Что такое ошибка прогноза в статистике? (определение и примеры)
В статистике ошибка прогнозирования относится к разнице между значениями, предсказанными определенными моделями, и фактическими значениями.
Ошибка прогноза часто используется в двух контекстах:
1. Линейная регрессия: используется для прогнозирования значения переменной непрерывного отклика.
Обычно мы измеряем ошибку прогнозирования модели линейной регрессии с помощью метрики, известной как RMSE , что означает среднеквадратическую ошибку.
Он рассчитывается следующим образом:
RMSE = √ Σ(ŷ i – y i ) 2 / n
Золото:
- Σ — символ, означающий «сумма».
- ŷ i — прогнозируемое значение для i- го наблюдения
- y i — наблюдаемое значение для i-го наблюдения
- n — размер выборки
2. Логистическая регрессия: используется для прогнозирования значения переменной двоичного ответа.
Распространенный способ измерения ошибки прогнозирования модели логистической регрессии — использовать показатель, известный как общая частота ошибок классификации.
Он рассчитывается следующим образом:
Общий коэффициент ошибочной классификации = (количество неверных прогнозов / общее количество прогнозов)
Чем ниже значение коэффициента ошибочной классификации, тем лучше модель способна предсказать результаты переменной отклика.
В следующих примерах показано, как на практике рассчитать ошибку прогнозирования для модели линейной регрессии и модели логистической регрессии.
Пример 1. Вычисление ошибки прогнозирования в линейной регрессии
Предположим, мы используем регрессионную модель, чтобы предсказать, сколько очков наберут 10 игроков в баскетбольном матче.
В следующей таблице показаны очки, предсказанные моделью, в сравнении с фактическими очками, набранными игроками:
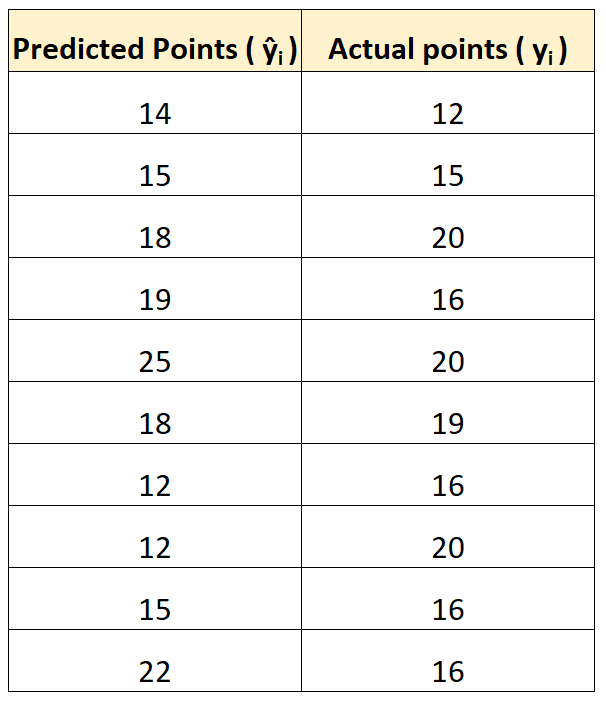
Мы могли бы рассчитать среднеквадратическую ошибку (RMSE) следующим образом:
- RMSE = √ Σ(ŷ i – y i ) 2 / n
- СКО = √(((14-12) 2 +(15-15) 2 +(18-20) 2 +(19-16) 2 +(25-20) 2 +(18-19) 2 +(12- 16) 2 +(12-20) 2 +(15-16) 2 +(22-16) 2 ) / 10)
- СКО = 4
Среднеквадратическая ошибка равна 4. Это говорит нам о том, что среднее отклонение между прогнозируемыми и фактически набранными баллами равно 4.
Связанный: Что считается хорошим значением RMSE?
Пример 2: Вычисление ошибки прогнозирования в логистической регрессии
Предположим, мы используем модель логистической регрессии, чтобы предсказать, будут ли 10 баскетболистов колледжа выбраны в НБА.
В следующей таблице показаны прогнозируемые результаты для каждого игрока в сравнении с фактическими результатами (1 = выбран, 0 = не выбран):
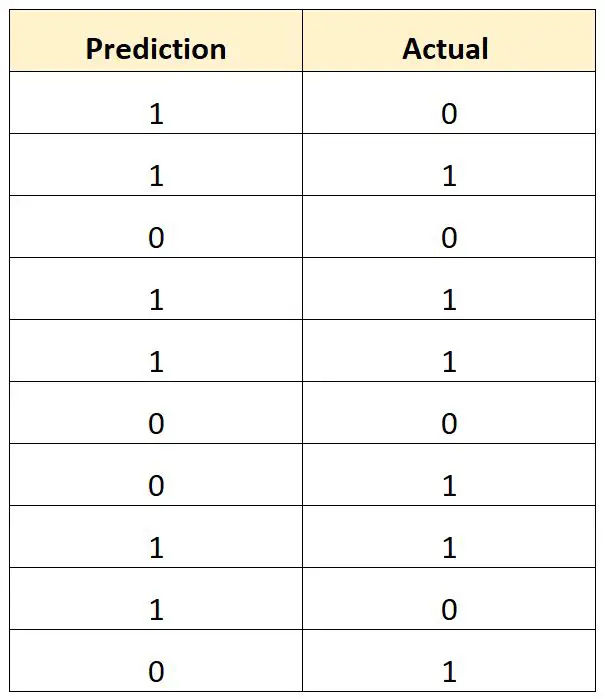
Мы могли бы рассчитать общий уровень ошибочной классификации следующим образом:
- Общий коэффициент ошибочной классификации = (количество неверных прогнозов / общее количество прогнозов)
- Общая частота ошибок классификации = 4/10.
- Общий уровень ошибочной классификации = 40%
Общая доля ошибок классификации составляет 40% .
Это значение довольно велико и указывает на то, что модель не очень хорошо прогнозирует, будет ли игрок выбран на драфте или нет.
Дополнительные ресурсы
Следующие учебные пособия знакомят с различными типами методов регрессии:
Введение в простую линейную регрессию
Введение в множественную линейную регрессию
Введение в логистическую регрессию
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше