การสุ่มตัวอย่างความน่าจะเป็น
ในบทความนี้ เราจะอธิบายว่าการสุ่มตัวอย่างความน่าจะเป็นคืออะไร การสุ่มตัวอย่างความน่าจะเป็นประเภทต่างๆ ที่มีอยู่ และดำเนินการอย่างไร นอกจากนี้ คุณจะพบตัวอย่างการสุ่มตัวอย่างความน่าจะเป็นหลายตัวอย่าง สุดท้ายนี้ เราจะแสดงให้คุณเห็นว่าอะไรคือความแตกต่างระหว่างการสุ่มตัวอย่างความน่าจะเป็นและการสุ่มตัวอย่างที่ไม่น่าจะเป็น และข้อดีและข้อเสียของการสุ่มตัวอย่างความน่าจะเป็นคืออะไร
การสุ่มตัวอย่างความน่าจะเป็นคืออะไร?
การสุ่มตัวอย่างความน่าจะ เป็นเป็นวิธีการที่ใช้ในการเลือกบุคคลที่จะถูกรวมไว้ในกลุ่มตัวอย่างเพื่อการศึกษาทางสถิติ ลักษณะสำคัญของการสุ่มตัวอย่างความน่าจะเป็นคือการสุ่มเลือกบุคคล กล่าวคือ ทุกคนมีความน่าจะเป็นที่เท่ากันในการเลือก
นี่เป็นเงื่อนไขสำคัญสำหรับการสุ่มตัวอย่างที่จะพิจารณาว่ามีความน่าจะเป็น: องค์ประกอบทั้งหมดของประชากรทางสถิติจะต้องสามารถเลือกได้ และยิ่งกว่านั้น องค์ประกอบเหล่านั้นจะต้องมีความเป็นไปได้ที่จะถูกเลือกเหมือนกัน
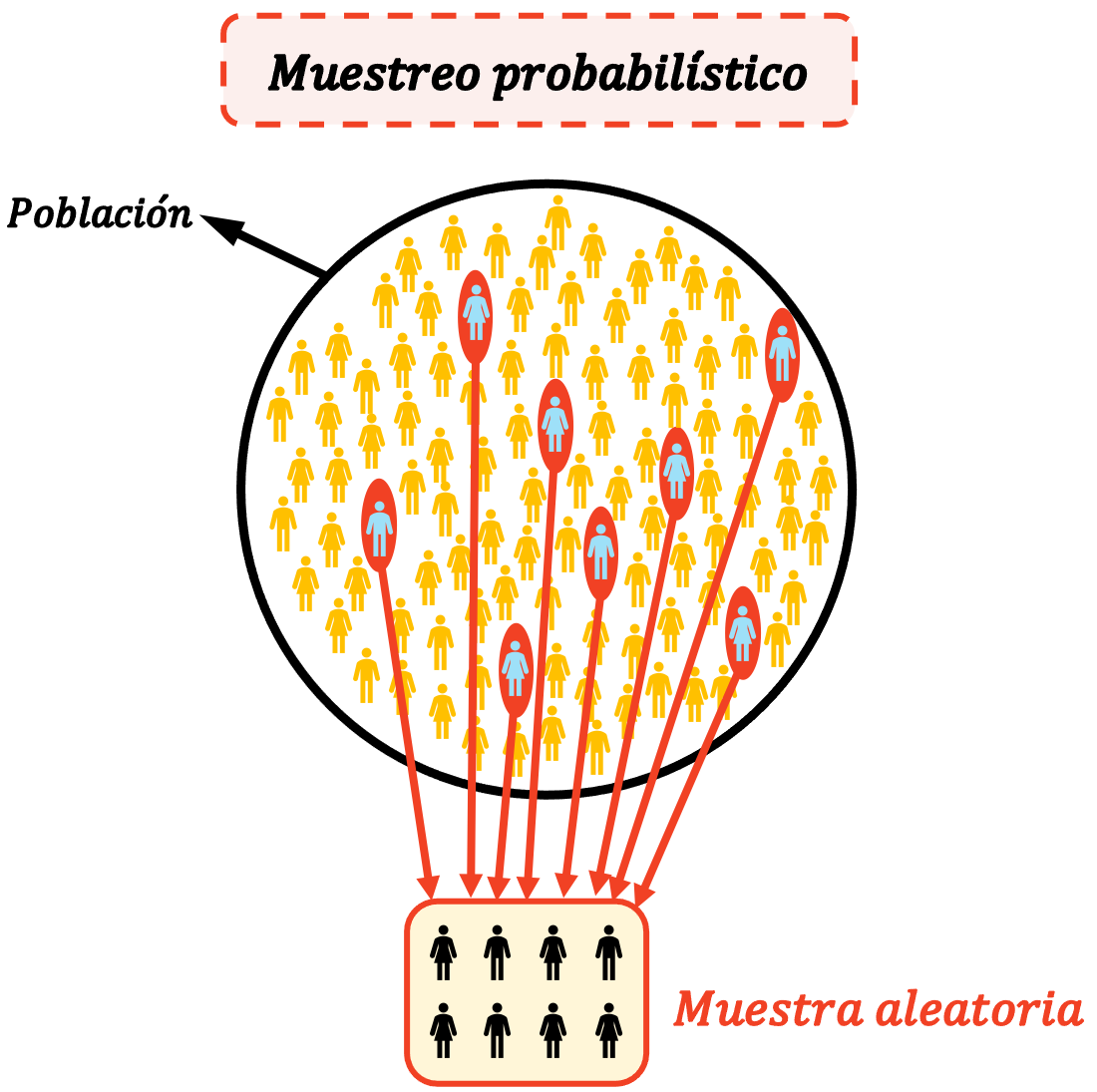
การสุ่มตัวอย่างความน่าจะเป็นใช้เพื่อลดจำนวนผู้ที่เข้าร่วมในการศึกษาทางสถิติ โดยปกติแล้ว เมื่อต้องการวิเคราะห์ประชากรทางสถิติ จะมีขนาดใหญ่มาก ดังนั้นจึงเป็นไปไม่ได้ที่จะสัมภาษณ์ทุกคน นี่คือสาเหตุที่การสุ่มตัวอย่างความน่าจะเป็นทำให้คุณสามารถตั้งคำถามเฉพาะกลุ่มตัวอย่าง จากนั้นจึงคาดการณ์ผลลัพธ์ที่ได้รับกับประชากรทั้งหมด
แม้ว่าเราจะกลับไปสู่คุณลักษณะทั้งหมดของการสุ่มตัวอย่างความน่าจะเป็นโดยละเอียดมากขึ้น แต่โดยทั่วไปแล้วการสุ่มตัวอย่างประเภทนี้จะเป็นวิธีที่ดีที่สุดในการรับตัวอย่างที่เป็นตัวแทนของประชากร เนื่องจากการสุ่มตัวอย่างมีอยู่ตลอดกระบวนการ
ประเภทของตัวอย่างความน่าจะเป็น
ประเภทของการสุ่มตัวอย่างความน่าจะเป็นคือ:
- การสุ่มตัวอย่างอย่างง่าย – ตัวอย่างจะถูกเลือกโดยการสุ่ม
- การสุ่มตัวอย่างอย่างเป็นระบบ : บุคคลกลุ่มแรกจะถูกเลือกโดยการสุ่ม และองค์ประกอบที่เหลือของกลุ่มตัวอย่างจะถูกเลือกตามช่วงเวลาที่คงที่
- การสุ่มตัวอย่างแบบแบ่งชั้น : ประชากรเป้าหมายจะถูกแบ่งออกเป็นชั้น (กลุ่ม) จากนั้นบุคคลจะถูกเลือกโดยการสุ่มจากแต่ละชั้น
- การสุ่มตัวอย่างแบบคลัสเตอร์ : วิธีการสุ่มตัวอย่างนี้ใช้ประโยชน์จากข้อเท็จจริงที่ว่าประชากรถูกแบ่งออกเป็นกลุ่ม (กลุ่ม) เพื่อให้ตัวอย่างประกอบด้วยกลุ่มที่เลือกแบบสุ่ม
ต่อไป คุณได้อธิบายการสุ่มตัวอย่างความน่าจะเป็นแต่ละประเภทโดยละเอียดมากขึ้น
การสุ่มตัวอย่างอย่างง่าย
การสุ่มตัวอย่างอย่างง่าย ทำให้แต่ละองค์ประกอบของประชากรทางสถิติมีความน่าจะเป็นเท่ากันที่จะรวมอยู่ในกลุ่มตัวอย่างที่ศึกษา ดังนั้น บุคคลในกลุ่มตัวอย่างจะถูกเลือกโดยการสุ่ม โดยไม่ต้องใช้เกณฑ์อื่นใด
การจำลองแบบสุ่มมีหลายวิธี แต่ในปัจจุบันมักใช้โปรแกรมคอมพิวเตอร์เช่น Excel เนื่องจากจะช่วยประหยัดเวลาได้มาก
การสุ่มตัวอย่างอย่างเป็นระบบ
ใน การสุ่มตัวอย่างอย่างเป็นระบบ องค์ประกอบหนึ่งของประชากรจะถูกเลือกโดยการสุ่มก่อน จากนั้นองค์ประกอบที่เหลือในตัวอย่างจะถูกเลือกโดยใช้ช่วงเวลาที่คงที่
ดังนั้น ในการสุ่มตัวอย่างอย่างเป็นระบบ เมื่อเราสุ่มเลือกบุคคลแรกจากกลุ่มตัวอย่างแล้ว เราจะต้องนับจำนวนให้มากที่สุดเท่าที่จะเป็นไปได้ในช่วงเวลาที่ต้องการเพื่อนำบุคคลถัดไปออกจากกลุ่มตัวอย่าง และเราทำซ้ำขั้นตอนเดียวกันอย่างต่อเนื่องจนกว่าเราจะมีบุคคลในกลุ่มตัวอย่างมากเท่ากับขนาดตัวอย่างที่เราต้องการ
การสุ่มตัวอย่างแบบแบ่งชั้น
ในเทคนิค การสุ่มตัวอย่างแบบแบ่งชั้น ขั้นแรกประชากรจะถูกแบ่งออกเป็นชั้น (กลุ่ม) จากนั้นจึงสุ่มเลือกบุคคลบางส่วนจากแต่ละชั้นเพื่อสร้างตัวอย่างในการศึกษาทั้งหมด ดังนั้นจะต้องมีสมาชิกอย่างน้อยหนึ่งตัวจากแต่ละชั้นในกลุ่มตัวอย่าง
ชั้นจะต้องเป็นกลุ่มที่เป็นเนื้อเดียวกัน กล่าวคือ บุคคลในชั้นหนึ่งมีลักษณะเฉพาะของตัวเองที่ทำให้พวกเขาแตกต่างจากชั้นอื่น บุคคลจึงสามารถอยู่ในชั้นเดียวเท่านั้น
การสุ่มตัวอย่างคลัสเตอร์
การสุ่มตัวอย่างแบบคลัสเตอร์และการสุ่มตัวอย่างแบบแบ่งชั้นอาจสับสนได้เนื่องจากคล้ายกันมาก แต่ถ้าคุณมองใกล้ ๆ ทั้งสองวิธีจะเป็นวิธีการสุ่มตัวอย่างความน่าจะเป็นที่แตกต่างกันสองวิธี
การสุ่มตัวอย่างแบบคลัสเตอร์ ใช้ประโยชน์จากข้อเท็จจริงที่ว่ากระจุกธรรมชาติ (กลุ่ม) มีอยู่แล้วในประชากรเพื่อศึกษาเพียงไม่กี่กระจุกแทนที่จะศึกษาบุคคลทั้งหมดในประชากร
วิธีนี้แตกต่างจากการสุ่มตัวอย่างแบบแบ่งชั้นตรงที่ไม่จำเป็นต้องเลือกเฉพาะรายบุคคลจากกลุ่ม แต่เมื่อเลือกกลุ่มที่จะศึกษาแล้ว สมาชิกทั้งหมดจะต้องได้รับการวิเคราะห์
การสุ่มตัวอย่างแบบคลัสเตอร์เรียกอีกอย่างว่าการสุ่มตัวอย่างแบบคลัสเตอร์ การสุ่มตัวอย่างแบบคลัสเตอร์ หรือการสุ่มตัวอย่างแบบพื้นที่
วิธีการสุ่มตัวอย่างความน่าจะเป็น
ขั้นตอนในการดำเนินการสุ่มตัวอย่างความน่าจะเป็นมีดังนี้:
- กำหนดประชากรเป้าหมาย
- กำหนดลักษณะตัวอย่างและขนาดตัวอย่างที่ต้องการ
- เลือกประเภทการสุ่มตัวอย่างความน่าจะเป็นที่เหมาะสม
- เลือกบุคคลในกลุ่มตัวอย่างตามวิธีการสุ่มตัวอย่างที่เลือกในขั้นตอนก่อนหน้า
- วิเคราะห์องค์ประกอบของตัวอย่างที่ได้รับ
ขั้นตอนที่สำคัญที่สุดในการสุ่มตัวอย่างความน่าจะเป็นคือการเลือกเทคนิคความน่าจะเป็นที่เหมาะสม ซึ่งจะช่วยปรับให้เข้ากับประชากรเป้าหมาย และสามารถประหยัดเวลาและทรัพยากรที่ใช้
ตามหลักเหตุผล เพื่อระบุวิธีการที่เหมาะสมสำหรับแต่ละกรณี คุณจำเป็นต้องรู้ว่าข้อดีและข้อเสียของมันคืออะไร ดังนั้นเราขอแนะนำให้อ่านบทความที่ลิงก์ด้านบนในการอธิบายการสุ่มตัวอย่างความน่าจะเป็นแต่ละประเภท
ตัวอย่างตัวอย่างความน่าจะเป็น
เมื่อพิจารณาถึงคำจำกัดความของการสุ่มตัวอย่างความน่าจะเป็นและคำอธิบายของแต่ละประเภท เราจะเห็นตัวอย่างวิธีการเลือกตัวอย่างการศึกษา แต่ใช้เทคนิคการสุ่มตัวอย่างความน่าจะเป็นที่แตกต่างกัน
- ตัวอย่างเช่น หากเราต้องการทำการวิเคราะห์ทางสถิติของพนักงานของบริษัทข้ามชาติ เห็นได้ชัดว่าเราไม่สามารถทำการวิจัยกับพนักงานของบริษัททั้งหมดได้ แต่เราต้องเลือกตัวอย่างแล้วคาดการณ์ผลลัพธ์ที่ได้รับให้กับทั้งบริษัท ประชากร. ในการทำเช่นนี้ เราสามารถเลือกผู้เข้าร่วมโดยการสุ่มโดยใช้การสุ่มตัวอย่างแบบง่ายๆ
- อีกวิธีหนึ่งในการสุ่มเลือกผู้เข้าร่วมการศึกษาคือการใช้การสุ่มตัวอย่างอย่างเป็นระบบ สำหรับสิ่งนี้ เราจำเป็นต้องมีรายชื่อพนักงานทั้งหมด ดังนั้นเราจึงสุ่มเลือกหนึ่งรายการ จากนั้นเรานับช่วงเวลาที่คงที่ในรายการเพื่อเลือกคนที่เหลือที่จะสัมภาษณ์
- นอกจากนี้ยังสามารถเลือกตัวอย่างได้โดยการสุ่มตัวอย่างแบบแบ่งชั้น โดยจะต้องแบ่งประชากรออกเป็นกลุ่มๆ เช่น แบ่งพนักงานออกเป็นชั้นตามอายุได้ หลังจากจำแนกประเภทแล้ว เราจะสุ่มเลือกบุคคลจากแต่ละกลุ่ม
- สุดท้ายนี้ ในการเลือกตัวอย่างด้วยวิธีสุ่มตัวอย่างแบบคลัสเตอร์ เราสามารถใช้ประโยชน์จากข้อเท็จจริงที่ว่าบริษัทมีคนงานในประเทศต่างๆ เพื่อสร้างคลัสเตอร์ (กลุ่ม) เพื่อให้พนักงานแต่ละคนอยู่ในกลุ่มของประเทศที่เขาทำงานอยู่ สิ่งที่เหลืออยู่คือการสุ่มเลือกกลุ่มที่จะเข้าร่วมในการวิจัย
ความแตกต่างระหว่างการสุ่มตัวอย่างความน่าจะเป็นและการสุ่มตัวอย่างที่ไม่น่าจะเป็น
ความแตกต่างที่สำคัญระหว่างการสุ่มตัวอย่างความน่าจะเป็นและการสุ่มตัวอย่างที่ไม่น่าจะเป็น คือวิธีการเลือกตัวอย่าง ในการสุ่มตัวอย่างความน่าจะเป็น บุคคลทุกคนมีความน่าจะเป็นเท่ากันในการถูกเลือก ในทางกลับกัน ในการสุ่มตัวอย่างที่ไม่น่าจะเป็น บุคคลไม่มีความเป็นไปได้ที่จะถูกเลือกเหมือนกัน
ในการสุ่มตัวอย่างแบบไม่น่าจะเป็น การเลือกองค์ประกอบตัวอย่างมีโอกาสไม่เท่ากัน เนื่องจากโดยทั่วไปแล้วนักวิจัยเป็นผู้ทำ ซึ่งแตกต่างจากการสุ่มตัวอย่างความน่าจะเป็นที่บุคคลจะถูกเลือกโดยการสุ่ม
คุณลักษณะที่แตกต่างอีกประการหนึ่งระหว่างการสุ่มตัวอย่างทั้งสองประเภทนี้อยู่ที่ลักษณะทั่วไปของข้อสรุปที่ได้รับ ในการสุ่มตัวอย่างความน่าจะเป็น โดยทั่วไปตัวอย่างจะเป็นตัวแทน ดังนั้นผลลัพธ์ที่ได้จึงสามารถสรุปได้กับประชากรทั้งหมด ในทางตรงกันข้าม ตัวอย่างของกลุ่มตัวอย่างที่ไม่น่าจะเป็นปกติไม่มีตัวแทนที่เพียงพอ ดังนั้นข้อสรุปที่ดึงมาสามารถนำไปใช้กับบุคคลที่ศึกษาเท่านั้น
ข้อดีและข้อเสียของการสุ่มตัวอย่างความน่าจะเป็น
ข้อดีและข้อเสียของการสุ่มตัวอย่างความน่าจะเป็นคือ:
| ข้อได้เปรียบ | ข้อเสีย |
|---|---|
| โดยทั่วไปการสุ่มตัวอย่างความน่าจะเป็นจะให้ผลกำไรเชิงเศรษฐกิจ | ผลลัพธ์ที่ได้อาจตีความได้ยาก |
| เป็นวิธีการเก็บตัวอย่างที่ง่ายและรวดเร็ว | บางครั้งข้อผิดพลาดในการสุ่มตัวอย่างอาจสูงมาก |
| โดยทั่วไปแล้ว ผู้รับผิดชอบในการสุ่มตัวอย่างไม่จำเป็นต้องมีความรู้เกี่ยวกับประชากรมากนัก | จำเป็นต้องมีรายชื่อประชากรทั้งหมด |
| ตัวอย่างที่ได้รับเป็นตัวแทน | ตัวอย่างเล็กๆ น้อยๆ อาจไม่ได้เป็นตัวแทน |
ข้อได้เปรียบหลักของการสุ่มตัวอย่างความน่าจะเป็นคือมีความคุ้มทุนมาก ซึ่งหมายความว่าโดยปกติแล้วการใช้เทคนิคการสุ่มตัวอย่างนี้จะคุ้มทุน
นอกจากนี้วิธีการสุ่มตัวอย่างความน่าจะเป็นไม่จำเป็นต้องให้ผู้วิจัยมีความรู้และประสบการณ์ในสาขานี้ เนื่องจากการเลือกองค์ประกอบตัวอย่างจะกระทำแบบสุ่ม คุณลักษณะนี้ทำให้การสุ่มตัวอย่างความน่าจะเป็นง่ายกว่าการสุ่มตัวอย่างที่ไม่น่าจะเป็นมาก
อย่างไรก็ตาม ผลลัพธ์ที่ได้อาจไม่แม่นยำในบางครั้ง โดยเฉพาะในกรณีที่มีตัวอย่างขนาดเล็ก ด้วยเหตุนี้การเลือกขนาดตัวอย่างที่เหมาะสมจึงเป็นเรื่องสำคัญ
ข้อเสียอีกประการหนึ่งของเทคนิคการสุ่มตัวอย่างความน่าจะเป็นคือ จำเป็นต้องมีรายชื่อบุคคลทั้งหมดในประชากรเพื่อจำลองโอกาส
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม