2,14 и степени свободы = 20 .
Мы можем использовать следующий синтаксис для расчета значения p, соответствующего этой тестовой статистике:
from scipy. stats import t #calculate p-value (1 - t. cdf (x=2.14, df=20)) * 2 0.04486555082549959
Двустороннее значение p, соответствующее тестовой статистике 2,14 с 20 степенями свободы, составляет 0,0448 .
Примечание . Вы можете проверить эти ответы с помощью калькулятора обратного t-распределения.
Как отследить распространение
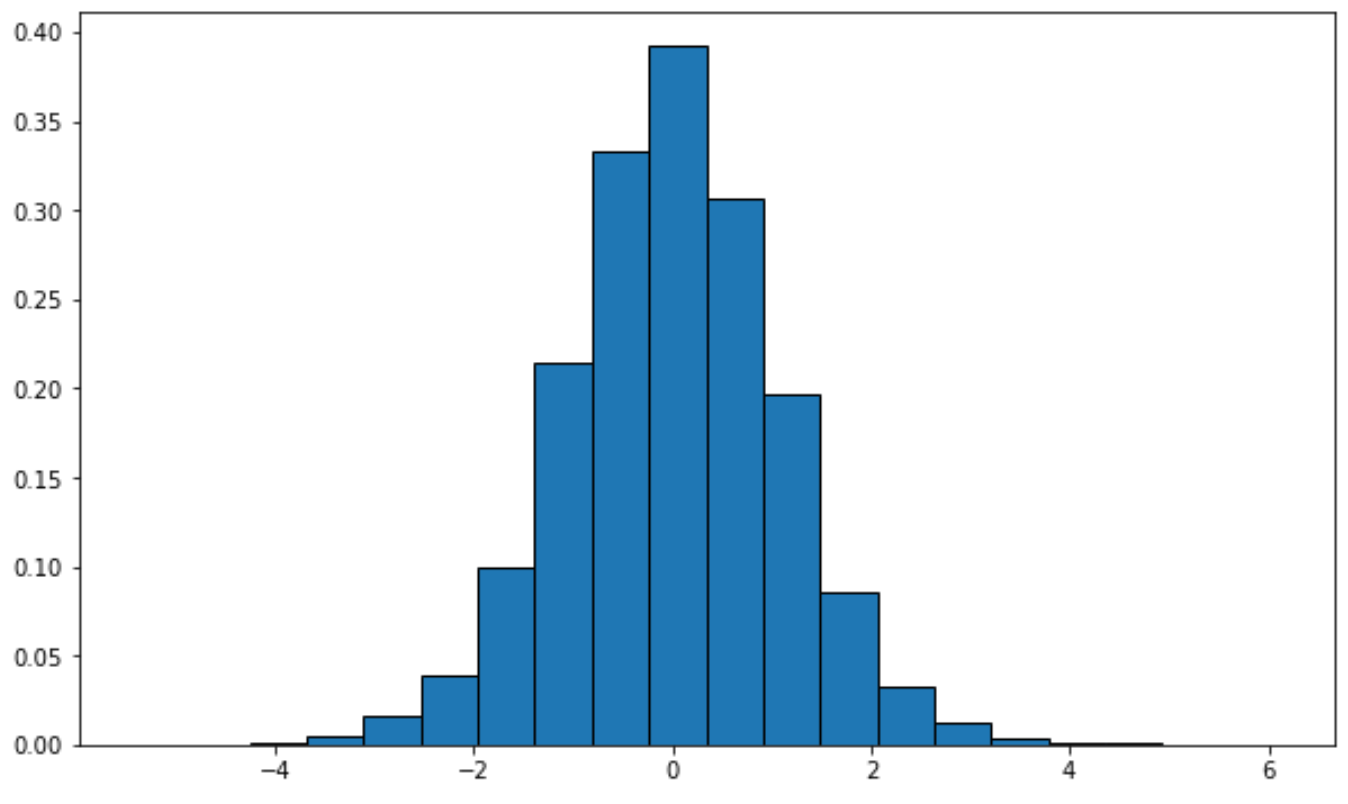
Вы можете использовать следующий синтаксис для построения распределения с определенными степенями свободы:
from scipy. stats import t import matplotlib. pyplot as plt #generate t distribution with sample size 10000 x = t. rvs (df= 12 , size= 10000 ) #create plot of t distribution plt. hist (x, density= True , edgecolor=' black ', bins= 20 )
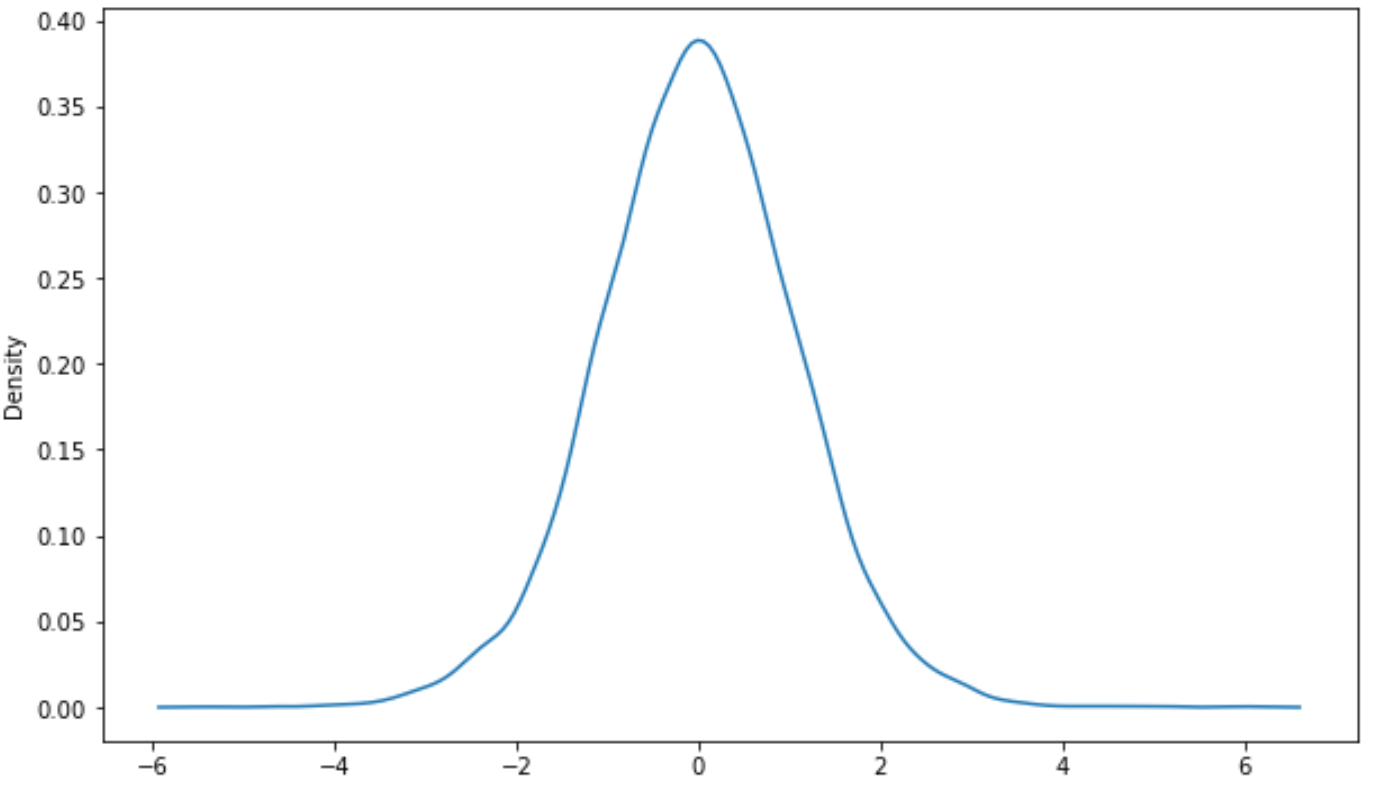
Альтернативно вы можете создатькривую плотности , используя пакет визуализации seaborn :
import seaborn as sns #create density curve sns. kdeplot (x)
Дополнительные ресурсы
Следующие руководства содержат дополнительную информацию о распространении:
Нормальное распределение и t-распределение: в чем разница?
Калькулятор обратного t-распределения
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше