วิธีการคำนวณระยะทาง mahalanobis ใน spss
ระยะทางมหาลาโนบิส คือระยะห่างระหว่างจุดสองจุดในพื้นที่หลายตัวแปร มักใช้เพื่อตรวจจับค่าผิดปกติในการวิเคราะห์ทางสถิติที่เกี่ยวข้องกับตัวแปรหลายตัว
บทช่วยสอนนี้จะอธิบายวิธีการคำนวณระยะทาง Mahalanobis ใน SPSS
ตัวอย่าง: ระยะทาง Mahalanobis ใน SPSS
สมมติว่าเรามีชุดข้อมูลต่อไปนี้ที่แสดงคะแนนสอบของนักเรียน 20 คน พร้อมด้วยจำนวนชั่วโมงที่พวกเขาใช้เวลาเรียน จำนวนข้อสอบฝึกหัดที่สอบ และเกรดปัจจุบันในหลักสูตร:
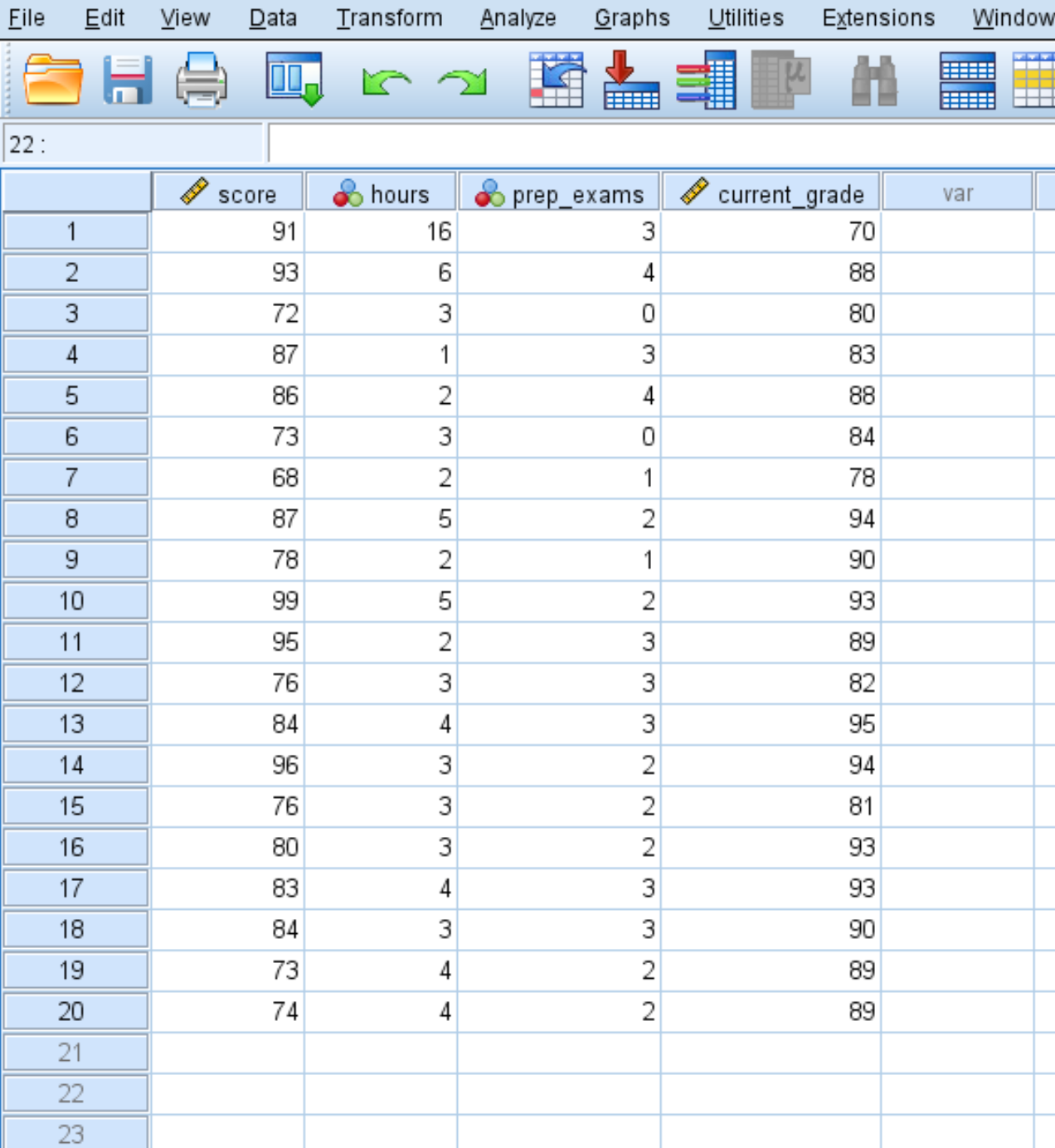
เราสามารถใช้ขั้นตอนต่อไปนี้เพื่อคำนวณระยะทางมหาลาโนบิสสำหรับการสังเกตแต่ละครั้งในชุดข้อมูลเพื่อพิจารณาว่ามีค่าผิดปกติหลายตัวแปรหรือไม่
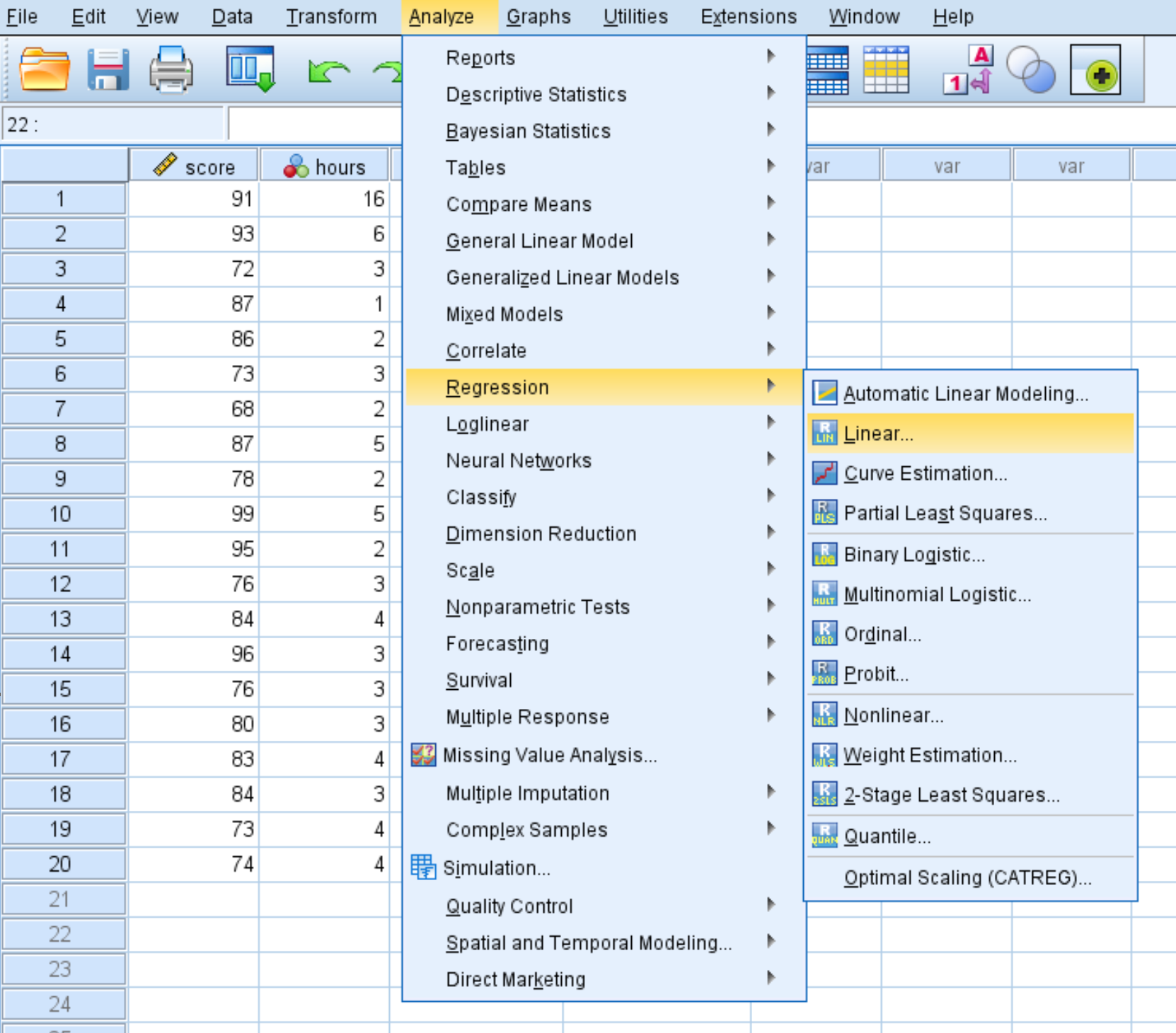
ขั้นตอนที่ 1: เลือกตัวเลือกการถดถอยเชิงเส้น
คลิกแท็บ วิเคราะห์ จากนั้นคลิก Regression จากนั้นคลิก Linear :
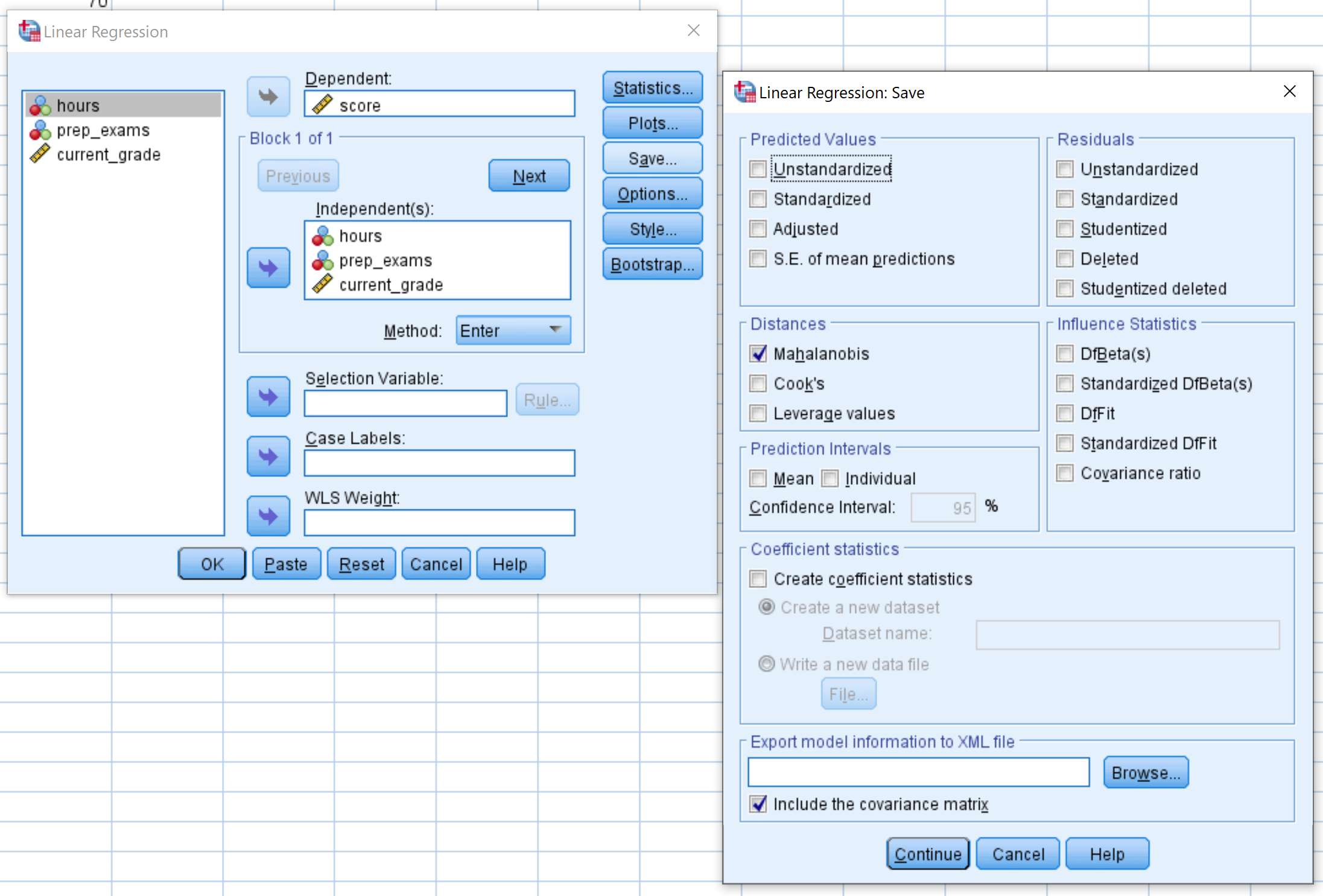
ขั้นตอนที่ 2: เลือกตัวเลือก Mahalanobis
ลาก คะแนน ตัวแปรการตอบสนองลงในกล่องที่มีข้อความว่าขึ้นอยู่กับ ลากตัวแปรทำนายอีกสามตัวลงในช่องที่มีข้อความว่า Independent(s) จากนั้นคลิกปุ่ม บันทึก ในหน้าต่างใหม่ที่ปรากฏขึ้น ตรวจสอบให้แน่ใจว่าได้ทำเครื่องหมายในช่องถัดจาก มหาลาโนบิส แล้ว จากนั้นคลิก ดำเนินการต่อ จากนั้นคลิก ตกลง
เมื่อคุณคลิก ตกลง ระยะทางของมหาลาโนบิสสำหรับการสังเกตแต่ละครั้งในชุดข้อมูลจะปรากฏในคอลัมน์ใหม่ชื่อ MAH_1 :
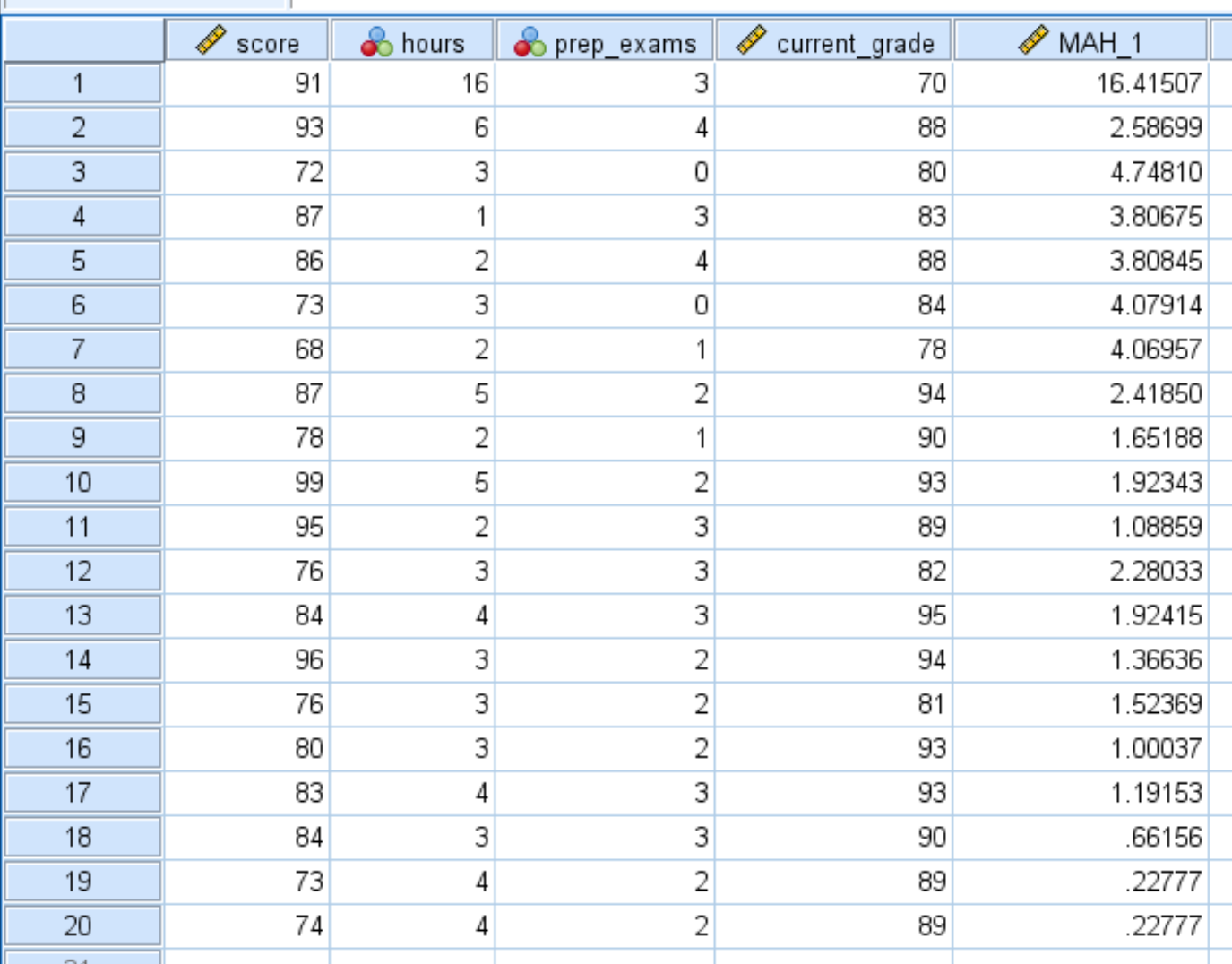
เราจะเห็นได้ว่าระยะทางบางระยะทางไกลกว่าระยะทางอื่นมาก เพื่อพิจารณาว่าระยะทางใดๆ มีนัยสำคัญทางสถิติหรือไม่ เราจำเป็นต้องคำนวณค่า p ของพวกมัน
ขั้นตอนที่ 3: คำนวณค่า p ของระยะทาง Mahalanobis แต่ละระยะ
คลิกแท็บ การแปลง จากนั้น คลิกคำนวณตัวแปร
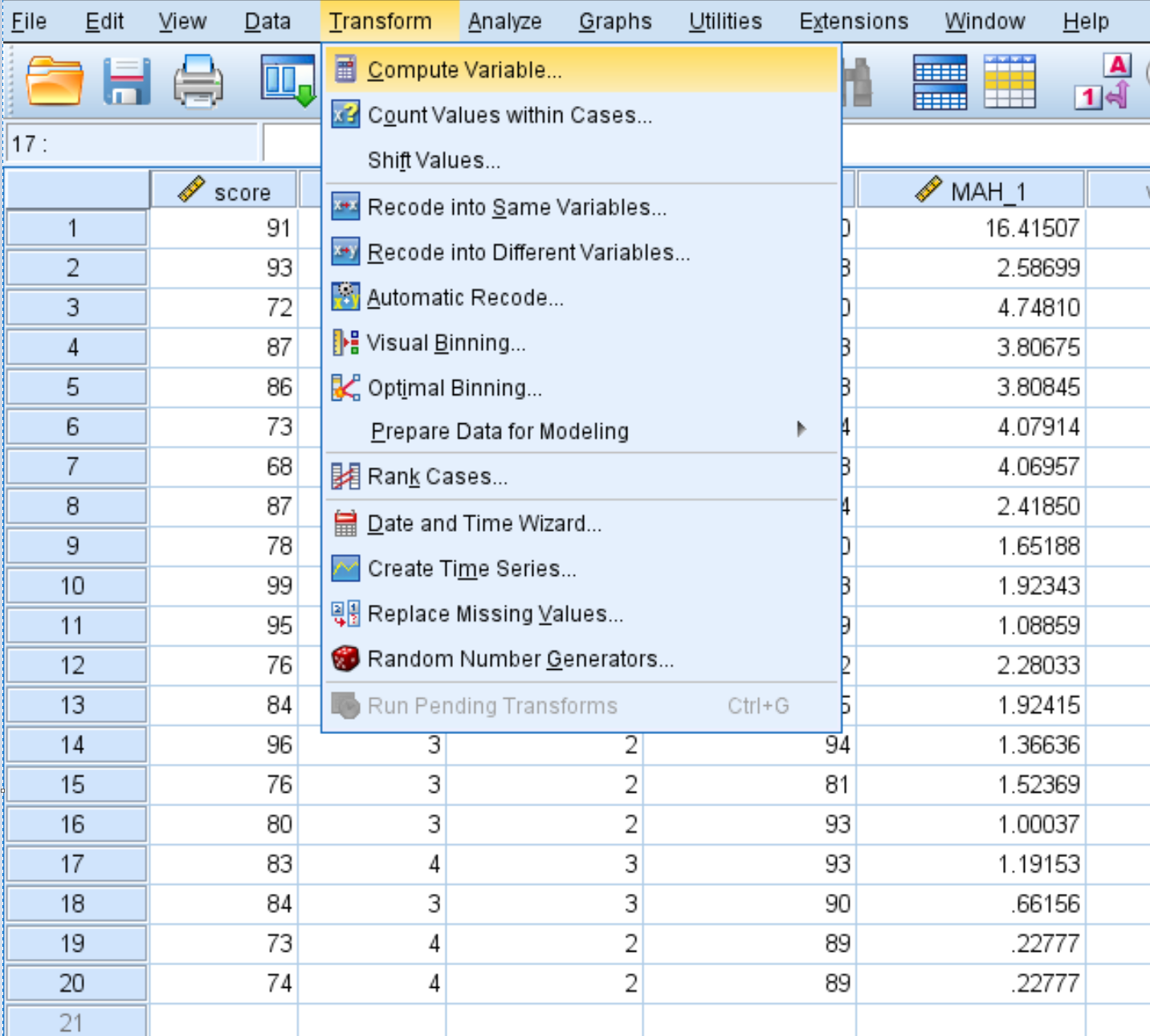
ในกล่อง ตัวแปรเป้าหมาย ให้เลือกชื่อใหม่สำหรับตัวแปรที่คุณกำลังสร้าง เรานึกถึง “คุณค่า” ในกล่อง นิพจน์ตัวเลข ให้ป้อนข้อมูลต่อไปนี้:
1 – CDF.CHISQ(MAH_1, 3)
จากนั้นคลิก ตกลง
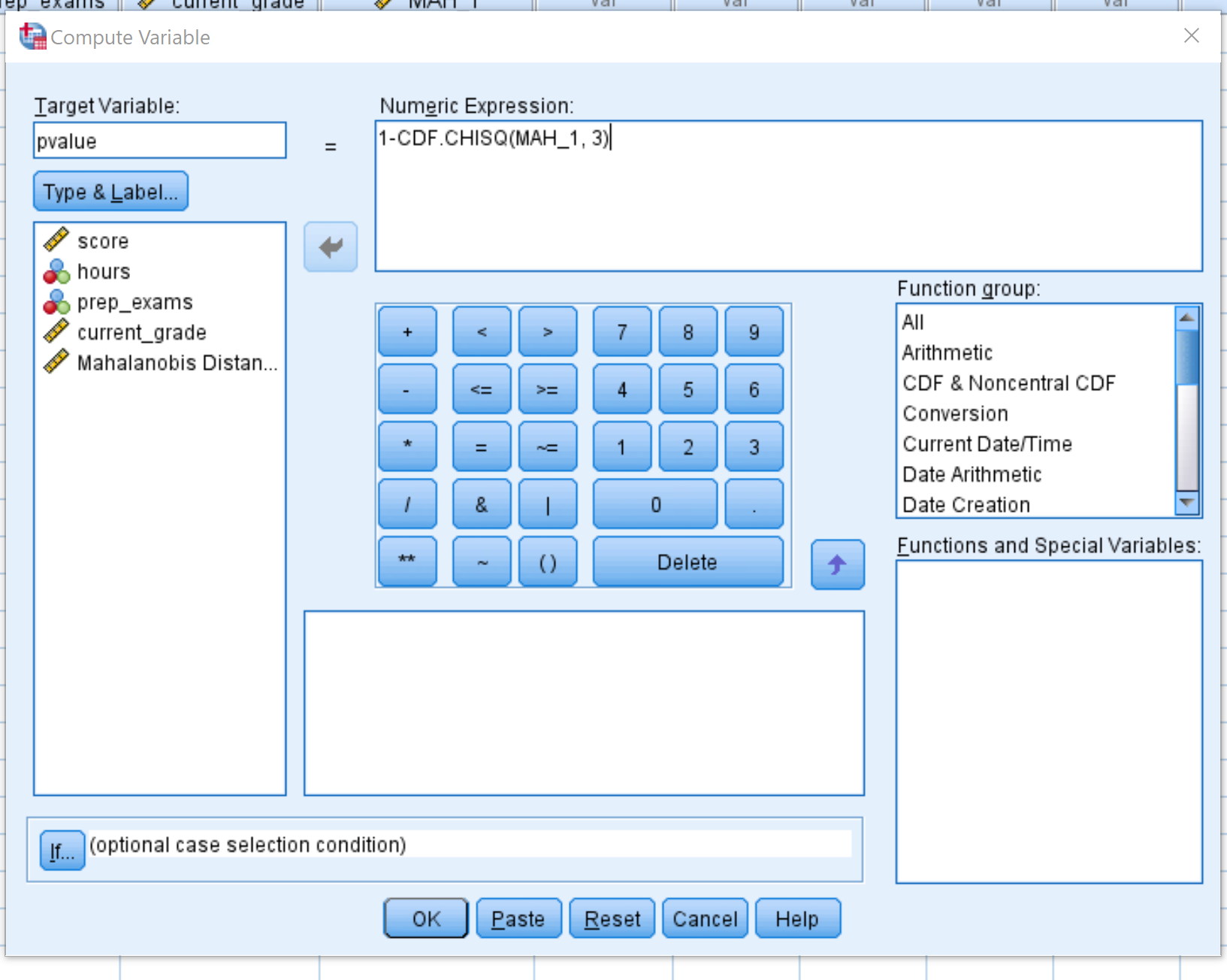
สิ่งนี้จะสร้างค่า p ที่สอดคล้องกับค่าไคสแควร์โดยมีดีกรีอิสระ 3 องศา เราใช้ระดับความเป็นอิสระ 3 ระดับเนื่องจากมีตัวแปรทำนาย 3 ตัวในแบบจำลองการถดถอยของเรา
ขั้นตอนที่ 4: ตีความค่า p
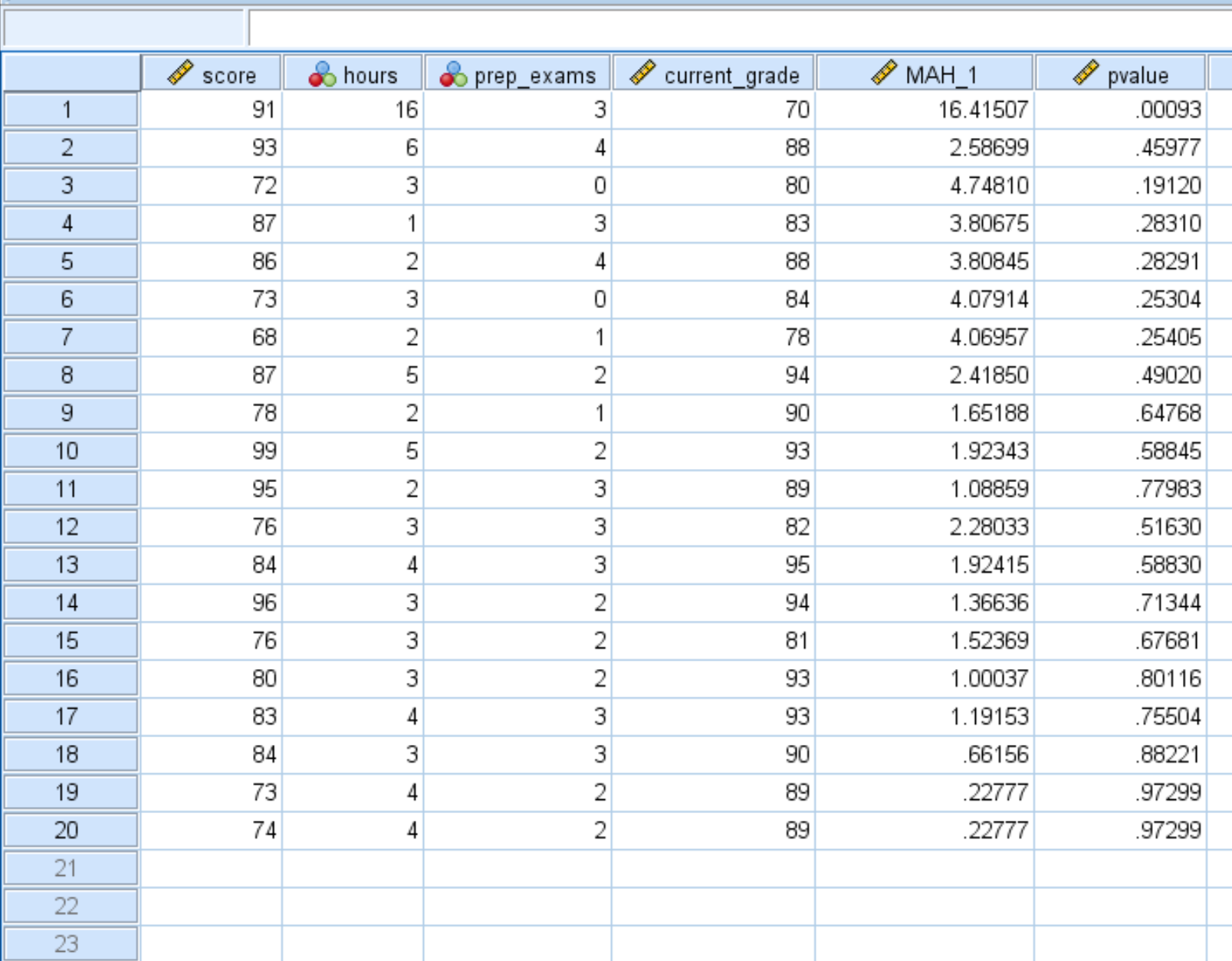
เมื่อคุณคลิก ตกลง ค่า p สำหรับแต่ละระยะทางของมหาลาโนบิสจะแสดงในคอลัมน์ใหม่:
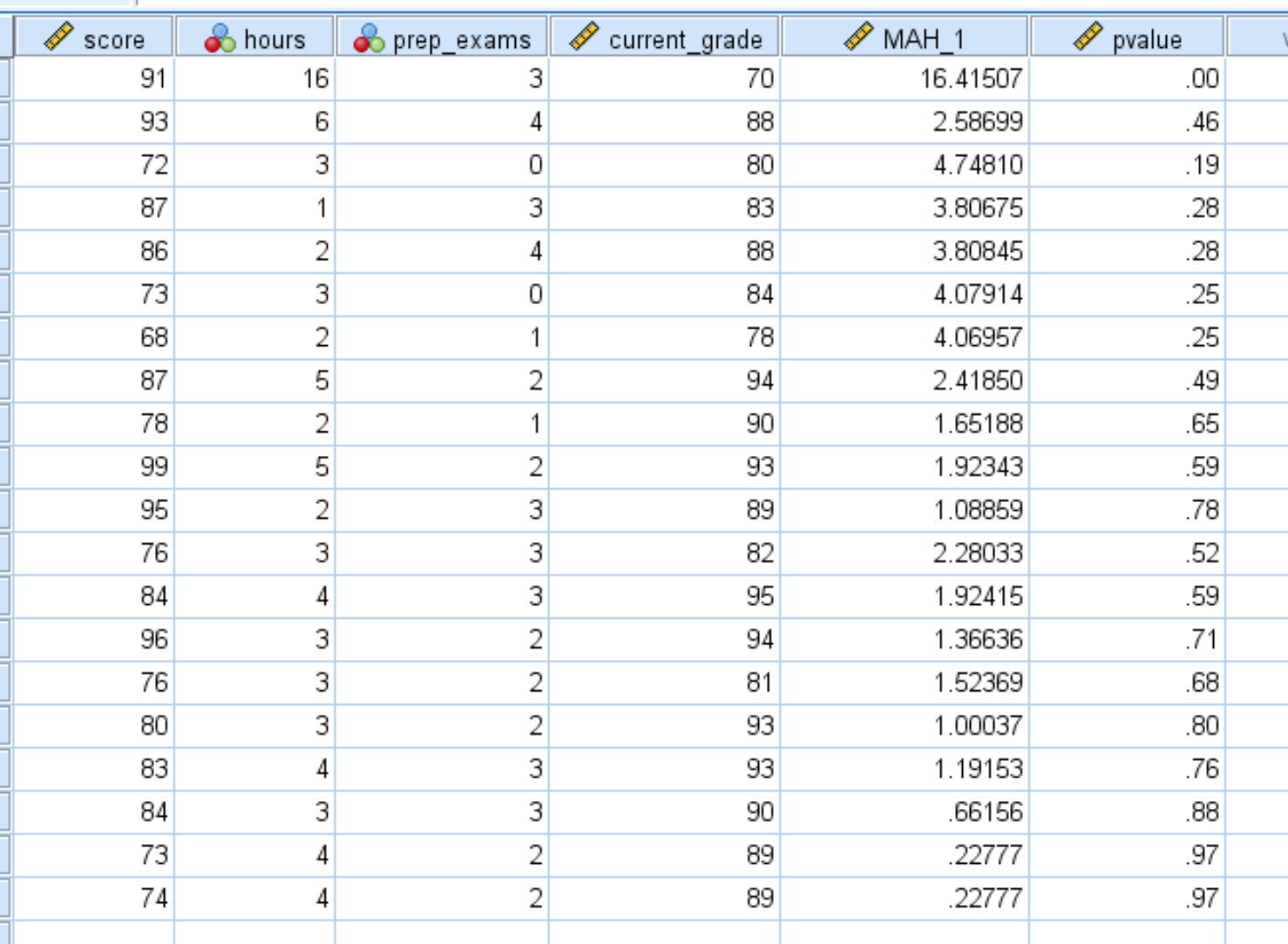
ตามค่าเริ่มต้น SPSS จะแสดงเฉพาะค่า p ที่มีทศนิยมสองตำแหน่งเท่านั้น คุณสามารถเพิ่มจำนวนตำแหน่งทศนิยมได้โดยการคลิก แสดง ตัวแปร ที่ด้านล่างของ SPSS และเพิ่มจำนวนในคอลัมน์ ตำแหน่ง ทศนิยม :
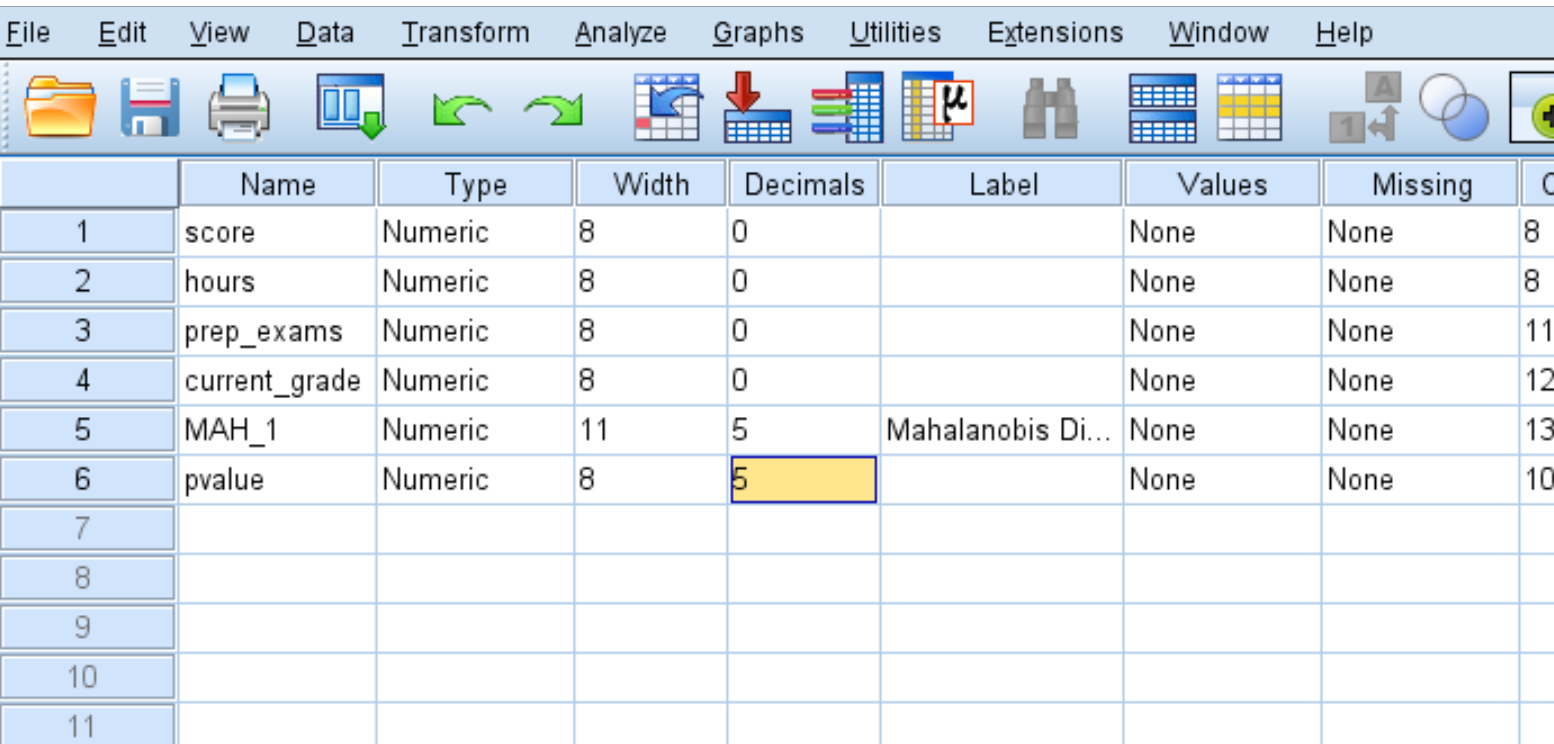
เมื่อคุณกลับไปที่ มุมมองข้อมูล คุณจะเห็นค่า p แต่ละค่าที่แสดงเป็นทศนิยม 5 ตำแหน่ง ค่า p ใดๆ ที่น้อยกว่า 0.001 ถือเป็นค่าผิดปกติ
เราจะเห็นได้ว่าการสังเกตครั้งแรกเป็นเพียงค่าผิดปกติในชุดข้อมูลเนื่องจากมีค่า p น้อยกว่า 0.001:
วิธีจัดการกับค่าผิดปกติ
หากมีค่าผิดปกติในข้อมูลของคุณ คุณจะมีหลายตัวเลือก:
1. ตรวจสอบให้แน่ใจว่าค่าผิดปกติไม่ได้เป็นผลมาจากข้อผิดพลาดในการป้อนข้อมูล
บางครั้งบุคคลเพียงแต่กรอกค่าข้อมูลที่ไม่ถูกต้องในขณะที่บันทึกข้อมูล หากมีค่าผิดปกติ ให้ตรวจสอบก่อนว่าค่าข้อมูลถูกป้อนอย่างถูกต้องและไม่ใช่ข้อผิดพลาด
2. ถอดค่าผิดปกติออก
หากค่านั้นเป็นค่าผิดปกติจริงๆ คุณสามารถเลือกที่จะลบค่านั้นออกได้หากจะมีผลกระทบสำคัญต่อการวิเคราะห์โดยรวมของคุณ เพียงอย่าลืมพูดถึงในรายงานหรือการวิเคราะห์ขั้นสุดท้ายของคุณว่าคุณได้ลบค่าผิดปกติออก
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม