การกระจายตัวอย่างความแตกต่างในสัดส่วน
บทความนี้จะอธิบายว่าการกระจายตัวอย่างตามสัดส่วนแตกต่างกันอย่างไร และใช้เพื่ออะไรในสถิติ นอกจากนี้ยังมีการนำเสนอความแตกต่างในสูตรการกระจายตัวอย่างตามสัดส่วนและแบบฝึกหัดแก้ไขทีละขั้นตอนด้วย
การกระจายตัวอย่างความแตกต่างในสัดส่วนคืออะไร?
ความแตกต่างในสัดส่วนการกระจายตัวอย่าง คือการกระจายที่เป็นผลจากการคำนวณความแตกต่างระหว่างสัดส่วนตัวอย่างของตัวอย่างที่เป็นไปได้ทั้งหมดจากประชากรสองกลุ่มที่แตกต่างกัน
นั่นคือ กระบวนการเพื่อให้ได้การกระจายตัวตัวอย่างของความแตกต่างในสัดส่วน ประการแรก เพื่อแยกตัวอย่างที่เป็นไปได้ทั้งหมดจากประชากรสองกลุ่มที่แตกต่างกัน ประการที่สอง เพื่อกำหนดสัดส่วนของแต่ละตัวอย่างที่แยกออกมา และสุดท้าย เพื่อกำหนดความแตกต่างระหว่างทั้งหมด สัดส่วนของความแตกต่างของสัดส่วน ประชากรสองคน เพื่อให้ชุดผลลัพธ์ที่ได้รับหลังจากดำเนินการเหล่านี้ทำให้เกิดการกระจายตัวอย่างความแตกต่างในสัดส่วน

ในสถิติ ความแตกต่างในการกระจายตัวอย่างตามสัดส่วนจะถูกนำมาใช้ในการคำนวณความน่าจะเป็นที่ความแตกต่างระหว่าง สัดส่วนตัวอย่าง ของตัวอย่างที่เลือกแบบสุ่ม 2 ตัวอย่างนั้นใกล้เคียงกับความแตกต่างในสัดส่วนประชากร
สูตรการกระจายตัวอย่างส่วนต่างของสัดส่วน
ตัวอย่างที่เลือกสำหรับความแตกต่างในสัดส่วนของการกระจายตัวอย่างจะถูกกำหนดโดย การแจกแจงแบบทวินาม เนื่องจากในทางปฏิบัติ สัดส่วนคืออัตราส่วนของกรณีที่ประสบความสำเร็จต่อจำนวนการสังเกตทั้งหมด
อย่างไรก็ตาม เนื่องจากทฤษฎีบทขีดจำกัดกลาง การแจกแจงแบบทวินามจึงสามารถประมาณได้กับ การแจกแจงความน่าจะเป็นแบบปกติ ดังนั้นการกระจายตัวอย่างส่วนต่างในสัดส่วนสามารถประมาณได้กับการแจกแจงแบบปกติโดยมีลักษณะดังต่อไปนี้
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
หมายเหตุ: การกระจายตัวตัวอย่างของความแตกต่างในสัดส่วนสามารถประมาณได้เฉพาะกับการแจกแจงแบบปกติเท่านั้น

,

,

,

,

และ

.
ดังนั้น เนื่องจากการกระจายตัวตัวอย่างของส่วนต่างในสัดส่วนสามารถประมาณได้กับการแจกแจงแบบปกติ สูตรในการคำนวณสถิติของการกระจายตัวตัวอย่างของส่วนต่างในสัดส่วน จึงเป็นดังนี้

ทอง:
-

คือสัดส่วนตัวอย่าง i
-

คือสัดส่วนของประชากร i
-

คือความน่าจะเป็นที่จะเกิดความล้มเหลวของประชากร i

.
-

คือขนาดตัวอย่าง i
-

เป็นตัวแปรที่กำหนดโดยการแจกแจงแบบปกติมาตรฐาน N(0,1)
สูตรนี้คล้ายกับสูตรทดสอบสมมติฐานเรื่องความแตกต่างในสัดส่วน
ตัวอย่างที่เป็นรูปธรรมของการกระจายตัวอย่างส่วนต่างของสัดส่วน
หลังจากดูคำจำกัดความของความแตกต่างของการกระจายตัวอย่างตามสัดส่วนและสูตรของมันแล้ว คุณสามารถดูตัวอย่างที่แก้ไขได้ทีละขั้นตอนด้านล่างเพื่อทำความเข้าใจแนวคิดให้เสร็จสิ้น
- คุณต้องการวิเคราะห์ความแม่นยำของโรงงานผลิตสองแห่ง โดยโรงงานแห่งหนึ่งผลิตในลักษณะที่มีชิ้นส่วนที่ผลิตเพียง 5% เท่านั้นที่มีข้อบกพร่อง ในขณะที่เปอร์เซ็นต์ของชิ้นส่วนที่ชำรุดของโรงงานอื่นคือ 8% หากเราเก็บตัวอย่างชิ้นส่วนจากโรงงานแห่งแรกจำนวน 200 ชิ้น และตัวอย่างจากโรงงานแห่งที่สองอีกจำนวน 280 ชิ้น ความน่าจะเป็นที่เปอร์เซ็นต์ของเสียในโรงงานผลิตแห่งแรกจะมากกว่าเปอร์เซ็นต์ของเสียในโรงงานแห่งที่สองเป็นเท่าใด การผลิต?
เพื่อให้ทราบข้อมูลปัญหาทั้งหมดให้เสร็จสิ้น ขั้นแรกเราจะคำนวณสัดส่วนของชิ้นส่วนที่ผลิตอย่างดีของแต่ละโรงงาน:
![\begin{array}{c}q_1=1-p_1=1-0,05=0,95\\[2ex]q_2=1-p_2=1-0,08=0,92\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7c02732cc5fb319bfa5bf7b8ed8d03db_l3.png "Rendered by QuickLaTeX.com")
หากอัตราของเสียในโรงงานแห่งแรกมากกว่าอัตราของเสียในโรงงานแห่งที่สอง นั่นหมายความว่าสมการต่อไปนี้จะเป็นจริง:
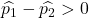

ดังนั้น ความน่าจะเป็นที่อัตราของเสียของโรงงานแห่งแรกมากกว่าอัตราของเสียของโรงงานแห่งที่สองจึงเท่ากับความน่าจะเป็นที่ตัวแปร Z มากกว่า 1.34:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]” title=”Rendered by QuickLaTeX.com” height=”19″ width=”242″ style=”vertical-align: -5px;”></p>
</p>
<p> สุดท้าย เราเพียงแค่ต้องค้นหาความน่าจะเป็นที่สอดคล้องกันใน <a href=](https://statorials.org/wp-content/ql-cache/quicklatex.com-41dd897cdff473ff488cde0e3cc140b0_l3.png) ตารางการแจกแจงแบบปกติ และเราจะแก้ไขปัญหาได้แล้ว:
ตารางการแจกแจงแบบปกติ และเราจะแก้ไขปัญหาได้แล้ว:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]=0,0901″ title=”Rendered by QuickLaTeX.com” height=”19″ width=”319″ style=”vertical-align: -5px;”></p>
</p>
<p> กล่าวโดยสรุป ความน่าจะเป็นที่สัดส่วนของเสียในโรงงานแห่งแรกจะมากกว่าสัดส่วนของเสียในโรงงานแห่งที่สองคือร้อยละ 9.01 </p>
<div style=](https://statorials.org/wp-content/ql-cache/quicklatex.com-8d6e503a2089d30be8fd68bbc722bb44_l3.png)
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม