วิธีสร้างการแจกแจงแบบปกติใน python (พร้อมตัวอย่าง)
คุณสามารถสร้าง การแจกแจงแบบปกติ ใน Python ได้อย่างรวดเร็วโดยใช้ฟังก์ชัน numpy.random.normal() ซึ่งใช้ไวยากรณ์ต่อไปนี้:
numpy. random . normal (loc=0.0, scale=1.0, size=None)
ทอง:
- loc: ค่าเฉลี่ยของการแจกแจง ค่าเริ่มต้นคือ 0
- สเกล: ส่วนเบี่ยงเบนมาตรฐานของการแจกแจง ค่าเริ่มต้นคือ 1
- ขนาด: ขนาดตัวอย่าง
บทช่วยสอนนี้แสดงตัวอย่างการใช้ฟังก์ชันนี้เพื่อสร้างการแจกแจงแบบปกติใน Python
ที่เกี่ยวข้อง: วิธีสร้าง Bell Curve ใน Python
ตัวอย่าง: การสร้างการแจกแจงแบบปกติใน Python
รหัสต่อไปนี้แสดงวิธีการสร้างการแจกแจงแบบปกติใน Python:
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
เราสามารถหาค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของการแจกแจงนี้ได้อย่างรวดเร็ว:
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
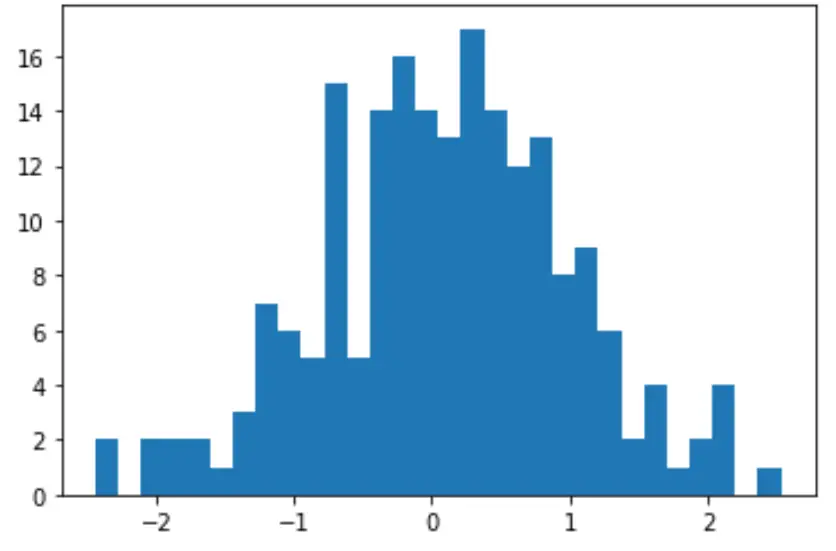
นอกจากนี้เรายังสามารถสร้างฮิสโตแกรมด่วนเพื่อแสดงภาพการกระจายของค่าข้อมูลได้:
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
เรายังสามารถทำการ ทดสอบ Shapiro-Wilk เพื่อดูว่าชุดข้อมูลมาจากประชากรปกติหรือไม่:
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
ค่า p ของการทดสอบกลายเป็น 0.8669 เนื่องจากค่านี้ไม่น้อยกว่า 0.05 เราจึงสามารถสรุปได้ว่าข้อมูลตัวอย่างมาจากประชากรที่มีการกระจายแบบปกติ
ผลลัพธ์นี้ไม่น่าประหลาดใจเนื่องจากเราสร้างข้อมูลโดยใช้ฟังก์ชัน numpy.random.normal() ซึ่งสร้างตัวอย่างข้อมูลแบบสุ่มจากการแจกแจงแบบปกติ
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม