คู่มือฉบับสมบูรณ์: การออกแบบแฟกทอเรียล 2×3
การออกแบบแฟกทอเรียล 2 × 3 คือการออกแบบเชิงทดลองประเภทหนึ่งที่ช่วยให้นักวิจัยเข้าใจผลกระทบของตัวแปรอิสระสองตัวต่อตัวแปรตามตัวเดียว
ในการออกแบบประเภทนี้ ตัวแปรอิสระตัวหนึ่งมีสอง ระดับ และตัวแปรอิสระตัวอื่นมีสามระดับ
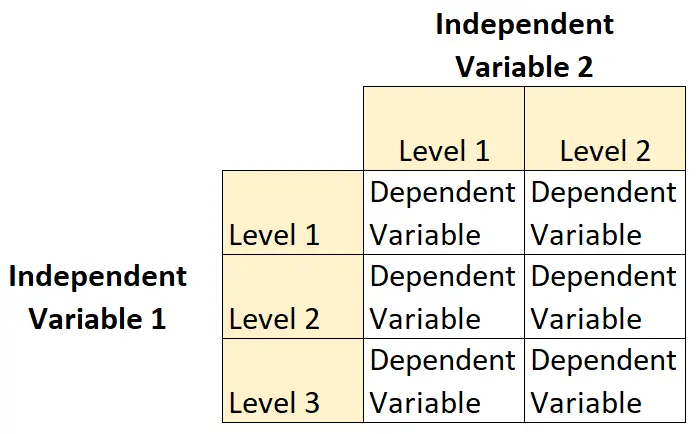
ตัวอย่างเช่น สมมติว่านักพฤกษศาสตร์ต้องการเข้าใจผลกระทบของแสงแดด (ต่ำ ปานกลาง หรือสูง) และความถี่ในการรดน้ำ (รายวันหรือรายสัปดาห์) ต่อการเจริญเติบโตของพืชบางชนิด
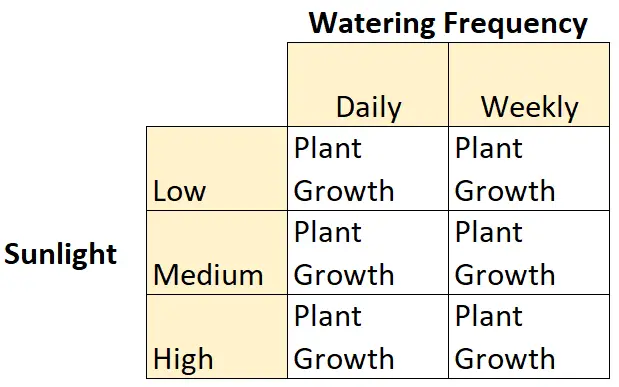
นี่คือตัวอย่างของการออกแบบแฟคทอเรียล 2 × 3 เนื่องจากมีตัวแปรอิสระสองตัว ตัวแปรหนึ่งมีสองระดับและอีกตัวหนึ่งมีสามระดับ:
- ตัวแปรอิสระ #1: แสงแดด
- ระดับ: ต่ำ, ปานกลาง, สูง
- ตัวแปรอิสระ #2: ความถี่ในการรดน้ำ
- ระดับ: รายวัน รายสัปดาห์
และมีตัวแปรตาม: การเจริญเติบโตของพืช
จุดประสงค์ของการออกแบบแฟกทอเรียล 2 × 3
การออกแบบแฟกทอเรียล 2×3 ช่วยให้คุณสามารถวิเคราะห์ผลกระทบต่อไปนี้:
ผลกระทบหลัก: สิ่งเหล่านี้คือผลกระทบที่ตัวแปรอิสระตัวเดียวมีต่อตัวแปรตาม
ตัวอย่างเช่น ในสถานการณ์ก่อนหน้านี้ เราสามารถวิเคราะห์ผลกระทบหลักต่อไปนี้:
- ผลกระทบหลักของแสงแดดต่อการเจริญเติบโตของพืช
- การเจริญเติบโตเฉลี่ยของพืชทุกชนิดที่ได้รับแสงแดดน้อย
- การเจริญเติบโตเฉลี่ยของพืชทุกชนิดที่ได้รับแสงแดดเฉลี่ย
- การเจริญเติบโตเฉลี่ยของพืชทุกชนิดที่ได้รับแสงแดดสูง
- ผลกระทบหลักของความถี่ในการรดน้ำต่อการเจริญเติบโตของพืช
- การเจริญเติบโตเฉลี่ยของพืชทุกชนิดที่รดน้ำทุกวัน
- การเจริญเติบโตโดยเฉลี่ยของพืชทุกชนิดที่รดน้ำในแต่ละสัปดาห์
ผลกระทบจากปฏิสัมพันธ์: เกิดขึ้นเมื่อผลกระทบของตัวแปรอิสระตัวหนึ่งต่อตัวแปรตามขึ้นอยู่กับระดับของตัวแปรอิสระตัวอื่น
ตัวอย่างเช่น ในสถานการณ์ก่อนหน้านี้ เราสามารถวิเคราะห์ผลกระทบจากการโต้ตอบต่อไปนี้:
- ผลของแสงแดดต่อการเจริญเติบโตของพืชขึ้นอยู่กับความถี่ในการรดน้ำหรือไม่?
- ผลของความถี่ในการรดน้ำต่อการเจริญเติบโตของพืชขึ้นอยู่กับแสงแดดหรือไม่?
วิธีการวิเคราะห์การออกแบบแฟคทอเรียล 2 × 3
เราสามารถใช้การวิเคราะห์ ความแปรปรวนแบบสองทาง เพื่อทดสอบอย่างเป็นทางการว่าตัวแปรอิสระมีความสัมพันธ์ที่มีนัยสำคัญทางสถิติกับตัวแปรตามหรือไม่
ตัวอย่างเช่น รหัสต่อไปนี้แสดงวิธีดำเนินการวิเคราะห์ความแปรปรวนแบบสองทางสำหรับสถานการณ์โรงงานสมมุติของเราใน R:
#make this example reproducible set. seeds (0) #createdata df <- data. frame (sunlight = rep(c(' Low ', ' Medium ', ' High '), each = 15, times = 2), water = rep(c(' Daily ', ' Weekly '), each = 45, times = 2), growth = c(rnorm(15, 9, 2), rnorm(15, 10, 3), rnorm(15, 13, 2), rnorm(15, 8, 3), rnorm(15, 10, 4), rnorm(15, 12, 3))) #fit the two-way ANOVA model model <- aov(growth ~ sunlight * water, data = df) #view the model output summary(model) Df Sum Sq Mean Sq F value Pr(>F) sunlight 2 602.3 301.15 50.811 <2e-16 *** water 1 39.6 39.62 6.685 0.0105 * sunlight:water 2 15.1 7.56 1.275 0.2819 Residuals 174 1031.3 5.93 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
วิธีการตีความผลลัพธ์ ANOVA มีดังนี้
- ค่า p ที่เกี่ยวข้องกับแสงแดดคือ <2e-16 เนื่องจากตัวเลขนี้น้อยกว่า 0.05 หมายความว่าการได้รับแสงแดดมีผลกระทบที่มีนัยสำคัญทางสถิติต่อการเจริญเติบโตของพืช
- ค่า p ที่เกี่ยวข้องกับน้ำคือ 0.0105 เนื่องจากตัวเลขนี้น้อยกว่า 0.05 หมายความว่าความถี่ในการรดน้ำก็มีผลกระทบที่มีนัยสำคัญทางสถิติต่อการเจริญเติบโตของพืชเช่นกัน
- ค่า p ของปฏิกิริยาระหว่างแสงแดดกับน้ำคือ 0.2819 เนื่องจากตัวเลขนี้ไม่น้อยกว่า 0.05 หมายความว่าไม่มีผลกระทบต่อปฏิสัมพันธ์ระหว่างแสงแดดและน้ำ
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้ให้ข้อมูลเพิ่มเติมเกี่ยวกับการออกแบบและการวิเคราะห์การทดลอง:
คู่มือฉบับสมบูรณ์: การออกแบบแฟกทอเรียล 2 × 2
ตัวแปรอิสระมีระดับเท่าใด
ตัวแปรอิสระหรือตัวแปรตาม
แฟกทอเรียล ANOVA คืออะไร?
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม