วิธีลบรายการที่ซ้ำกันใน sas (พร้อมตัวอย่าง)
คุณสามารถใช้ proc sort ใน SAS เพื่อลบแถวที่ซ้ำกันออกจากชุดข้อมูลได้อย่างรวดเร็ว
ขั้นตอนนี้ใช้ไวยากรณ์พื้นฐานต่อไปนี้:
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run;
โปรดทราบว่าอาร์กิวเมนต์ by ระบุว่าคอลัมน์ใดที่จะสแกนเมื่อลบรายการที่ซ้ำกัน
ตัวอย่างต่อไปนี้แสดงวิธีการลบรายการที่ซ้ำกันออกจากชุดข้อมูลต่อไปนี้ใน SAS:
/*create dataset*/
data original_data;
input team $position $points;
datalines ;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run ;
/*view dataset*/
proc print data = original_data;
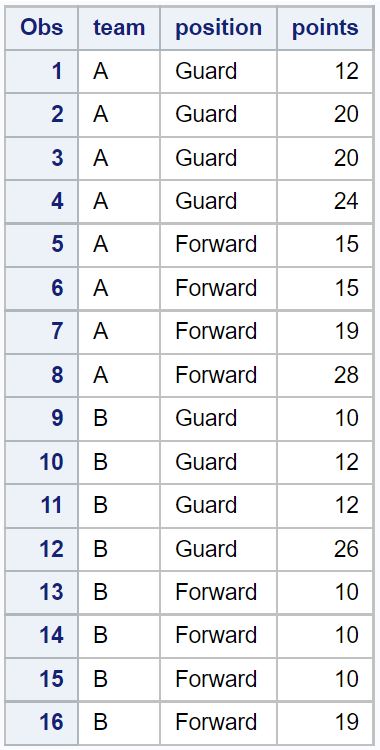
ตัวอย่างที่ 1: ลบรายการที่ซ้ำกันออกจากคอลัมน์ทั้งหมด
เราสามารถใช้โค้ดต่อไปนี้เพื่อลบแถวที่มีค่าซ้ำกันในทุกคอลัมน์ในชุดข้อมูล:
/*create dataset with no duplicate rows*/
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run ;
/*view dataset with no duplicate rows*/
proc print data =no_dups_data;
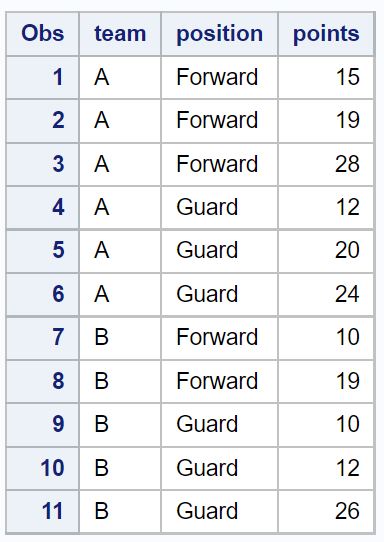
โปรดทราบว่ามีการลบแถวที่ซ้ำกันทั้งหมดห้าแถวออกจากชุดข้อมูลดั้งเดิม
ตัวอย่างที่ 2: ลบรายการที่ซ้ำกันออกจากคอลัมน์ที่ระบุ
เราสามารถใช้ by อาร์กิวเมนต์เพื่อระบุคอลัมน์ที่จะตรวจสอบเมื่อลบรายการที่ซ้ำกัน
ตัวอย่างเช่น โค้ดต่อไปนี้จะลบแถวที่มีค่าซ้ำกันในคอลัมน์ ทีม และ ตำแหน่ง :
/*create dataset with no duplicate rows in team and position columns*/
proc sort data =original_data out =no_dups_data nodupkey ;
by team position;
run ;
/*view dataset with no duplicate rows in team and position columns*/
proc print data =no_dups_data;
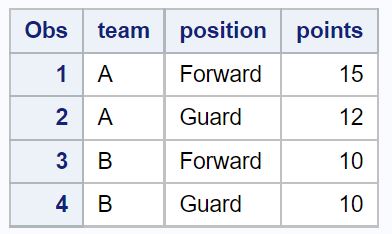
มีเพียงสี่แถวเท่านั้นที่ยังคงอยู่ในชุดข้อมูลหลังจากลบแถวที่มีค่าซ้ำกันในคอลัมน์ ทีม และ ตำแหน่ง
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีดำเนินการทั่วไปอื่นๆ ใน SAS:
วิธีทำให้ข้อมูลเป็นมาตรฐานใน SAS
วิธีระบุค่าผิดปกติใน SAS
วิธีใช้สรุปขั้นตอนใน SAS
วิธีสร้างตารางความถี่ใน SAS
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม