วิธีดำเนินการผสานแบบหนึ่งต่อกลุ่มใน sas
คุณสามารถใช้ไวยากรณ์ต่อไปนี้เพื่อดำเนินการผสานแบบหนึ่งต่อกลุ่มใน SAS:
data final_data;
merge data_one data_many;
byID ;
run ;
ตัวอย่างนี้สร้างชุดข้อมูลใหม่ชื่อ Final_data โดยการผสานชุดข้อมูลชื่อ data_one และ data_many เข้ากับตัวแปรชื่อ ID
ในชุดข้อมูล data_one ค่า ID ที่ไม่ซ้ำกันแต่ละค่าจะปรากฏเพียงครั้งเดียว
ในชุดข้อมูล data_many ค่า ID ที่ไม่ซ้ำกันแต่ละค่าจะปรากฏขึ้นหลายครั้ง
สิ่งนี้เรียกว่าการรวมแบบหนึ่งต่อกลุ่ม
ตัวอย่างต่อไปนี้แสดงวิธีใช้ไวยากรณ์นี้ในทางปฏิบัติ
ตัวอย่าง: การผสานแบบหนึ่งต่อกลุ่มใน SAS
สมมติว่าเรามีชุดข้อมูลต่อไปนี้ชื่อ data_one ซึ่งมีข้อมูลเกี่ยวกับพนักงานขายของบริษัท:
/*create dataset*/
data data_one;
inputIDGender $;
datalines ;
1 Male
2 Male
3 Female
4 Male
5 Female
;
run ;
/*view dataset*/
proc print data = data_one;
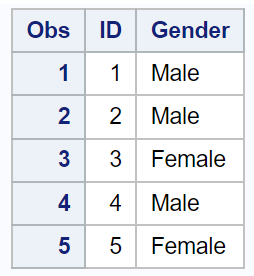
โปรดทราบว่าค่ารหัสที่ไม่ซ้ำกันแต่ละค่าจะปรากฏเพียงครั้งเดียวในชุดข้อมูล
ตอนนี้ สมมติว่าเรามีชุดข้อมูลอื่นชื่อ data_many ซึ่งมีข้อมูลเกี่ยวกับยอดขายของผู้ขายแต่ละรายในสถานที่ต่างๆ:
/*create dataset*/
data data_many;
input Store ID $Sales;
datalines ;
1 to 22
1 B 25
1 C 20
2 to 14
2 B 23
3 to 10
4 to 15
4 B 29
5 to 16
5 C 22
;
run ;
/*view dataset*/
proc print data = data_many;
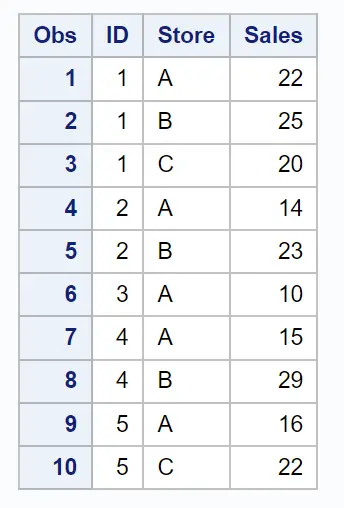
โปรดทราบว่าค่า ID ที่ไม่ซ้ำกันแต่ละค่าจะปรากฏหลายครั้ง
เราสามารถใช้ไวยากรณ์ต่อไปนี้เพื่อดำเนินการผสานแบบหนึ่งต่อกลุ่มโดยใช้ชุดข้อมูลเหล่านี้:
/*create new dataset using one-to-many merge*/
data final_data;
merge data_one data_many;
byID ;
run ;
/*view new dataset*/
proc print data =final_data;
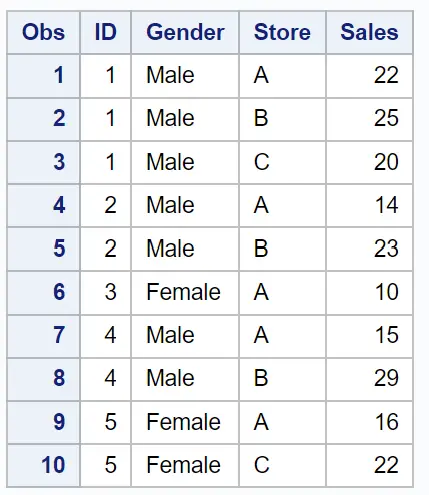
การผสานแบบหนึ่งต่อกลุ่มทำให้เกิดชุดข้อมูลใหม่ที่มีข้อมูลทั้งหมดจากทั้งสองชุดข้อมูล
หมายเหตุ : คุณสามารถค้นหาเอกสารฉบับเต็มสำหรับคำสั่ง การรวม SAS ได้ที่นี่
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีดำเนินการงานทั่วไปอื่นๆ ใน SAS:
วิธีเข้าร่วมซ้ายใน SAS
วิธีการเข้าร่วมภายในใน SAS
วิธีการเข้าร่วมภายนอกใน SAS
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม