Статистические формулы
Здесь вы найдете основные статистические формулы. Мы также оставляем вам ссылку на наши статьи, в которых вы можете увидеть примеры применения каждой статистической формулы и, кроме того, вы можете воспользоваться онлайн-калькулятором, чтобы не выполнять расчеты и узнать результат формулы напрямую.
Формулы для статистических показателей центральной тенденции
Половина
Чтобы вычислить среднее значение, сложите все значения, а затем разделите их на общее количество данных. Таким образом, формула среднего значения выглядит следующим образом:

В статистике среднее значение также известно как среднее арифметическое или среднее .
медиана
Медиана — это среднее значение всех данных, упорядоченных от наименьшего к наибольшему. Другими словами, медиана делит упорядоченный набор данных на две равные части.
Расчет медианы зависит от того, является ли общее количество данных четным или нечетным:
- Если общее количество данных нечетное , медианой будет значение, попадающее прямо в середину данных. То есть значение, которое находится в позиции (n+1)/2 отсортированных данных.
- Если общее количество точек данных четное , медиана будет средним значением двух точек данных, расположенных в центре. То есть среднее арифметическое значений, которые находятся в позициях n/2 и n/2+1 упорядоченных данных.


Золото

— общее количество данных в выборке, а символ Me обозначает медиану.
Мода
В статистике мода — это значение в наборе данных, имеющее наибольшую абсолютную частоту, то есть мода — это наиболее повторяющееся значение в наборе данных.
Таким образом, не существует конкретной формулы для режима, но для расчета режима набора статистических данных просто подсчитайте, сколько раз каждый элемент данных появляется в выборке, и наиболее повторяющиеся данные будут режимом.
Этот режим также можно назвать статистическим режимом или модальным значением .
Формулы статистических мер дисперсии
Среднеквадратичное отклонение
Стандартное отклонение, также называемое стандартным отклонением, равно квадратному корню из суммы квадратов отклонений ряда данных, разделенной на общее количество наблюдений.
Следовательно, формула стандартного отклонения имеет вид:

Дисперсия
Дисперсия равна сумме квадратов остатков по общему числу наблюдений. Таким образом, формула для этого статистического показателя выглядит следующим образом:

Золото:
-

— случайная величина, для которой вы хотите вычислить дисперсию.
-

значение данных

.
-
общее количество наблюдений.
-

среднее значение случайной величины
.
Коэффициент вариации
В статистике коэффициент вариации — это мера дисперсии, используемая для определения дисперсии набора данных относительно его среднего значения. Коэффициент вариации рассчитывается путем деления стандартного отклонения данных на их среднее значение, а затем умножения на 100, чтобы выразить значение в процентах.

Аккуратный
Статистический диапазон — это мера дисперсии, которая указывает на разницу между максимальным и минимальным значением данных в выборке. Следовательно, чтобы рассчитать размер генеральной совокупности или статистической выборки, максимальное значение необходимо вычесть из минимального значения.

Межквартильный размах
Межквартильный размах , также называемый межквартильным размахом , является мерой статистической дисперсии, которая указывает на разницу между третьим и первым квартилем.
Следовательно, чтобы вычислить межквартильный размах набора статистических данных, необходимо сначала найти третий и первый квартиль, а затем вычесть их.

средняя разница
Среднее отклонение , также называемое средним абсолютным отклонением , представляет собой среднее значение абсолютных отклонений. Таким образом, среднее отклонение равно сумме отклонений каждого элемента данных от среднего арифметического, деленной на общее количество элементов данных.

Формулы для статистических измерений положения
квартили
В статистике квартили — это три значения, которые делят набор упорядоченных данных на четыре равные части. Таким образом, первый, второй и третий квартили представляют соответственно 25%, 50% и 75% всех статистических данных.
Квартили обозначаются заглавной буквой Q и индексом квартиля, поэтому первый квартиль — это Q 1 , второй квартиль — Q 2 и третий квартиль — Q 3 .
Формула квартиля :

Обратите внимание: эта формула сообщает нам положение квартиля, а не его значение. Квартилем будут данные, расположенные в позиции, полученной по формуле.
Однако иногда результат этой формулы даст нам десятичное число. Поэтому мы должны различать два случая в зависимости от того, является ли результат десятичным числом или нет:
- Если результатом формулы является число без десятичной части , квартилем являются данные, находящиеся в позиции, указанной в формуле выше.
- Если результатом формулы является число с десятичной частью , значение квартиля рассчитывается по следующей формуле:

Где x i и x i+1 — номера позиций, между которыми находится число, полученное по первой формуле, а d — десятичная часть числа, полученного по первой формуле.
децили
В статистике децили — это девять величин, которые делят набор упорядоченных данных на десять равных частей. Таким образом, первый, второй, третий… дециль представляет 10%, 20%, 30%… выборки или совокупности.
Децили обозначаются заглавной буквой Д и децильным индексом, то есть первый дециль — Д 1 , второй дециль — Д 2 , третий дециль — Д 3 и т. д.
Децильная формула выглядит следующим образом:

Обратите внимание: эта формула сообщает нам положение дециля, а не его значение. Децилем будут данные, расположенные в позиции, полученной по формуле.
Однако иногда результат этой формулы дает нам десятичное число, поэтому мы должны различать два случая в зависимости от того, является ли результат десятичным числом или нет:
- Если результатом формулы является число без десятичной части , децилем являются данные, расположенные в позиции, указанной в формуле выше.
- Если результатом формулы является число с десятичной частью , значение дециля рассчитывается по следующей формуле:

Где x i и x i+1 — номера позиций, между которыми находится число, полученное по первой формуле, а d — десятичная часть числа, полученного по первой формуле.
процентили
В статистике процентили — это значения, делящие набор упорядоченных данных на сто равных частей. Итак, процентиль указывает значение, ниже которого падает процент набора данных.
Процентили обозначаются заглавной буквой P и индексом процентиля, то есть первый процентиль — P 1 , 40-й процентиль — P 40 , 79-й процентиль — P 79 и т. д.
Формула процентиля :

Обратите внимание: эта формула сообщает нам положение процентиля, но не его значение. Процентилем будут данные, расположенные в позиции, полученной по формуле.
Однако иногда результат этой формулы дает нам десятичное число, поэтому мы должны различать два случая в зависимости от того, является ли результат десятичным числом или нет:
- Если результатом формулы является число без десятичной части , процентиль соответствует данным, которые находятся в позиции, указанной формулой выше.
- Если результатом формулы является число с десятичной частью , точное значение процентиля рассчитывается по следующей формуле:

Где x i и x i+1 — номера позиций, между которыми находится число, полученное по первой формуле, а d — десятичная часть числа, полученного по первой формуле.
Статистические формулы измерения формы
коэффициент асимметрии
Коэффициент асимметрии или индекс асимметрии — это статистический коэффициент, используемый для определения асимметрии распределения. Итак, рассчитав коэффициент асимметрии, можно узнать тип асимметрии распределения без необходимости его графического представления.
Формула коэффициента асимметрии выглядит следующим образом:

Аналогично, для расчета коэффициента асимметрии Фишера можно использовать любую из следующих двух формул:

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\cdot \overline{x}\cdot \sigma^2 - \overline{x}^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-b58aae86c4d7f8fec18ef689ec08c5db_l3.png "Rendered by QuickLaTeX.com")
Золото

это математическое ожидание,

среднее арифметическое,

стандартное отклонение и
общее количество данных.
коэффициент эксцесса
Куртозис, также называемый резкостью, показывает, насколько сконцентрировано распределение вокруг своего среднего значения. Другими словами, эксцесс показывает, является ли распределение крутым или пологим. В частности, чем больше эксцесс распределения, тем оно круче (или острее).
Формула коэффициента эксцесса выглядит следующим образом:

Золото
значение, соответствующее наблюдению
,
среднее арифметическое,
стандартное отклонение и
общее количество данных.
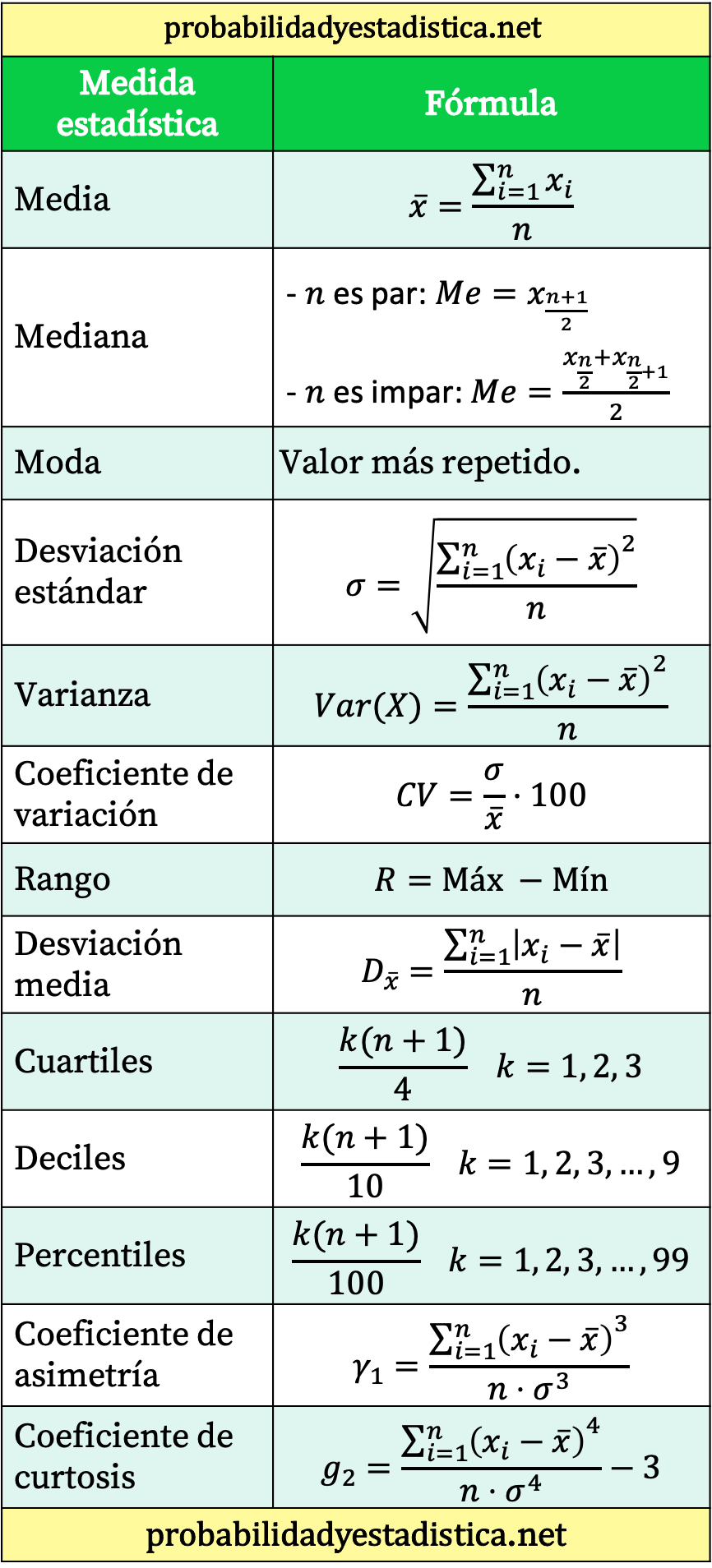
Сводная таблица всех статистических формул
Наконец, мы оставляем вам таблицу, в которой суммированы основные статистические формулы.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше