ข้อมูลเบื้องต้นง่ายๆ ในการส่งเสริมการเรียนรู้ของเครื่อง
อัลกอริธึมแมชชีนเลิร์นนิงภายใต้การดูแล ส่วนใหญ่จะอิงตามการใช้แบบจำลองการคาดการณ์เดียว เช่น การถดถอยเชิงเส้น การถดถอยโลจิสติก การถดถอย แบบสัน เป็นต้น
อย่างไรก็ตาม วิธีการต่างๆ เช่น การบรรจุถุง และ การจัดฟอเรสต์แบบสุ่ม จะสร้างแบบจำลองที่แตกต่างกันมากมายโดยอิงตามตัวอย่างที่บูตเครื่องซ้ำแล้วซ้ำอีกของชุดข้อมูลดั้งเดิม การคาดการณ์ข้อมูลใหม่จะทำโดยการใช้ค่าเฉลี่ยของการคาดการณ์ที่ทำโดยแบบจำลองแต่ละแบบ
วิธีการเหล่านี้มีแนวโน้มที่จะเสนอการปรับปรุงความแม่นยำในการทำนายมากกว่าวิธีที่ใช้แบบจำลองการทำนายเดียวเท่านั้น เนื่องจากใช้กระบวนการต่อไปนี้:
- ขั้นแรก สร้างแบบจำลองแต่ละแบบที่มี ความแปรปรวนสูงและอคติต่ำ (เช่น ต้นไม้การตัดสินใจ ที่เติบโตอย่างลึกซึ้ง)
- จากนั้นหาค่าเฉลี่ยการคาดการณ์ของแต่ละโมเดลเพื่อลดความแปรปรวน
อีกวิธีหนึ่งที่มีแนวโน้มว่าจะปรับปรุงความแม่นยำในการทำนายให้ดียิ่งขึ้นไปอีก เรียกว่า การเร่ง
การส่งเสริมคืออะไร?
การบูสต์เป็นวิธีการที่สามารถใช้ได้กับโมเดลทุกประเภท แต่ส่วนใหญ่มักใช้กับแผนผังการตัดสินใจ
แนวคิดเบื้องหลังการเพิ่มพลังนั้นง่ายมาก:
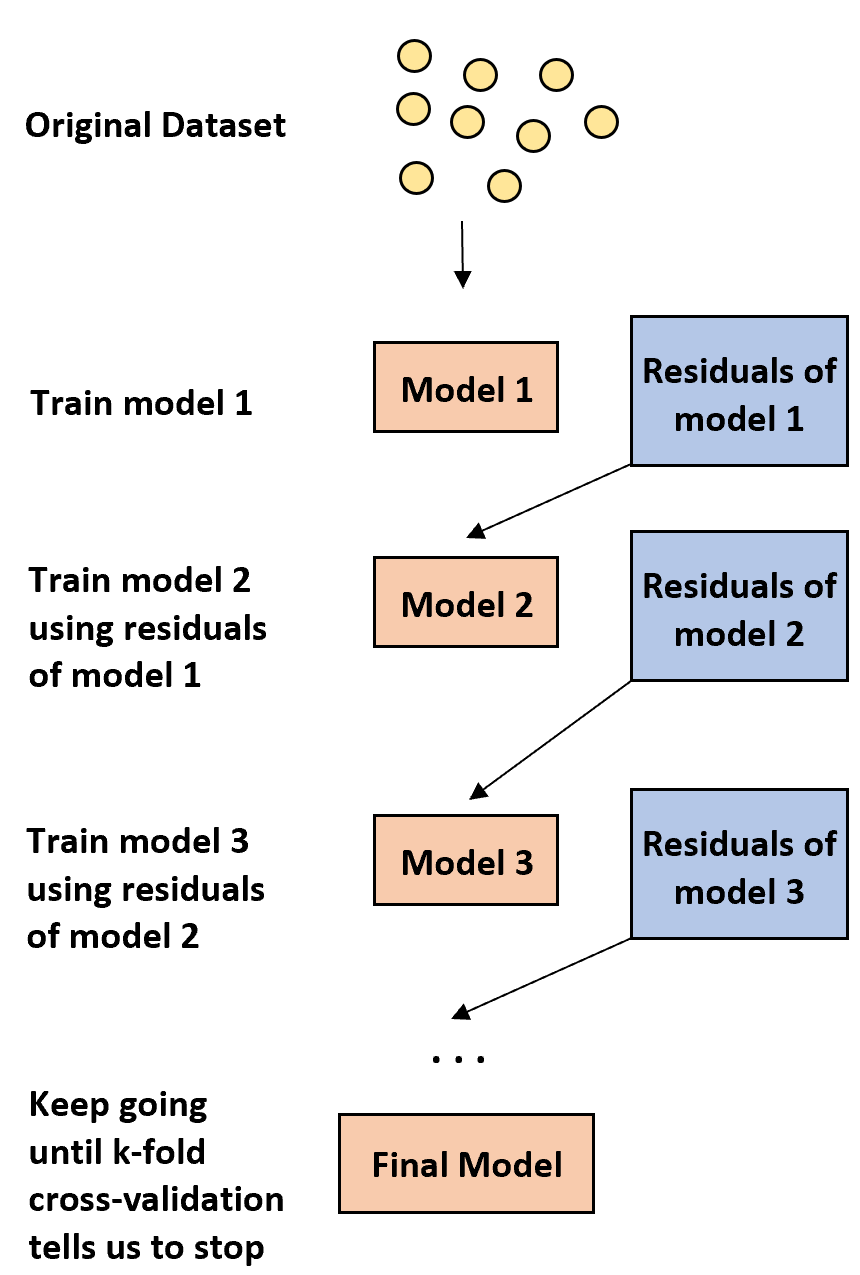
1. ขั้นแรก สร้างโมเดลที่อ่อนแอ
- โมเดล “อ่อนแอ” คือโมเดลที่มีอัตราข้อผิดพลาดดีกว่าการประมาณการแบบสุ่มเพียงเล็กน้อยเท่านั้น
- ในทางปฏิบัติ นี่มักจะเป็นแผนผังการตัดสินใจที่มีแผนกเดียวหรือสองแผนกเท่านั้น
2. ถัดไป สร้างแบบจำลองที่อ่อนแออีกแบบหนึ่งโดยอิงจากส่วนที่เหลือจากรุ่นก่อนหน้า
- ในทางปฏิบัติ เราใช้ส่วนที่เหลือจากแบบจำลองก่อนหน้า (เช่น ข้อผิดพลาดในการคาดคะเนของเรา) เพื่อให้พอดีกับแบบจำลองใหม่ที่ปรับปรุงอัตราข้อผิดพลาดโดยรวมเล็กน้อย
3. ดำเนินการตามขั้นตอนนี้ต่อไปจนกว่าการตรวจสอบข้าม k-fold บอกให้เราหยุด
- ในทางปฏิบัติ เราใช้ การตรวจสอบความถูกต้องแบบข้าม k-fold เพื่อระบุว่าเมื่อใดเราควรหยุดพัฒนาแบบจำลองที่เสริมประสิทธิภาพ
เมื่อใช้วิธีนี้ เราสามารถเริ่มต้นด้วยแบบจำลองที่อ่อนแอและ “ปรับปรุง” ประสิทธิภาพของมันต่อไปโดยการสร้างแผนผังใหม่ตามลำดับที่ปรับปรุงประสิทธิภาพของแผนผังก่อนหน้า จนกว่าเราจะได้แบบจำลองสุดท้ายที่มีความแม่นยำในการทำนายสูง
เหตุใดการเพิ่มประสิทธิภาพจึงทำงาน
ปรากฎว่าการเพิ่มประสิทธิภาพสามารถสร้างโมเดลที่ทรงพลังที่สุดในการเรียนรู้ของเครื่องทั้งหมดได้
ในหลายอุตสาหกรรม โมเดลที่ได้รับการเพิ่มประสิทธิภาพจะใช้เป็นโมเดลอ้างอิงในการผลิต เนื่องจากมีแนวโน้มที่จะมีประสิทธิภาพเหนือกว่าโมเดลอื่นๆ ทั้งหมด
เหตุผลที่เทมเพลตที่ได้รับการปรับปรุงทำงานได้ดีนั้นเกิดจากการทำความเข้าใจแนวคิดง่ายๆ:
1. ประการแรก แบบจำลองที่ได้รับการปรับปรุงจะสร้างแผนผังการตัดสินใจที่อ่อนแอซึ่งมีความแม่นยำในการทำนายต่ำ กล่าวกันว่าแผนผังการตัดสินใจนี้มีความแปรปรวนต่ำและมีอคติสูง
2. เนื่องจากแบบจำลองที่ได้รับการปรับปรุงเป็นไปตามกระบวนการปรับปรุงตามลำดับของแผนผังการตัดสินใจก่อนหน้านี้ แบบจำลองโดยรวมจึงสามารถลดอคติในแต่ละขั้นตอนได้อย่างช้าๆ โดยไม่เพิ่มความแปรปรวนอย่างมีนัยสำคัญ
3. โมเดลที่ติดตั้งขั้นสุดท้ายมีแนวโน้มที่จะมีอคติ และ ความแปรปรวนต่ำเพียงพอ นำไปสู่แบบจำลองที่สามารถสร้างอัตราความผิดพลาดในการทดสอบต่ำกับข้อมูลใหม่
ข้อดีและข้อเสียของการเสริมกำลัง
ข้อได้เปรียบที่ชัดเจนของการเพิ่มประสิทธิภาพคือสามารถสร้างแบบจำลองที่มีความแม่นยำในการคาดการณ์สูง เมื่อเทียบกับโมเดลประเภทอื่นๆ เกือบทั้งหมด
ข้อเสียเปรียบที่อาจเกิดขึ้นคือโมเดลที่ได้รับการปรับปรุงแล้วนั้นยากต่อการตีความ แม้ว่าจะสามารถให้ความสามารถอย่างมากในการทำนายค่าการตอบสนองของข้อมูลใหม่ แต่ก็ยากที่จะอธิบายกระบวนการที่แน่นอนที่ใช้ในการบรรลุเป้าหมายนี้
ในทางปฏิบัติ นักวิทยาศาสตร์ข้อมูลและผู้ปฏิบัติงานด้านแมชชีนเลิร์นนิงส่วนใหญ่สร้างแบบจำลองที่ได้รับการปรับปรุงเนื่องจากต้องการทำนายค่าการตอบสนองของข้อมูลใหม่ได้อย่างแม่นยำ ดังนั้นความจริงที่ว่าแบบจำลองที่ได้รับการปรับปรุงนั้นตีความได้ยากโดยทั่วไปจึงไม่ใช่ปัญหา
บูสเตอร์ในทางปฏิบัติ
ในทางปฏิบัติ มีอัลกอริธึมหลายประเภทที่ใช้ในการเพิ่มประสิทธิภาพ ได้แก่:
ขึ้นอยู่กับขนาดของชุดข้อมูลและพลังการประมวลผลของเครื่องของคุณ วิธีใดวิธีหนึ่งเหล่านี้อาจดีกว่าวิธีอื่น
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม