Как рассчитать выборочные распределения в r
Выборочное распределение — это распределение вероятностей определенной статистики , основанное на множестве случайных выборок из одной совокупности.
В этом руководстве объясняется, как сделать следующее с выборочными распределениями в R:
- Создайте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности распределения выборки.
Создайте выборочное распределение в R
Следующий код показывает, как создать выборочное распределение в R:
#make this example reproducible
set.seed(0)
#define number of samples
n = 10000
#create empty vector of length n
sample_means = rep (NA, n)
#fill empty vector with means
for (i in 1:n){
sample_means[i] = mean ( rnorm (20, mean=5.3, sd=9))
}
#view first six sample means
head(sample_means)
[1] 5.283992 6.304845 4.259583 3.915274 7.756386 4.532656
В этом примере мы использовали функцию rnorm() для расчета среднего значения 10 000 выборок, в которых каждый размер выборки составлял 20 и был сгенерирован на основе нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Мы видим, что в первом образце среднее значение было 5,283992, во втором образце — 6,304845 и так далее.
Визуализация распределения выборки
Следующий код показывает, как создать простую гистограмму для визуализации распределения выборки:
#create histogram to visualize the sampling distribution
hist(sample_means, main = "", xlab = " Sample Means ", col = " steelblue ")
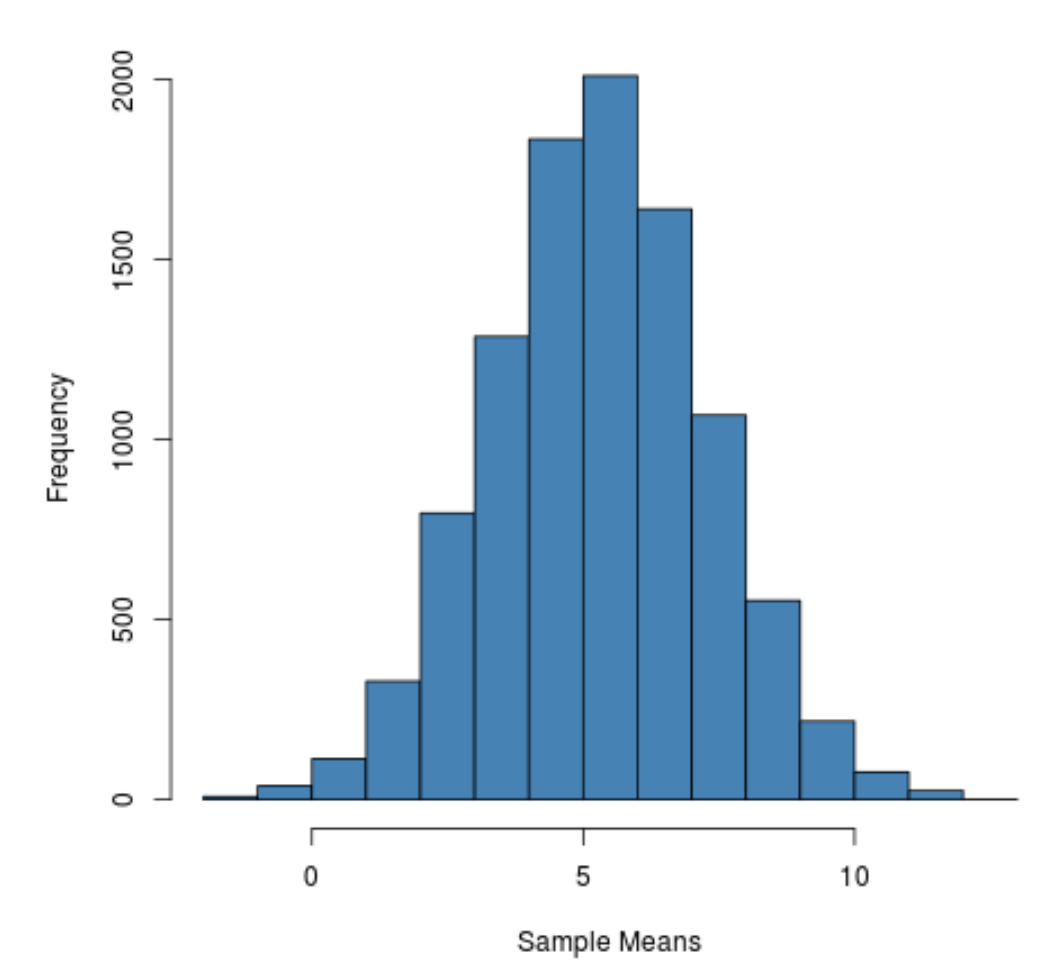
Видно, что распределение выборки имеет колоколообразную форму с пиком около значения 5.
Однако из хвостов распределения мы видим, что некоторые выборки имели средние значения больше 10, а другие — меньше 0.
Найдите среднее и стандартное отклонение
Следующий код показывает, как вычислить среднее и стандартное отклонение выборочного распределения:
#mean of sampling distribution
mean(sample_means)
[1] 5.287195
#standard deviation of sampling distribution
sd(sample_means)
[1] 2.00224
Теоретически среднее значение выборочного распределения должно составлять 5,3. Мы видим, что фактическое среднее значение выборки в этом примере составляет 5,287195 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что составит 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,00224 , что близко к 2,012.
Вычислить вероятности
Следующий код показывает, как вычислить вероятность получения определенного значения для выборочного среднего значения, учитывая среднее значение генеральной совокупности, стандартное отклонение генеральной совокупности и размер выборки.
#calculate probability that sample mean is less than or equal to 6
sum(sample_means <= 6) / length(sample_means)
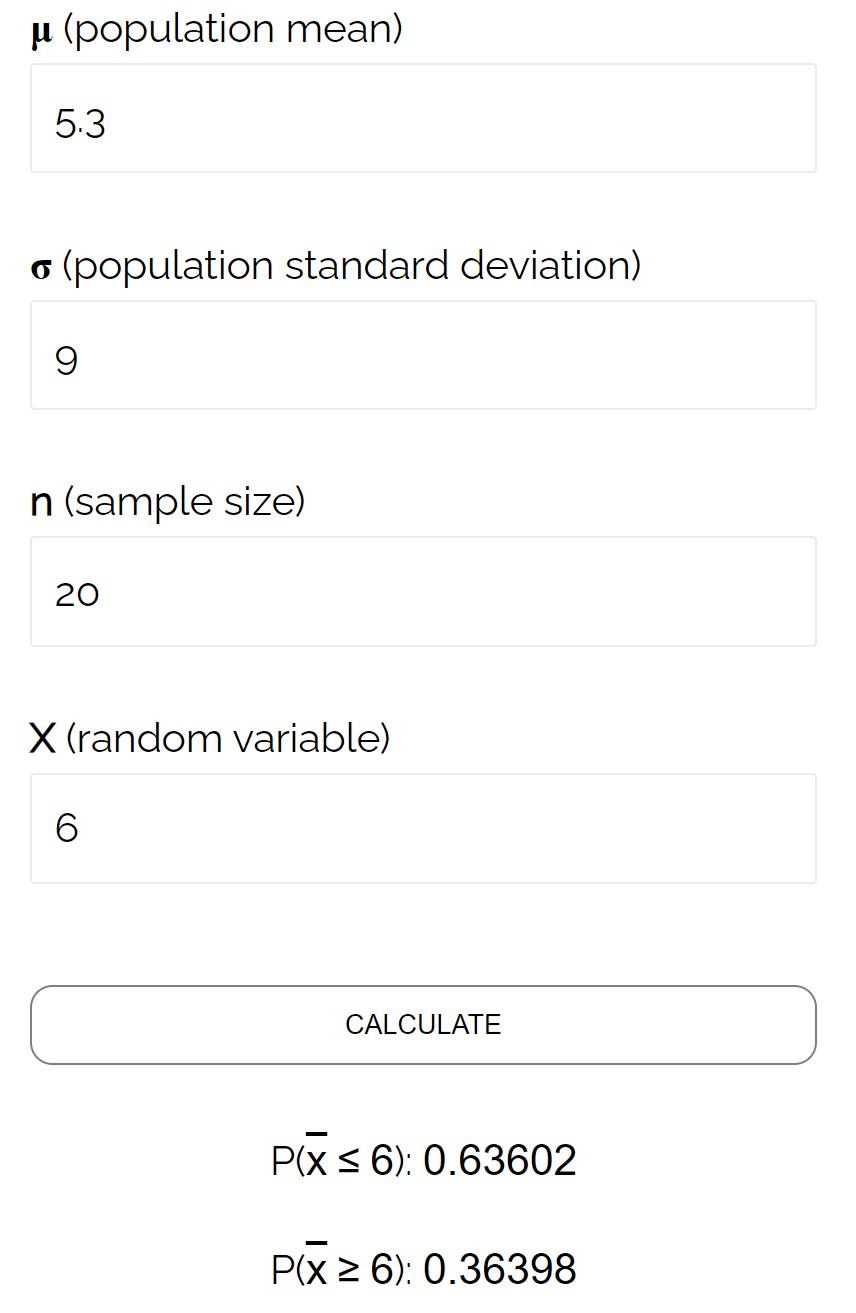
В этом конкретном примере мы находим вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9, а размер выборки из 20 человек равен 0,6417 .
Это очень близко к вероятности, рассчитанной с помощью калькулятора выборочного распределения :
Полный код
Полный код R, используемый в этом примере, показан ниже:
#make this example reproducible
set.seed(0)
#define number of samples
n = 10000
#create empty vector of length n
sample_means = rep (NA, n)
#fill empty vector with means
for (i in 1:n){
sample_means[i] = mean ( rnorm (20, mean=5.3, sd=9))
}
#view first six sample means
head(sample_means)
#create histogram to visualize the sampling distribution
hist(sample_means, main = "", xlab = " Sample Means ", col = " steelblue ")
#mean of sampling distribution
mean(sample_means)
#standard deviation of sampling distribution
sd(sample_means)
#calculate probability that sample mean is less than or equal to 6
sum(sample_means <= 6) / length(sample_means)
Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше