Простое введение в ускорение машинного обучения
Большинство алгоритмов контролируемого машинного обучения основаны на использовании одной прогнозирующей модели, такой как линейная регрессия , логистическая регрессия , гребневая регрессия и т. д.
Однако такие методы, как пакетирование и случайный лес, создают множество различных моделей на основе повторяющихся выборок исходного набора данных. Прогнозы на основе новых данных делаются путем усреднения прогнозов, сделанных отдельными моделями.
Эти методы, как правило, обеспечивают повышение точности прогнозирования по сравнению с методами, которые используют только одну прогнозирующую модель, поскольку они используют следующий процесс:
- Во-первых, постройте отдельные модели с высокой дисперсией и низким смещением (например, глубоко развитые деревья решений ).
- Затем усредните прогнозы, сделанные отдельными моделями, чтобы уменьшить дисперсию.
Другой метод, который, как правило, обеспечивает еще большее повышение точности прогнозирования, известен как бустинг .
Что такое бустирование?
Повышение — это метод, который можно использовать с любым типом модели, но чаще всего он используется с деревьями решений.
Идея повышения проста:
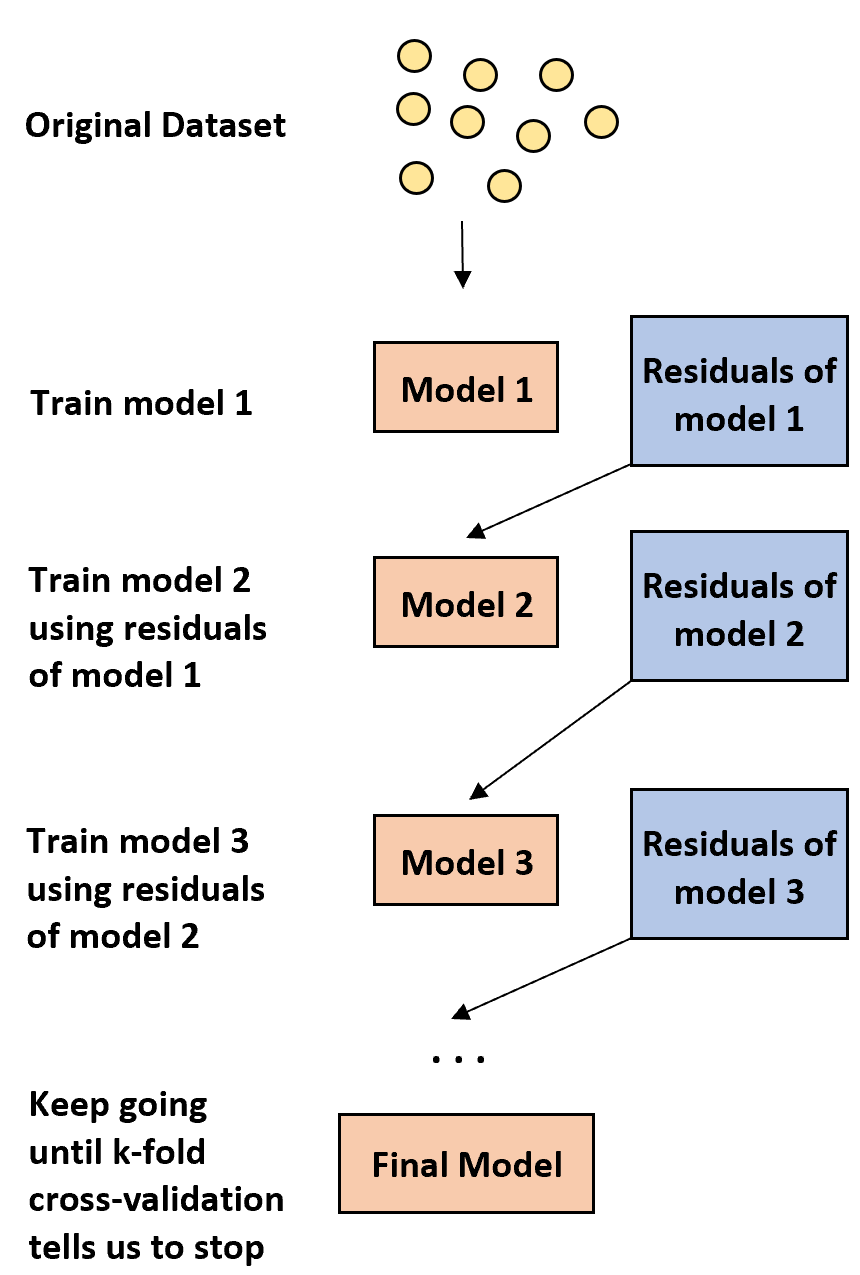
1. Сначала постройте слабую модель.
- «Слабая» модель — это модель, частота ошибок которой лишь немного выше, чем случайная оценка.
- На практике это обычно дерево решений, состоящее только из одного или двух подразделений.
2. Затем постройте еще одну слабую модель на основе остатков предыдущей модели.
- На практике мы используем остатки предыдущей модели (т. е. ошибки наших прогнозов), чтобы адаптировать новую модель, которая немного улучшает общую частоту ошибок.
3. Продолжайте этот процесс до тех пор, пока k-кратная перекрестная проверка не скажет нам остановиться.
- На практике мы используем перекрестную проверку в k-кратном размере , чтобы определить, когда нам следует прекратить разработку усиленной модели.
Используя этот метод, мы можем начать со слабой модели и продолжать «улучшать» ее производительность, последовательно строя новые деревья, улучшающие производительность предыдущего дерева, пока не получим окончательную модель с высокой точностью прогнозирования.
Почему повышение работает?
Оказывается, повышение способно создавать одни из самых мощных моделей во всем машинном обучении.
Во многих отраслях усиленные модели используются в качестве эталонных моделей в производстве, поскольку они имеют тенденцию превосходить все другие модели.
Причина, по которой усиленные шаблоны работают так хорошо, сводится к пониманию простой идеи:
1. Во-первых, улучшенные модели создают слабое дерево решений с низкой точностью прогнозирования. Говорят, что это дерево решений имеет низкую дисперсию и высокую предвзятость.
2. Поскольку улучшенные модели следуют процессу последовательного улучшения предыдущих деревьев решений, общая модель способна медленно уменьшать смещение на каждом этапе без значительного увеличения дисперсии.
3. Окончательно подобранная модель имеет тенденцию иметь достаточно низкую систематическую ошибку и дисперсию, что приводит к модели, способной обеспечить низкий уровень ошибок при тестировании на новых данных.
Плюсы и минусы буста
Очевидным преимуществом бустинга является то, что он способен создавать модели с высокой точностью прогнозирования по сравнению почти со всеми другими типами моделей.
Потенциальным недостатком является то, что подобранную улучшенную модель очень трудно интерпретировать. Хотя он может предложить огромные возможности по прогнозированию значений отклика новых данных, трудно объяснить точный процесс, который он использует для достижения этой цели.
На практике большинство специалистов по данным и специалистам по машинному обучению создают улучшенные модели, поскольку хотят иметь возможность точно прогнозировать значения отклика новых данных. Таким образом, тот факт, что улучшенные модели трудно интерпретировать, обычно не является проблемой.
Бустер на практике
На практике для бустинга используется множество типов алгоритмов, в том числе:
В зависимости от размера вашего набора данных и вычислительной мощности вашего компьютера один из этих методов может быть предпочтительнее другого.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше