วิธีการวิเคราะห์ตัวแปรคู่ใน r (พร้อมตัวอย่าง)
คำว่า การวิเคราะห์ไบวาเรียต หมายถึงการวิเคราะห์ตัวแปรสองตัว คุณสามารถจำสิ่งนี้ได้เพราะคำนำหน้า “bi” หมายถึง “สอง”
เป้าหมายของการวิเคราะห์ตัวแปรคู่คือการทำความเข้าใจความสัมพันธ์ระหว่างตัวแปรสองตัว
มีสามวิธีทั่วไปในการวิเคราะห์ตัวแปรคู่:
1. เมฆชี้
2. ค่าสัมประสิทธิ์สหสัมพันธ์
3. การถดถอยเชิงเส้นอย่างง่าย
ตัวอย่างต่อไปนี้สาธิตวิธีดำเนินการวิเคราะห์ไบวาเรียตแต่ละประเภทโดยใช้ชุดข้อมูลต่อไปนี้ซึ่งมีข้อมูลเกี่ยวกับตัวแปรสองตัว: (1) ชั่วโมงที่ใช้ในการศึกษา และ (2) คะแนนทดสอบที่ได้รับจากนักเรียนที่แตกต่างกัน 20 คน:
#create data frame df <- data. frame (hours=c(1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 6, 7, 8), score=c(75, 66, 68, 74, 78, 72, 85, 82, 90, 82, 80, 88, 85, 90, 92, 94, 94, 88, 91, 96)) #view first six rows of data frame head(df) hours score 1 1 75 2 1 66 3 1 68 4 2 74 5 2 78 6 2 72
1. เมฆชี้
เราสามารถใช้ไวยากรณ์ต่อไปนี้เพื่อสร้างแผนภูมิกระจายของชั่วโมงที่ศึกษาเทียบกับเกรดการสอบใน R:
#create scatterplot of hours studied vs. exam score plot(df$hours, df$score, pch= 16 , col=' steelblue ', main=' Hours Studied vs. Exam Score ', xlab=' Hours Studied ', ylab=' Exam Score ')
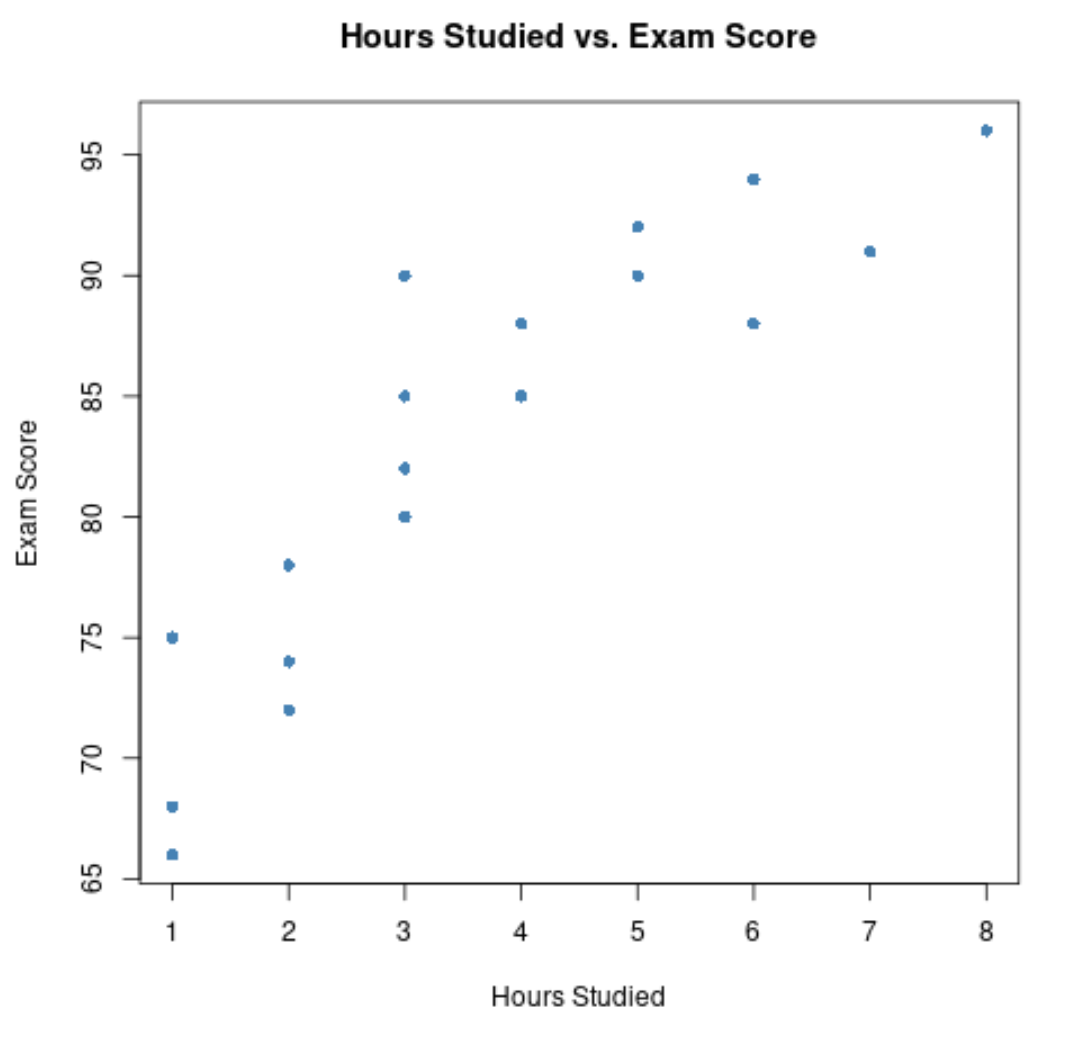
แกน x แสดงชั่วโมงที่เรียน และแกน y แสดงเกรดที่ได้รับจากการสอบ
กราฟแสดงให้เห็นว่ามีความสัมพันธ์เชิงบวกระหว่างตัวแปรทั้งสอง: เมื่อจำนวนชั่วโมงเรียนเพิ่มขึ้น คะแนนการสอบก็มีแนวโน้มที่จะเพิ่มขึ้นเช่นกัน
2. ค่าสัมประสิทธิ์สหสัมพันธ์
ค่าสัมประสิทธิ์สหสัมพันธ์แบบเพียร์สันเป็นวิธีหาปริมาณความสัมพันธ์เชิงเส้นระหว่างตัวแปรสองตัว
เราสามารถใช้ฟังก์ชัน cor() ใน R เพื่อคำนวณค่าสัมประสิทธิ์สหสัมพันธ์แบบเพียร์สันระหว่างตัวแปรสองตัว:
#calculate correlation between hours studied and exam score received
cor(df$hours, df$score)
[1] 0.891306
ค่าสัมประสิทธิ์สหสัมพันธ์กลายเป็น 0.891 .
ค่านี้ใกล้กับ 1 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกที่แข็งแกร่งระหว่างชั่วโมงเรียนและเกรดการสอบ
3. การถดถอยเชิงเส้นอย่างง่าย
การถดถอยเชิงเส้นอย่างง่ายเป็นวิธีการทางสถิติที่เราสามารถใช้เพื่อค้นหาสมการของเส้นตรงที่ “เข้ากับ” ชุดข้อมูลได้ดีที่สุด ซึ่งเราสามารถใช้เพื่อทำความเข้าใจความสัมพันธ์ที่แน่นอนระหว่างตัวแปรสองตัวได้
เราสามารถใช้ฟังก์ชัน lm() ใน R เพื่อให้พอดีกับ แบบจำลองการถดถอยเชิงเส้นอย่างง่าย สำหรับชั่วโมงที่ศึกษาและผลการสอบที่ได้รับ:
#fit simple linear regression model fit <- lm(score ~ hours, data=df) #view summary of model summary(fit) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -6,920 -3,927 1,309 1,903 9,385 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 69.0734 1.9651 35.15 < 2nd-16 *** hours 3.8471 0.4613 8.34 1.35e-07 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 4.171 on 18 degrees of freedom Multiple R-squared: 0.7944, Adjusted R-squared: 0.783 F-statistic: 69.56 on 1 and 18 DF, p-value: 1.347e-07
สมการถดถอยที่ติดตั้งไว้กลายเป็น:
คะแนนสอบ = 69.0734 + 3.8471*(ชั่วโมงเรียน)
สิ่งนี้บอกเราว่าแต่ละชั่วโมงที่เรียนเพิ่มเติมนั้นสัมพันธ์กับคะแนนสอบที่เพิ่มขึ้นโดยเฉลี่ย 3.8471
นอกจากนี้เรายังสามารถใช้สมการถดถอยที่ติดตั้งเพื่อทำนายคะแนนที่นักเรียนจะได้รับตามจำนวนชั่วโมงเรียนทั้งหมด
เช่น นักเรียนที่เรียน 3 ชั่วโมง ควรได้คะแนน 81.6147 :
- คะแนนสอบ = 69.0734 + 3.8471*(ชั่วโมงเรียน)
- คะแนนสอบ = 69.0734 + 3.8471*(3)
- ผลสอบ = 81.6147
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้ให้ข้อมูลเพิ่มเติมเกี่ยวกับการวิเคราะห์ตัวแปรคู่:
ความรู้เบื้องต้นเกี่ยวกับการวิเคราะห์ไบวาเรียต
5 ตัวอย่างข้อมูลไบวาเรียตในชีวิตจริง
ความรู้เบื้องต้นเกี่ยวกับการถดถอยเชิงเส้นอย่างง่าย
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม