การจัดกลุ่ม k-means ใน python: ตัวอย่างทีละขั้นตอน
อัลกอริธึมการจัดกลุ่มที่ใช้กันทั่วไปอย่างหนึ่งใน การเรียนรู้ของเครื่อง เรียกว่า การจัดกลุ่มแบบเคมีน
การจัดกลุ่มแบบเคมีนเป็นเทคนิคที่เราวางแต่ละการสังเกตจากชุดข้อมูลลงในคลัสเตอร์ K กลุ่มใดกลุ่มหนึ่ง
เป้าหมายสุดท้ายคือการมีกระจุกดาว K ซึ่งการสังเกตภายในแต่ละกระจุกจะค่อนข้างคล้ายกัน ในขณะที่การสังเกตในกลุ่มต่าง ๆ จะค่อนข้างแตกต่างกัน
ในทางปฏิบัติ เราใช้ขั้นตอนต่อไปนี้เพื่อดำเนินการจัดกลุ่ม K-mean:
1. เลือกค่าสำหรับ K
- ขั้นแรก เราต้องตัดสินใจว่าเราต้องการระบุคลัสเตอร์จำนวนเท่าใดในข้อมูล บ่อยครั้งที่เราเพียงแค่ต้องทดสอบค่า K ที่แตกต่างกันหลายค่า และวิเคราะห์ผลลัพธ์เพื่อดูว่าจำนวนคลัสเตอร์ใดที่ดูเหมือนจะเหมาะสมที่สุดสำหรับปัญหาที่กำหนด
2. สุ่มกำหนดแต่ละการสังเกตให้กับคลัสเตอร์เริ่มต้น ตั้งแต่ 1 ถึง K
3. ทำตามขั้นตอนต่อไปนี้จนกว่าการกำหนดคลัสเตอร์จะหยุดการเปลี่ยนแปลง
- สำหรับแต่ละกระจุก K ให้คำนวณ จุดศูนย์ถ่วงของกระจุก นี่เป็นเพียงเวกเตอร์ของคุณลักษณะ p- mean สำหรับการสังเกตคลัสเตอร์ที่ k
- กำหนดการสังเกตแต่ละครั้งให้กับคลัสเตอร์ที่มีจุดศูนย์กลางใกล้เคียงที่สุด ในที่นี้ ระยะทาง ที่ใกล้เคียงที่สุด ถูกกำหนดโดยใช้ ระยะทางแบบยุคลิด
ตัวอย่างทีละขั้นตอนต่อไปนี้แสดงวิธีดำเนินการจัดกลุ่ม k-means ใน Python โดยใช้ฟังก์ชัน KMeans จากโมดูล sklearn
ขั้นตอนที่ 1: นำเข้าโมดูลที่จำเป็น
ขั้นแรก เราจะนำเข้าโมดูลทั้งหมดที่เราจำเป็นต้องใช้ในการทำคลัสเตอร์แบบเคมีน:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
ขั้นตอนที่ 2: สร้าง DataFrame
ต่อไป เราจะสร้าง DataFrame ที่มีตัวแปรสามตัวต่อไปนี้สำหรับผู้เล่นบาสเก็ตบอล 20 คน:
- คะแนน
- ช่วย
- ตีกลับ
รหัสต่อไปนี้แสดงวิธีการสร้าง DataFrame แพนด้านี้:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#view first five rows of DataFrame
print ( df.head ())
points assists rebounds
0 18.0 3.0 15
1 NaN 3.0 14
2 19.0 4.0 14
3 14.0 5.0 10
4 14.0 4.0 8
เราจะใช้การจัดกลุ่มเคมีนเพื่อจัดกลุ่มนักแสดงที่คล้ายกันโดยยึดตามตัวชี้วัดทั้งสามนี้
ขั้นตอนที่ 3: ทำความสะอาดและเตรียม DataFrame
จากนั้นเราจะดำเนินการตามขั้นตอนต่อไปนี้:
- ใช้ dropna() เพื่อวางแถวที่มีค่า NaN ในคอลัมน์ใดก็ได้
- ใช้ StandardScaler() เพื่อปรับขนาดตัวแปรแต่ละตัวให้มีค่าเฉลี่ยเป็น 0 และค่าเบี่ยงเบนมาตรฐานเป็น 1
รหัสต่อไปนี้แสดงวิธีการทำเช่นนี้:
#drop rows with NA values in any columns df = df. dropna () #create scaled DataFrame where each variable has mean of 0 and standard dev of 1 scaled_df = StandardScaler(). fit_transform (df) #view first five rows of scaled DataFrame print (scaled_df[:5]) [[-0.86660275 -1.22683918 1.72722524] [-0.72081911 -0.96077767 1.45687694] [-1.44973731 -0.69471616 0.37548375] [-1.44973731 -0.96077767 -0.16521285] [-1.88708823 -0.16259314 1.45687694]]
หมายเหตุ : เราใช้การปรับขนาดเพื่อให้แต่ละตัวแปรมีความสำคัญเท่ากันเมื่อปรับอัลกอริธึมเคมีนให้เหมาะสม มิฉะนั้นตัวแปรที่มีช่วงกว้างที่สุดจะมีอิทธิพลมากเกินไป
ขั้นตอนที่ 4: ค้นหาจำนวนคลัสเตอร์ที่เหมาะสมที่สุด
หากต้องการดำเนินการจัดกลุ่มแบบเคมีนใน Python เราสามารถใช้ฟังก์ชัน KMeans จากโมดูล sklearn ได้
ฟังก์ชันนี้ใช้ไวยากรณ์พื้นฐานต่อไปนี้:
KMeans(init=’random’, n_clusters=8, n_init=10, Random_state=ไม่มี)
ทอง:
- init : ควบคุมเทคนิคการเริ่มต้น
- n_clusters : จำนวนคลัสเตอร์ที่จะวางการสังเกต
- n_init : จำนวนการเริ่มต้นที่จะดำเนินการ ค่าเริ่มต้นคือการรันอัลกอริทึม k-means 10 ครั้ง และส่งคืนอันที่มี SSE ต่ำสุด
- Random_state : ค่าจำนวนเต็มที่คุณสามารถเลือกเพื่อทำให้ผลลัพธ์ของอัลกอริทึมสามารถทำซ้ำได้
อาร์กิวเมนต์ที่สำคัญที่สุดสำหรับฟังก์ชันนี้คือ n_clusters ซึ่งระบุจำนวนคลัสเตอร์ที่จะวางการสังเกต
อย่างไรก็ตาม เราไม่ทราบล่วงหน้าว่ามีคลัสเตอร์กี่คลัสเตอร์ที่เหมาะสมที่สุด ดังนั้นเราจึงจำเป็นต้องสร้างกราฟที่แสดงจำนวนคลัสเตอร์ตลอดจน SSE (ผลรวมของข้อผิดพลาดกำลังสอง) ของแบบจำลอง
โดยทั่วไป เมื่อเราสร้างพล็อตประเภทนี้ เราจะมองหา “หัวเข่า” ซึ่งผลรวมของกำลังสองเริ่ม “โค้งงอ” หรือคลี่คลายลง โดยทั่วไปนี่คือจำนวนคลัสเตอร์ที่เหมาะสมที่สุด
รหัสต่อไปนี้แสดงวิธีสร้างพล็อตประเภทนี้ซึ่งแสดงจำนวนคลัสเตอร์บนแกน x และ SSE บนแกน y:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
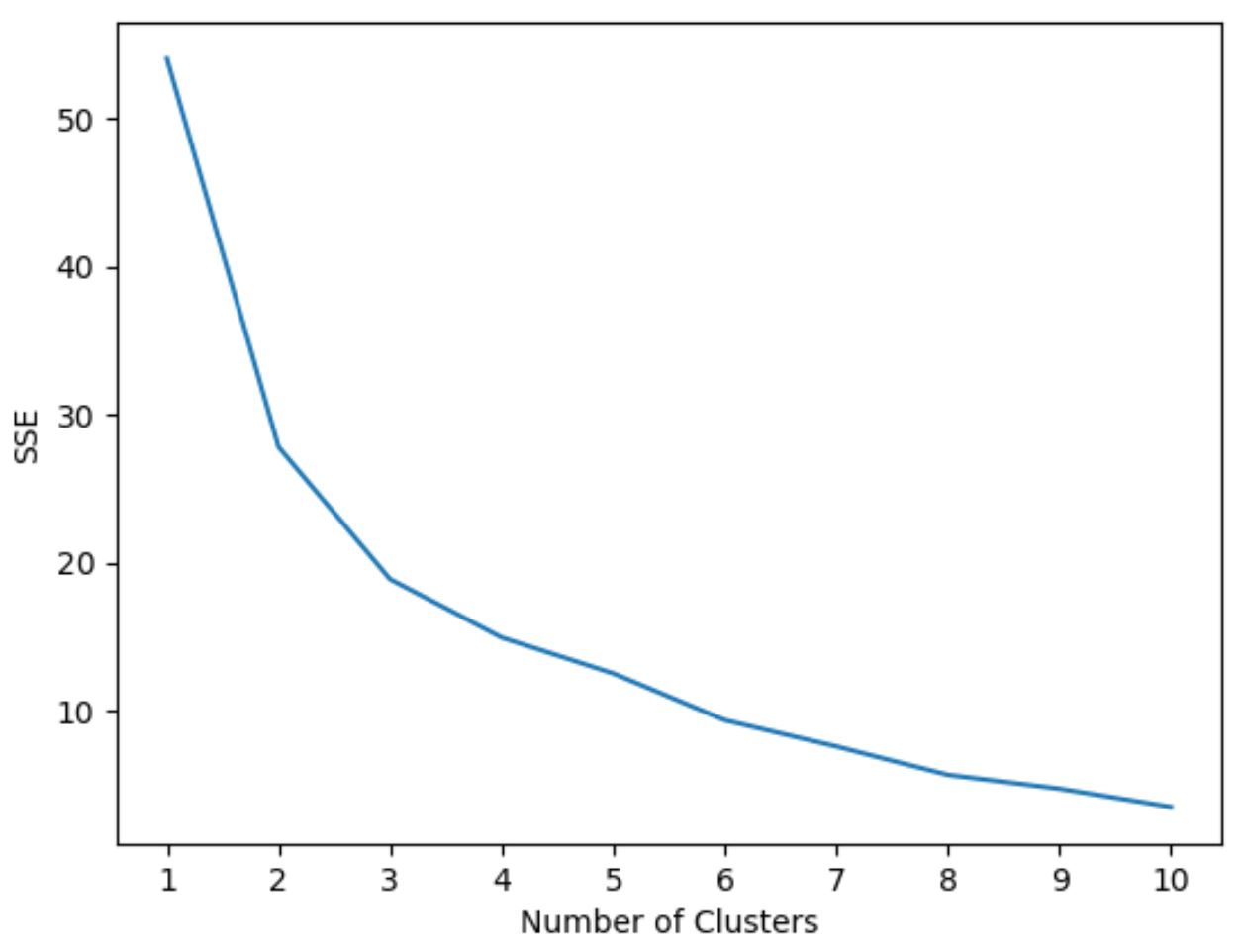
ในกราฟนี้ปรากฏว่ามีการงอหรือ “เข่า” ที่ k = 3 กลุ่ม
ดังนั้น เราจะใช้ 3 คลัสเตอร์เมื่อปรับโมเดลการจัดกลุ่มเคมีนของเราให้เหมาะสมในขั้นตอนถัดไป
หมายเหตุ : ในโลกแห่งความเป็นจริง ขอแนะนำให้ใช้การผสมผสานระหว่างความเชี่ยวชาญด้านพล็อตและโดเมนเพื่อเลือกจำนวนคลัสเตอร์ที่จะใช้
ขั้นตอนที่ 5: ดำเนินการจัดกลุ่ม K-Means ด้วย Optimal K
รหัสต่อไปนี้แสดงวิธีการดำเนินการจัดกลุ่มแบบเคมีนบนชุดข้อมูลโดยใช้ค่าที่เหมาะสมที่สุดสำหรับ k ของ 3:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
ตารางผลลัพธ์จะแสดงการกำหนดคลัสเตอร์สำหรับการสังเกตแต่ละครั้งใน DataFrame
เพื่อให้ตีความผลลัพธ์เหล่านี้ได้ง่ายขึ้น เราสามารถเพิ่มคอลัมน์ลงใน DataFrame ที่แสดงการกำหนดคลัสเตอร์ของผู้เล่นแต่ละคน:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
คอลัมน์ คลัสเตอร์ ประกอบด้วยหมายเลขคลัสเตอร์ (0, 1 หรือ 2) ที่ผู้เล่นแต่ละคนถูกกำหนดไว้
ผู้เล่นที่อยู่ในคลัสเตอร์เดียวกันมีค่าใกล้เคียงกันโดยประมาณสำหรับ คอลัมน์คะแนน ช่วยเหลือ และ รีบาวน์
หมายเหตุ : คุณสามารถดูเอกสารฉบับเต็มเกี่ยวกับฟังก์ชัน KMeans ของ sklearn ได้ที่นี่
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีทำงานทั่วไปอื่นๆ ใน Python:
วิธีการถดถอยเชิงเส้นใน Python
วิธีการดำเนินการถดถอยโลจิสติกใน Python
วิธีดำเนินการตรวจสอบข้าม K-Fold ใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม