วิธีการคำนวณเศษที่เหลือของนักเรียนใน python
ยอดคงเหลือของนักเรียน เป็นเพียงยอดคงเหลือหารด้วยค่าเบี่ยงเบนมาตรฐานโดยประมาณ
ในทางปฏิบัติ โดยทั่วไปเรากล่าวว่า การสังเกต ใดๆ ในชุดข้อมูลที่มีค่าคงเหลือของนักเรียนมากกว่าค่าสัมบูรณ์ที่ 3 ถือเป็นค่าผิดปกติ
เราสามารถรับส่วนที่เหลือของโมเดลการถดถอยใน Python ได้อย่างรวดเร็วโดยใช้ฟังก์ชัน OLSResults.outlier_test() ของ statsmodels ซึ่งใช้ไวยากรณ์ต่อไปนี้:
OLSResults.outlier_test()
โดยที่ OLSResults คือชื่อของโมเดลเชิงเส้นที่พอดีโดยใช้ฟังก์ชัน statsmodels ols()
ตัวอย่าง: การคำนวณยอดคงเหลือของนักเรียนใน Python
สมมติว่าเราสร้างโมเดล การถดถอยเชิงเส้นอย่างง่าย ต่อไปนี้ใน Python:
#import necessary packages and functions import numpy as np import pandas as pd import statsmodels. api as sm from statsmodels. formula . api import ols #create dataset df = pd. DataFrame ({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86], 'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19]}) #fit simple linear regression model model = ols('rating ~ points', data=df). fit ()
เราสามารถใช้ฟังก์ชัน outlier_test() เพื่อสร้าง DataFrame ที่ประกอบด้วย Studentized คงเหลือสำหรับการสังเกตแต่ละครั้งในชุดข้อมูล:
#calculate studentized residuals stud_res = model. outlier_test () #display studentized residuals print(stud_res) student_resid unadj_p bonf(p) 0 -0.486471 0.641494 1.000000 1 -0.491937 0.637814 1.000000 2 0.172006 0.868300 1.000000 3 1.287711 0.238781 1.000000 4 0.106923 0.917850 1.000000 5 0.748842 0.478355 1.000000 6 -0.968124 0.365234 1.000000 7 -2.409911 0.046780 0.467801 8 1.688046 0.135258 1.000000 9 -0.014163 0.989095 1.000000
DataFrame นี้จะแสดงค่าต่อไปนี้สำหรับแต่ละข้อสังเกตในชุดข้อมูล:
- สารตกค้างของนักเรียน
- ค่า p-value ที่ยังไม่ได้ปรับปรุงของยอดคงเหลือที่เป็นนักเรียน
- ค่า p-value ที่แก้ไขโดย Bonferroni ของยอดคงเหลือของนักเรียน
เราจะเห็นว่าค่าคงเหลือของนักเรียนสำหรับการสังเกตครั้งแรกในชุดข้อมูลคือ -0.486471 ค่าคงเหลือของนักเรียนสำหรับการสังเกตครั้งที่สองคือ -0.491937 และอื่นๆ
นอกจากนี้เรายังสามารถสร้างการลงจุดอย่างรวดเร็วของค่าของตัวแปรทำนายเทียบกับค่าตกค้างของนักเรียนที่เกี่ยวข้อง:
import matplotlib. pyplot as plt #define predictor variable values and studentized residuals x = df[' points '] y = stud_res[' student_resid '] #create scatterplot of predictor variable vs. studentized residuals plt. scatter (x,y) plt. axhline (y=0, color=' black ', linestyle=' -- ') plt. xlabel (' Points ') plt. ylabel (' Studentized Residuals ')
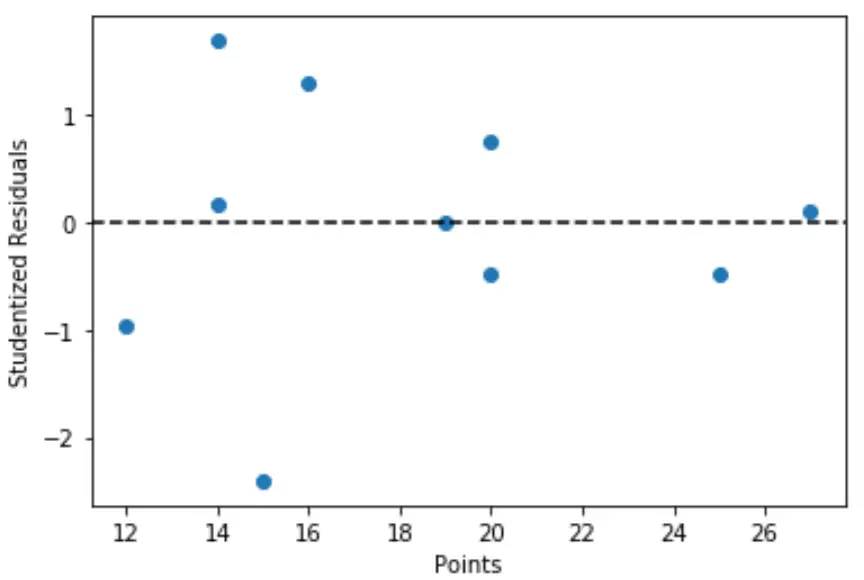
จากกราฟเราจะเห็นว่าไม่มีการสังเกตใดที่มีนักเรียนคงเหลือที่มีค่าสัมบูรณ์มากกว่า 3 ดังนั้นจึงไม่มีค่าผิดปกติที่ชัดเจนในชุดข้อมูล
แหล่งข้อมูลเพิ่มเติม
วิธีดำเนินการถดถอยเชิงเส้นอย่างง่ายใน Python
วิธีดำเนินการถดถอยเชิงเส้นพหุคูณใน Python
วิธีสร้างพล็อตที่เหลือใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม