วิธีทดสอบความเป็นปกติใน python (4 วิธี)
การทดสอบทางสถิติจำนวนมาก ถือว่า ชุดข้อมูลมีการกระจายตามปกติ
มีสี่วิธีทั่วไปในการตรวจสอบสมมติฐานนี้ใน Python:
1. (วิธีการมองเห็น) สร้างฮิสโตแกรม
- ถ้าฮิสโตแกรมมีรูปร่างประมาณ “ระฆัง” จะถือว่าข้อมูลมีการกระจายตามปกติ
2. (วิธีการมองเห็น) สร้างพล็อต QQ
- หากจุดบนโครงเรื่องอยู่ตามแนวเส้นทแยงมุมโดยประมาณ ก็จะถือว่าข้อมูลมีการกระจายตามปกติ
3. (การทดสอบทางสถิติอย่างเป็นทางการ) ทำการทดสอบชาปิโร-วิลค์
- หากค่า p ของการทดสอบมากกว่า α = 0.05 จะถือว่าข้อมูลมีการกระจายตามปกติ
4. (การทดสอบทางสถิติอย่างเป็นทางการ) ทำการทดสอบ Kolmogorov-Smirnov
- หากค่า p ของการทดสอบมากกว่า α = 0.05 จะถือว่าข้อมูลมีการกระจายตามปกติ
ตัวอย่างต่อไปนี้แสดงวิธีการใช้แต่ละวิธีในทางปฏิบัติ
วิธีที่ 1: สร้างฮิสโตแกรม
รหัสต่อไปนี้แสดงวิธีการสร้างฮิสโตแกรมสำหรับชุดข้อมูลที่เป็นไปตาม การแจกแจงแบบปกติ :
import math
import numpy as np
from scipy. stats import lognorm
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#create histogram to visualize values in dataset
plt. hist (lognorm_dataset, edgecolor=' black ', bins=20)
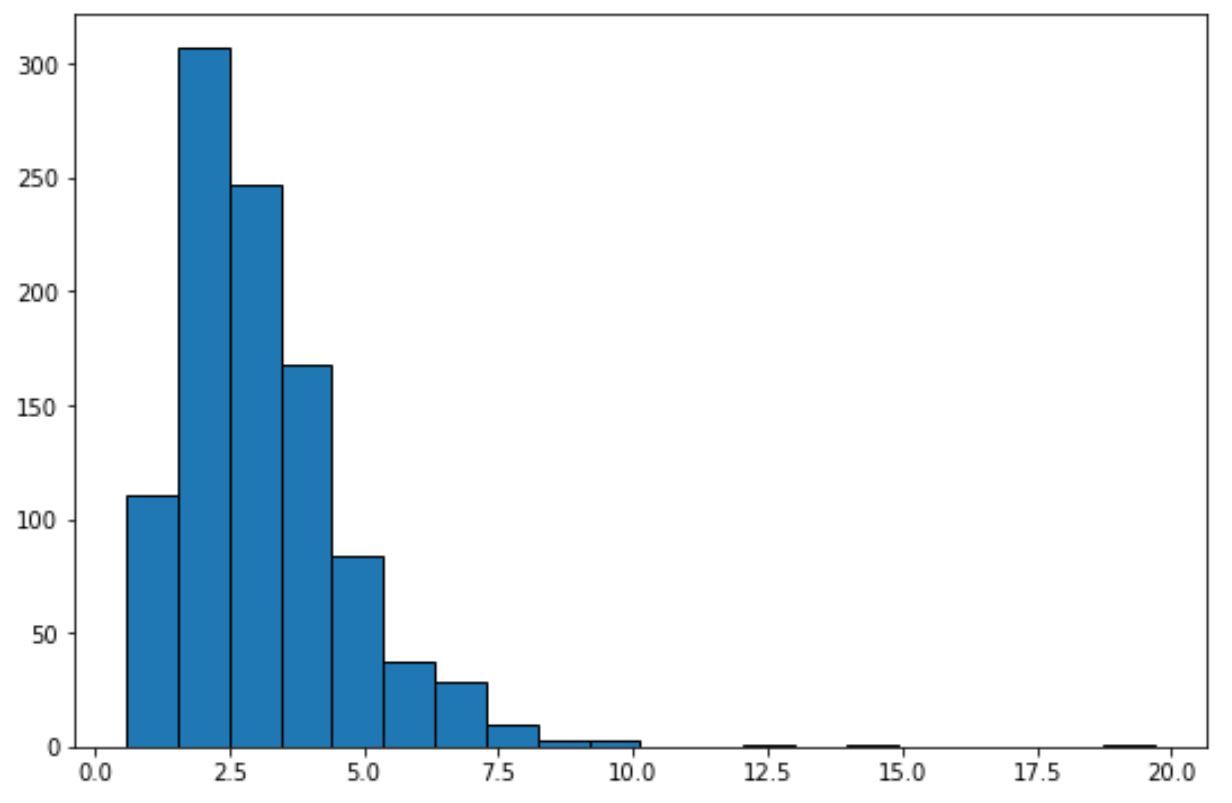
เพียงดูฮิสโตแกรมนี้ เราก็บอกได้เลยว่าชุดข้อมูลไม่แสดง “รูปร่างระฆัง” และไม่ได้กระจายตามปกติ
วิธีที่ 2: สร้างพล็อต QQ
รหัสต่อไปนี้แสดงวิธีการสร้างการลงจุด QQ สำหรับชุดข้อมูลที่เป็นไปตามการแจกแจงแบบบันทึกปกติ:
import math
import numpy as np
from scipy. stats import lognorm
import statsmodels. api as sm
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#create QQ plot with 45-degree line added to plot
fig = sm. qqplot (lognorm_dataset, line=' 45 ')
plt. show ()
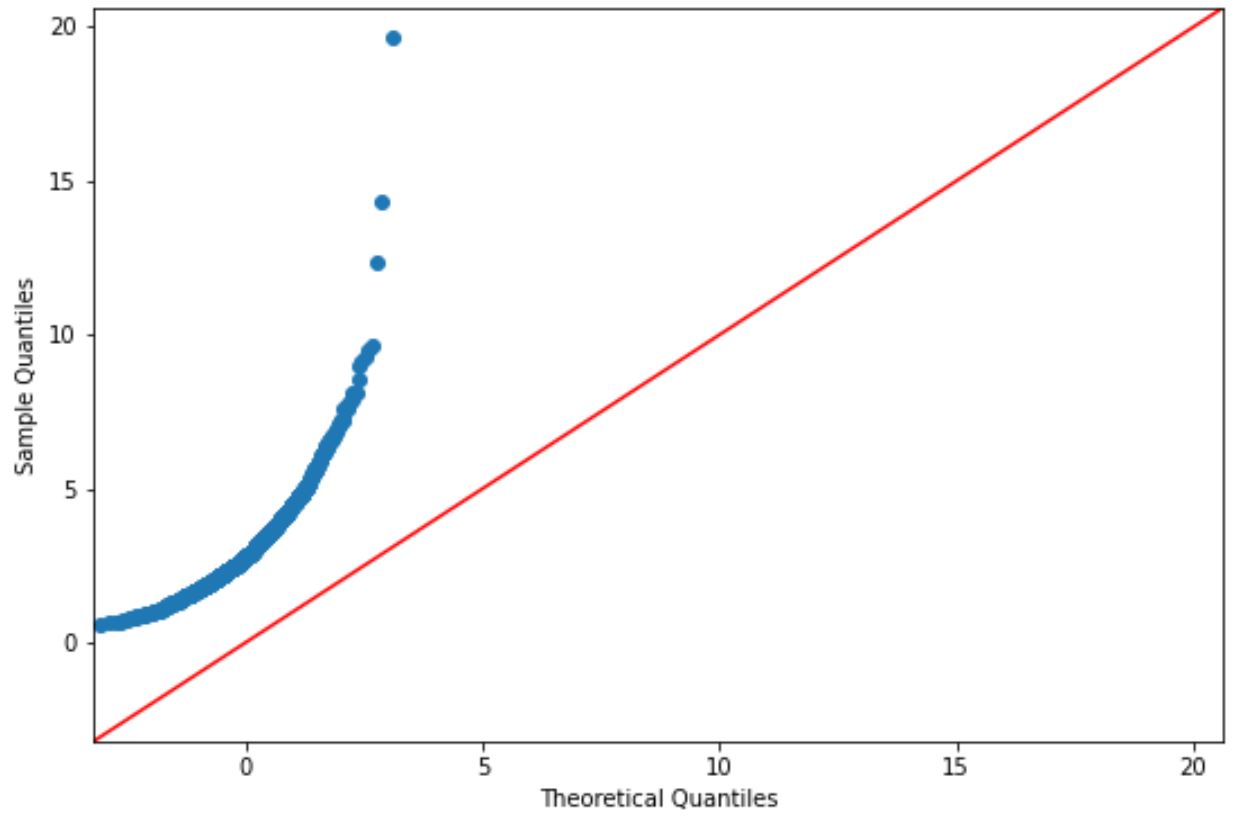
หากจุดลงจุดอยู่ตามแนวเส้นทแยงมุมโดยประมาณ โดยทั่วไปเราจะถือว่าชุดข้อมูลมีการกระจายตามปกติ
อย่างไรก็ตาม จุดบนกราฟนี้ไม่สอดคล้องกับเส้นสีแดงอย่างชัดเจน ดังนั้นเราจึงไม่สามารถสรุปได้ว่าชุดข้อมูลนี้มีการกระจายตามปกติ
สิ่งนี้น่าจะสมเหตุสมผลเนื่องจากเราสร้างข้อมูลโดยใช้ฟังก์ชันการแจกแจงแบบบันทึกปกติ
วิธีที่ 3: ทำการทดสอบ Shapiro-Wilk
รหัสต่อไปนี้แสดงวิธีการดำเนินการ Shapiro-Wilk สำหรับชุดข้อมูลที่เป็นไปตามการแจกแจงแบบล็อกปกติ:
import math
import numpy as np
from scipy.stats import shapiro
from scipy. stats import lognorm
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#perform Shapiro-Wilk test for normality
shapiro(lognorm_dataset)
ShapiroResult(statistic=0.8573324680328369, pvalue=3.880663073872444e-29)
จากผลลัพธ์ เราจะเห็นว่าสถิติการทดสอบคือ 0.857 และค่า p ที่สอดคล้องกันคือ 3.88e-29 (ใกล้กับศูนย์อย่างยิ่ง)
เนื่องจากค่า p น้อยกว่า 0.05 เราจึงปฏิเสธสมมติฐานว่างของการทดสอบชาปิโร-วิลค์
ซึ่งหมายความว่าเรามีหลักฐานเพียงพอที่จะบอกว่าข้อมูลตัวอย่างไม่ได้มาจากการแจกแจงแบบปกติ
วิธีที่ 4: ทำการทดสอบ Kolmogorov-Smirnov
รหัสต่อไปนี้แสดงวิธีดำเนินการทดสอบ Kolmogorov-Smirnov สำหรับชุดข้อมูลที่เป็นไปตามการแจกแจงแบบล็อกปกติ:
import math
import numpy as np
from scipy.stats import kstest
from scipy. stats import lognorm
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#perform Kolmogorov-Smirnov test for normality
kstest(lognorm_dataset, ' norm ')
KstestResult(statistic=0.84125708308077, pvalue=0.0)
จากผลลัพธ์เราจะเห็นว่าสถิติการทดสอบคือ 0.841 และค่า p ที่สอดคล้องกันคือ 0.0
เนื่องจากค่า p น้อยกว่า 0.05 เราจึงปฏิเสธสมมติฐานว่างของการทดสอบ Kolmogorov-Smirnov
ซึ่งหมายความว่าเรามีหลักฐานเพียงพอที่จะบอกว่าข้อมูลตัวอย่างไม่ได้มาจากการแจกแจงแบบปกติ
วิธีจัดการกับข้อมูลที่ไม่ปกติ
หากชุดข้อมูลที่ระบุ ไม่ได้ รับการเผยแพร่ตามปกติ เรามักจะสามารถดำเนินการแปลงอย่างใดอย่างหนึ่งต่อไปนี้เพื่อให้มีการกระจายแบบปกติมากขึ้น:
1. การแปลงบันทึก: แปลงค่า x เป็น log(x)
2. การแปลงรากที่สอง: แปลงค่าของ x เป็น √x
3. การแปลงรูทคิวบ์: แปลงค่าของ x เป็น x 1/3 .
เมื่อทำการแปลงเหล่านี้ ชุดข้อมูลจะมีการกระจายตามปกติมากขึ้น
อ่าน บทช่วยสอนนี้ เพื่อดูวิธีดำเนินการแปลงเหล่านี้ใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม