วิธีการคำนวณค่าเฉลี่ยเคลื่อนที่ในหมีแพนด้า
ค่าเฉลี่ยเคลื่อนที่ เป็นเพียงค่าเฉลี่ยของช่วงก่อนหน้าจำนวนหนึ่งในอนุกรมเวลา
ในการคำนวณค่าเฉลี่ยการหมุนของหนึ่งคอลัมน์ขึ้นไปใน DataFrame ของ pandas เราสามารถใช้ไวยากรณ์ต่อไปนี้:
df[' column_name ']. rolling ( rolling_window ). mean ()
บทช่วยสอนนี้มีตัวอย่างการใช้งานฟังก์ชันนี้ในทางปฏิบัติหลายตัวอย่าง
ตัวอย่าง: การคำนวณค่าเฉลี่ยเคลื่อนที่ในหน่วยหมีแพนด้า
สมมติว่าเรามี DataFrame แพนด้าดังต่อไปนี้:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
เราสามารถใช้ไวยากรณ์ต่อไปนี้เพื่อสร้างคอลัมน์ใหม่ที่มีค่าเฉลี่ยเคลื่อนที่ของ “ยอดขาย” สำหรับ 5 งวดก่อนหน้า:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
เราสามารถตรวจสอบได้ด้วยตนเองว่ายอดขายเฉลี่ยต่อเนื่องที่แสดงสำหรับช่วงระยะเวลา 5 เป็นค่าเฉลี่ยของ 5 ช่วงก่อนหน้า:
ค่าเฉลี่ยเคลื่อนที่ในช่วงที่ 5: (61.417+64.900+66.698+64.927+73.720)/5 = 66.33
เราสามารถใช้ไวยากรณ์ที่คล้ายกันในการคำนวณค่าเฉลี่ยเคลื่อนที่ของหลายคอลัมน์:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
นอกจากนี้เรายังสามารถสร้างการลงจุดแบบด่วนโดยใช้ Matplotlib เพื่อเห็นภาพยอดขายรวมเทียบกับค่าเฉลี่ยยอดขายที่เคลื่อนไหวได้:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
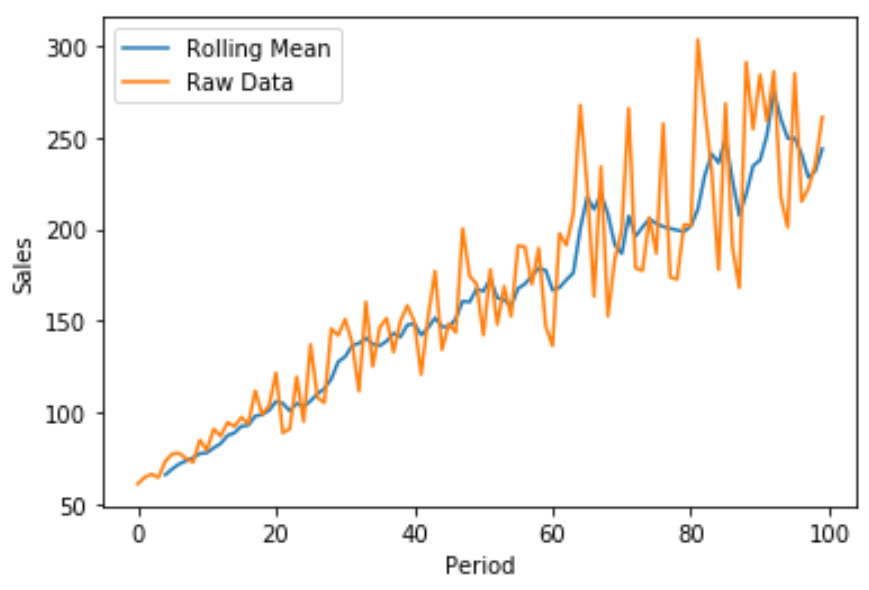
เส้นสีน้ำเงินแสดงยอดขายเฉลี่ยเคลื่อนที่ในช่วง 5 ช่วง และเส้นสีส้มแสดงข้อมูลการขายดิบ
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีการทำงานทั่วไปอื่นๆ ในแพนด้า:
วิธีการคำนวณความสัมพันธ์แบบเลื่อนในแพนด้า
วิธีการคำนวณค่าเฉลี่ยของคอลัมน์ใน Pandas
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม