วิธีการทดสอบ shapiro-wilk ใน r (พร้อมตัวอย่าง)
การทดสอบชาปิโร-วิลค์ เป็นการทดสอบภาวะปกติ ใช้เพื่อพิจารณาว่าตัวอย่างมาจาก การแจกแจงแบบปกติ หรือไม่
การทดสอบประเภทนี้มีประโยชน์ในการพิจารณาว่าชุดข้อมูลที่กำหนดมาจากการแจกแจงแบบปกติหรือไม่ ซึ่งเป็นสมมติฐานที่ใช้กันทั่วไปในการทดสอบทางสถิติหลายอย่าง รวมถึง การถดถอย การวิเคราะห์ความแปรปรวน การทดสอบที และอื่นๆ อีกมากมาย ‘คนอื่น.
เราสามารถทำการทดสอบ Shapiro-Wilk บนชุดข้อมูลที่กำหนดได้อย่างง่ายดายโดยใช้ฟังก์ชันในตัวต่อไปนี้ใน R:
ชาปิโร.ทดสอบ(x)
ทอง:
- x: เวกเตอร์ตัวเลขของค่าข้อมูล
ฟังก์ชันนี้สร้างสถิติการทดสอบ W พร้อมกับค่า p ที่สอดคล้องกัน หากค่า p น้อยกว่า α = 0.05 ก็มีหลักฐานเพียงพอที่จะบอกว่ากลุ่มตัวอย่างไม่ได้มาจากประชากรที่มีการกระจายแบบปกติ
หมายเหตุ: ขนาดตัวอย่างต้องอยู่ระหว่าง 3 ถึง 5,000 เพื่อใช้ฟังก์ชัน shapiro.test()
บทช่วยสอนนี้แสดงตัวอย่างการใช้งานฟังก์ชันนี้ในทางปฏิบัติหลายตัวอย่าง
ตัวอย่างที่ 1: การทดสอบชาปิโร-วิลค์กับข้อมูลปกติ
รหัสต่อไปนี้แสดงวิธีดำเนินการทดสอบ Shapiro-Wilk บนชุดข้อมูลที่มีขนาดตัวอย่าง n=100:
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a normal distribution data <- rnorm(100) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.98957, p-value = 0.6303
ค่า p ของการทดสอบกลายเป็น 0.6303 . เนื่องจากค่านี้ไม่น้อยกว่า 0.05 เราจึงสามารถสรุปได้ว่าข้อมูลตัวอย่างมาจากประชากรที่มีการกระจายแบบปกติ
ผลลัพธ์นี้ไม่น่าประหลาดใจเนื่องจากเราสร้างข้อมูลตัวอย่างโดยใช้ฟังก์ชัน rnorm() ซึ่งสร้างค่าสุ่มจากการแจกแจงแบบปกติโดยมีค่าเฉลี่ย = 0 และส่วนเบี่ยงเบนมาตรฐาน = 1
ที่เกี่ยวข้อง: คำแนะนำเกี่ยวกับ dnorm, pnorm, qnorm และ rnorm ใน R
นอกจากนี้เรายังสามารถสร้างฮิสโตแกรมเพื่อตรวจสอบด้วยสายตาว่าข้อมูลตัวอย่างมีการกระจายตามปกติ:
hist(data, col=' steelblue ')
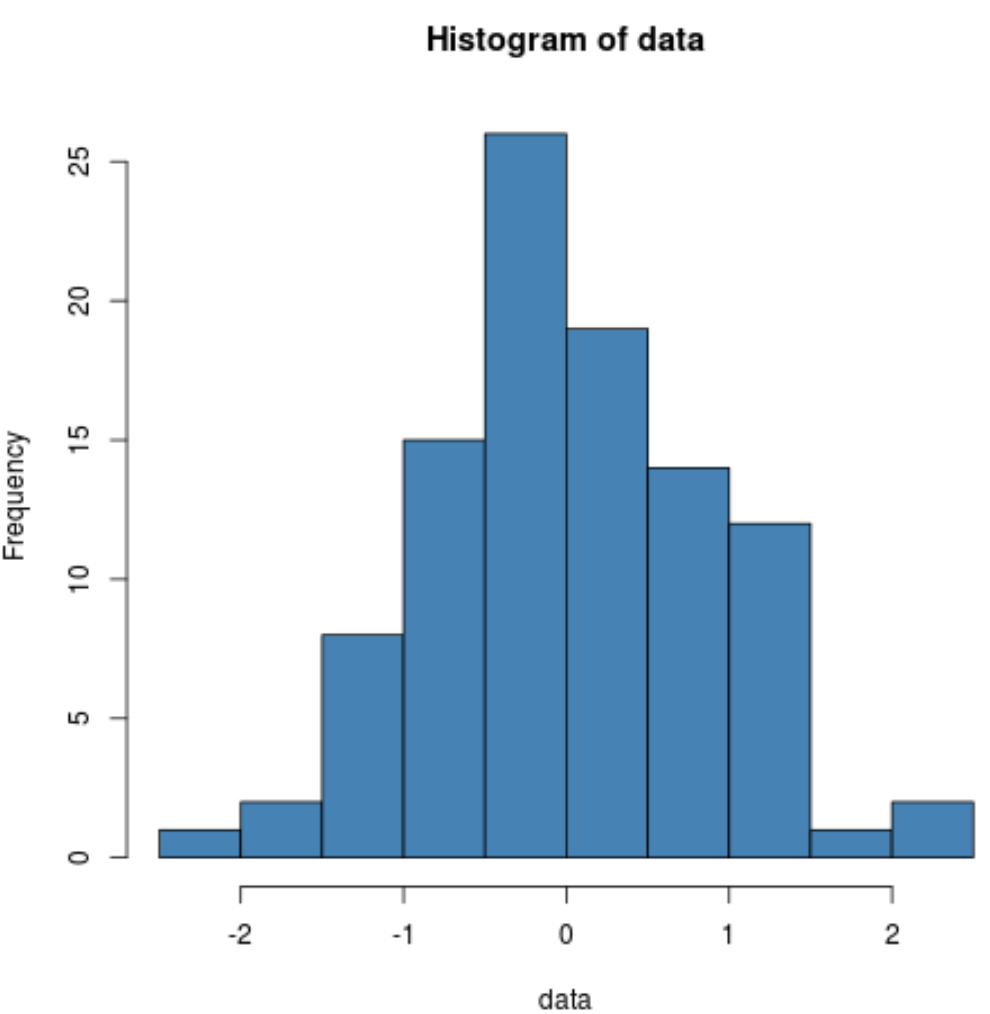
เราจะเห็นได้ว่าการแจกแจงนั้นค่อนข้างเป็นรูประฆังโดยมียอดอยู่ตรงกลางของการแจกแจง ซึ่งเป็นเรื่องปกติของข้อมูลที่แจกแจงแบบปกติ
ตัวอย่างที่ 2: การทดสอบชาปิโร-วิลค์กับข้อมูลที่ไม่ปกติ
รหัสต่อไปนี้แสดงวิธีดำเนินการทดสอบ Shapiro-Wilk บนชุดข้อมูลที่มีขนาดตัวอย่าง n=100 โดยค่าจะถูกสร้างขึ้นแบบสุ่มจาก การแจกแจงปัวซอง :
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a Poisson distribution data <- rpois(n=100, lambda=3) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.94397, p-value = 0.0003393
ค่า p ของการทดสอบกลายเป็น 0.0003393 เนื่องจากค่านี้น้อยกว่า 0.05 เราจึงมีหลักฐานเพียงพอที่จะบอกว่าข้อมูลตัวอย่าง ไม่ได้ มาจากประชากรที่แจกแจงแบบปกติ
ผลลัพธ์นี้ไม่น่าประหลาดใจเนื่องจากเราสร้างข้อมูลตัวอย่างโดยใช้ฟังก์ชัน rpois() ซึ่งสร้างค่าสุ่มจากการแจกแจงแบบปัวซอง
ที่เกี่ยวข้อง: คำแนะนำเกี่ยวกับ dpois, ppois, qpois และ rpois ใน R
นอกจากนี้เรายังสามารถสร้างฮิสโตแกรมเพื่อให้เห็นว่าข้อมูลตัวอย่างไม่ได้กระจายตามปกติ:
hist(data, col=' coral2 ')
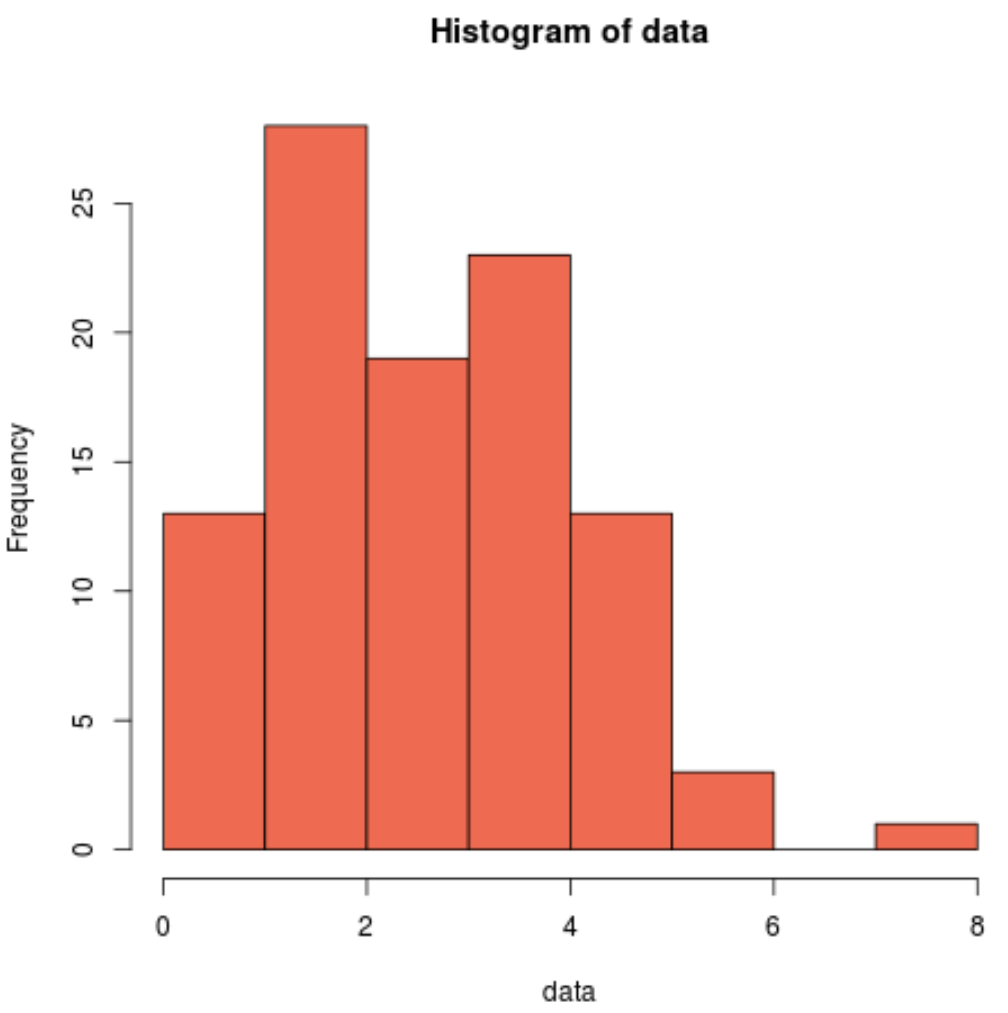
เราจะเห็นได้ว่าการแจกแจงนั้นเบ้ขวา และไม่มี “รูปทรงระฆัง” ทั่วไปที่เกี่ยวข้องกับการแจกแจงแบบปกติ ดังนั้น ฮิสโตแกรมของเราจึงตรงกับผลลัพธ์ของการทดสอบชาปิโร-วิลค์ และยืนยันว่าข้อมูลตัวอย่างของเราไม่ได้มาจากการแจกแจงแบบปกติ
จะทำอย่างไรกับข้อมูลที่ไม่ปกติ
หากชุดข้อมูลที่กำหนด ไม่ได้ รับการแจกแจงตามปกติ เรามักจะดำเนินการแปลงอย่างใดอย่างหนึ่งต่อไปนี้เพื่อให้เป็นเรื่องปกติมากขึ้นได้:
1. การแปลงบันทึก: แปลงตัวแปรการตอบสนองจาก y เป็น log(y)
2. การแปลงรากที่สอง: แปลงตัวแปรตอบสนองจาก y เป็น √y
3. การแปลงรากที่สาม: แปลงตัวแปรการตอบสนองจาก y เป็น y 1/3
โดยการดำเนินการแปลงเหล่านี้ โดยทั่วไปแล้วตัวแปรการตอบสนองจะประมาณค่าการแจกแจงแบบปกติ
ลองอ่าน บทช่วยสอนนี้ เพื่อดูวิธีดำเนินการแปลงเหล่านี้ในทางปฏิบัติ
แหล่งข้อมูลเพิ่มเติม
วิธีทำการทดสอบ Anderson-Darling ใน R
วิธีทำการทดสอบ Kolmogorov-Smirnov ใน R
วิธีทำการทดสอบ Shapiro-Wilk ใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม