วิธีการดำเนินการถดถอยเชิงเส้นอย่างง่ายใน r (ทีละขั้นตอน)
การถดถอยเชิงเส้นอย่างง่าย เป็นเทคนิคที่เราสามารถใช้เพื่อทำความเข้าใจความสัมพันธ์ระหว่าง ตัวแปรอธิบาย ตัวเดียวและ ตัวแปรตอบสนอง ตัวเดียว
โดยสรุป เทคนิคนี้จะค้นหาบรรทัดที่ “เหมาะสม” กับข้อมูลมากที่สุดและใช้รูปแบบต่อไปนี้:
ŷ = ข 0 + ข 1 x
ทอง:
- ŷ : ค่าตอบกลับโดยประมาณ
- b 0 : ต้นกำเนิดของเส้นถดถอย
- b 1 : ความชันของเส้นถดถอย
สมการนี้สามารถช่วยให้เราเข้าใจความสัมพันธ์ระหว่างตัวแปรอธิบายและตัวแปรตอบสนอง และ (สมมติว่ามีนัยสำคัญทางสถิติ) สามารถใช้เพื่อทำนายค่าของตัวแปรตอบสนองโดยพิจารณาจากค่าของตัวแปรอธิบายได้
บทช่วยสอนนี้ให้คำอธิบายทีละขั้นตอนเกี่ยวกับวิธีการถดถอยเชิงเส้นอย่างง่ายใน R
ขั้นตอนที่ 1: โหลดข้อมูล
สำหรับตัวอย่างนี้ เราจะสร้างชุดข้อมูลปลอมที่มีตัวแปรสองตัวต่อไปนี้สำหรับนักเรียน 15 คน:
- จำนวนชั่วโมงเรียนทั้งหมดสำหรับการสอบบางประเภท
- ผลสอบ
เราจะพยายามปรับโมเดลการถดถอยเชิงเส้นอย่างง่ายโดยใช้ ชั่วโมง เป็นตัวแปรอธิบายและ ผลการทดสอบ เป็นตัวแปรตอบสนอง
รหัสต่อไปนี้แสดงวิธีสร้างชุดข้อมูลปลอมใน R:
#create dataset df <- data.frame(hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #view first six rows of dataset head(df) hours score 1 1 64 2 2 66 3 4 76 4 5 73 5 5 74 6 6 81 #attach dataset to make it more convenient to work with attach(df)
ขั้นตอนที่ 2: แสดงภาพข้อมูล
ก่อนที่จะปรับโมเดลการถดถอยเชิงเส้นอย่างง่าย เราต้องแสดงภาพข้อมูลก่อนจึงจะเข้าใจได้
อันดับแรก เราต้องการให้แน่ใจว่าความสัมพันธ์ระหว่าง ชั่วโมง และ คะแนน นั้นเป็นเส้นตรงโดยประมาณ เนื่องจากนี่เป็น สมมติฐานที่สำคัญ ของการถดถอยเชิงเส้นอย่างง่าย เราสามารถสร้าง Scatterplot ง่ายๆ เพื่อให้เห็นภาพความสัมพันธ์ระหว่างตัวแปรทั้งสอง:
scatter.smooth(hours, score, main=' Hours studied vs. Exam Score ')
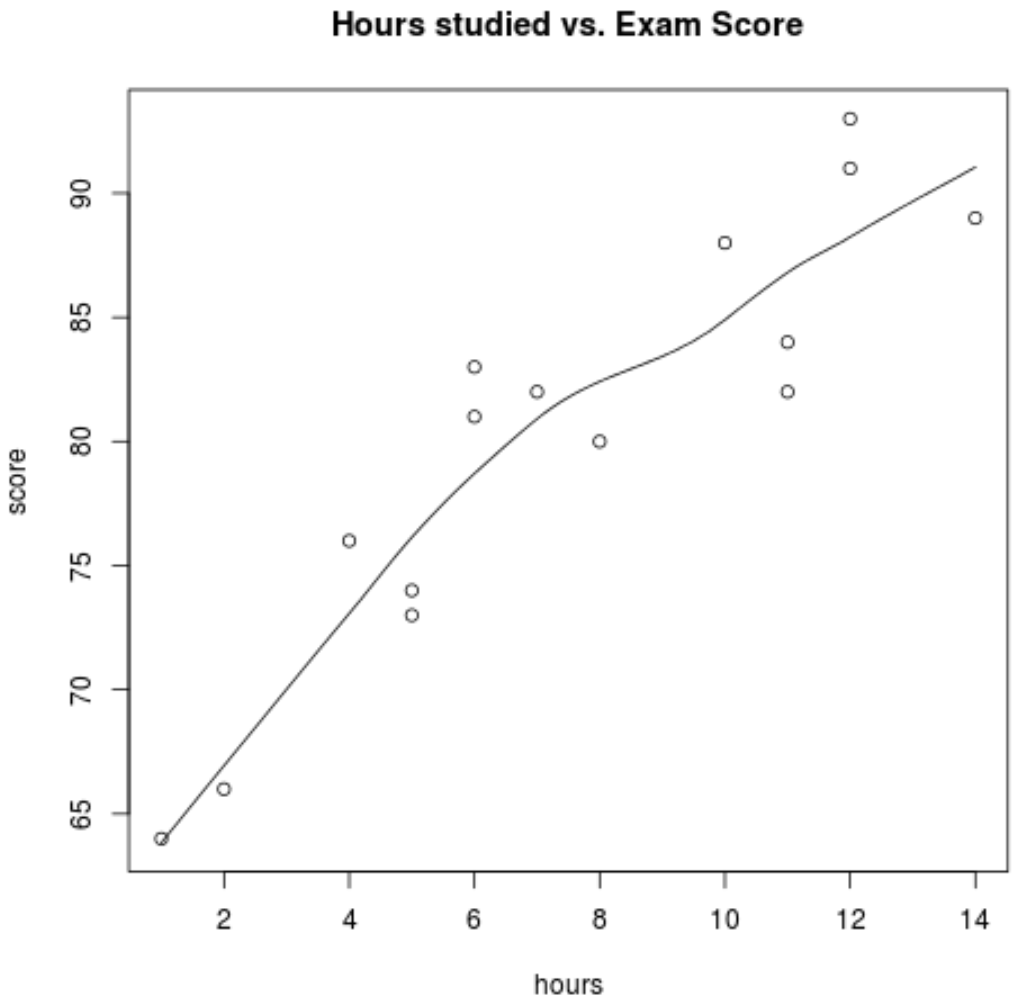
จากกราฟเราจะเห็นว่าความสัมพันธ์มีลักษณะเป็นเส้นตรง เมื่อ จำนวนชั่วโมง เพิ่มขึ้น คะแนน ก็มีแนวโน้มที่จะเพิ่มขึ้นเป็นเส้นตรงเช่นกัน
จากนั้นเราสามารถสร้าง boxplot เพื่อให้เห็นภาพการกระจายผลการสอบและตรวจสอบ ค่าผิดปกติ ตามค่าเริ่มต้น R จะกำหนดให้การสังเกตเป็นค่าผิดปกติหากมีค่าเป็น 1.5 เท่าของช่วงระหว่างควอไทล์เหนือควอไทล์ที่ 3 (Q3) หรือ 1.5 เท่าของช่วงระหว่างควอไทล์ที่ต่ำกว่าควอร์ไทล์ที่ 1 (Q1)
หากการสังเกตนั้นผิดปกติ วงกลมเล็กๆ จะปรากฏขึ้นใน boxplot:
boxplot(score)
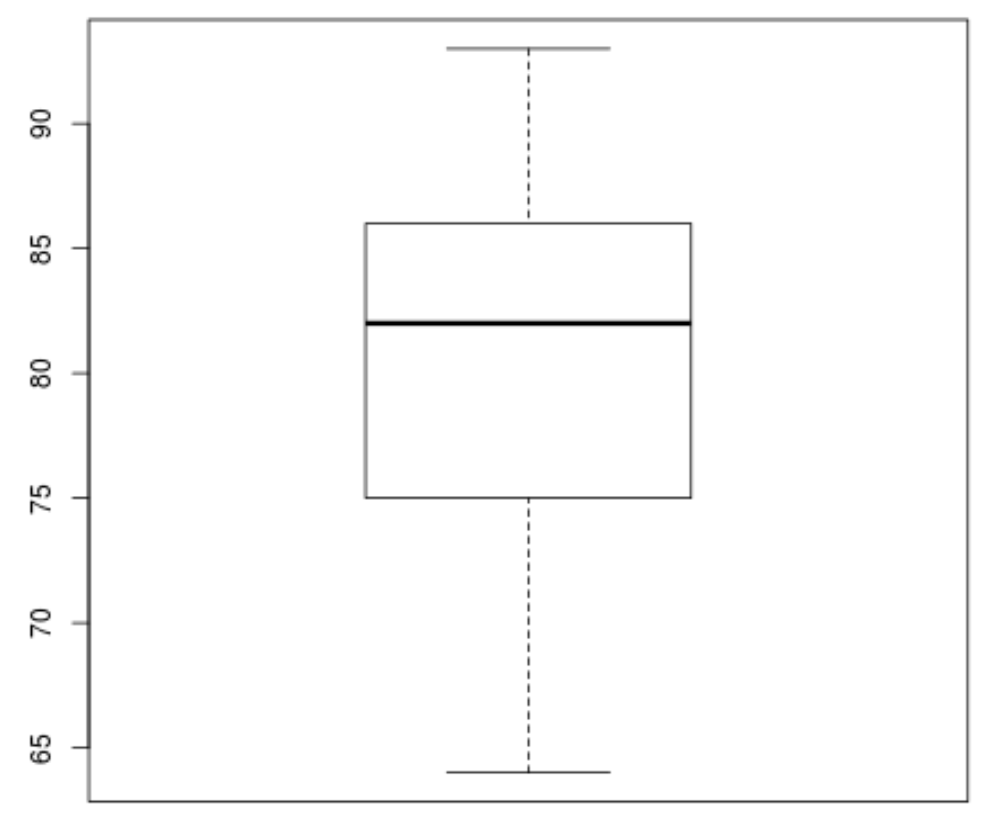
ไม่มีวงกลมเล็กๆ ใน boxplot ซึ่งหมายความว่าไม่มีค่าผิดปกติในชุดข้อมูลของเรา
ขั้นตอนที่ 3: ทำการถดถอยเชิงเส้นอย่างง่าย
เมื่อเราได้รับการยืนยันแล้วว่าความสัมพันธ์ระหว่างตัวแปรของเราเป็นแบบเส้นตรงและไม่มีค่าผิดปกติ เราสามารถดำเนินการสร้างแบบจำลองการถดถอยเชิงเส้นอย่างง่ายโดยใช้ ชั่วโมง เป็นตัวแปรอธิบาย และ ใช้คะแนน เป็นตัวแปรตอบสนอง:
#fit simple linear regression model model <- lm(score~hours) #view model summary summary(model) Call: lm(formula = score ~ hours) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
จากสรุปแบบจำลอง เราจะเห็นว่าสมการถดถอยที่ติดตั้งคือ:
คะแนน = 65.334 + 1.982*(ชั่วโมง)
ซึ่งหมายความว่าแต่ละชั่วโมงที่เรียนเพิ่มเติมจะสัมพันธ์กับคะแนนสอบเฉลี่ยที่เพิ่มขึ้น 1,982 คะแนน และค่าเดิมที่ 65,334 บอกเราถึงคะแนนสอบเฉลี่ยที่คาดหวังสำหรับนักเรียนที่เรียนเป็นเวลา 0 ชั่วโมง
นอกจากนี้เรายังสามารถใช้สมการนี้เพื่อค้นหาคะแนนสอบที่คาดหวังโดยพิจารณาจากจำนวนชั่วโมงที่นักเรียนเรียน เช่น นักเรียนที่เรียน 10 ชั่วโมง ควรได้คะแนนสอบ 85.15 :
คะแนน = 65.334 + 1.982*(10) = 85.15
ต่อไปนี้เป็นวิธีการตีความสรุปแบบจำลองที่เหลือ:
- Pr(>|t|): นี่คือค่า p ที่เกี่ยวข้องกับค่าสัมประสิทธิ์แบบจำลอง เนื่องจากค่า p สำหรับ ชั่วโมง (2.25e-06) น้อยกว่า 0.05 อย่างมีนัยสำคัญ เราจึงสามารถพูดได้ว่ามีความสัมพันธ์ที่มีนัยสำคัญทางสถิติระหว่าง ชั่วโมง และ คะแนน
- ค่า R-squared หลายตัว: ตัวเลขนี้บอกเราว่าเปอร์เซ็นต์ของความแปรผันของคะแนนสอบสามารถอธิบายได้ด้วยจำนวนชั่วโมงที่เรียน โดยทั่วไป ยิ่งค่า R-squared ของแบบจำลองการถดถอยมีค่ามากเท่าใด ตัวแปรอธิบายก็จะสามารถทำนายค่าของตัวแปรตอบสนองได้ดีขึ้นเท่านั้น ในกรณีนี้ 83.1% ของความแปรผันของคะแนนสามารถอธิบายได้ด้วยจำนวนชั่วโมงที่ศึกษา
- ข้อผิดพลาดมาตรฐานที่เหลือ: นี่คือระยะห่างเฉลี่ยระหว่างค่าที่สังเกตได้และเส้นการถดถอย ยิ่งค่านี้ต่ำลง เส้นการถดถอยก็จะยิ่งสอดคล้องกับข้อมูลที่สังเกตได้มากขึ้นเท่านั้น ในกรณีนี้ คะแนนเฉลี่ยที่สังเกตได้ในการสอบจะเบี่ยงเบนไป 3,641 คะแนน จากคะแนนที่ทำนายด้วยเส้นถดถอย
- สถิติ F และค่า p: สถิติ F ( 63.91 ) และค่า p ที่สอดคล้องกัน ( 2.253e-06 ) บอกเราถึงความสำคัญโดยรวมของแบบจำลองการถดถอย กล่าวคือ ตัวแปรอธิบายในแบบจำลองมีประโยชน์ในการอธิบายการเปลี่ยนแปลงหรือไม่ . ในตัวแปรตอบสนอง เนื่องจากค่า p ในตัวอย่างนี้น้อยกว่า 0.05 แบบจำลองของเราจึงมีนัยสำคัญทางสถิติ และ ชั่วโมง จึงถือว่ามีประโยชน์ในการอธิบายความแปรผันของ คะแนน
ขั้นตอนที่ 4: สร้างแปลงที่เหลือ
หลังจากปรับแบบจำลองการถดถอยเชิงเส้นอย่างง่ายเข้ากับข้อมูลแล้ว ขั้นตอนสุดท้ายคือการสร้างแปลงส่วนที่เหลือ
ข้อสันนิษฐานสำคัญประการหนึ่งของการถดถอยเชิงเส้นคือส่วนที่เหลือของแบบจำลองการถดถอยจะมีการกระจายตามปกติโดยประมาณและเป็น โฮโมสซิดาสติก ในแต่ละระดับของตัวแปรอธิบาย หากไม่เป็นไปตามสมมติฐานเหล่านี้ ผลลัพธ์ของแบบจำลองการถดถอยของเราอาจทำให้เข้าใจผิดหรือไม่น่าเชื่อถือ
เพื่อตรวจสอบว่าเป็นไปตามสมมติฐานเหล่านี้ เราสามารถสร้างแปลงที่เหลือต่อไปนี้:
แผนภาพค่าคงเหลือเทียบกับค่าที่พอดี: แผนภาพนี้มีประโยชน์สำหรับการยืนยันความเป็นเนื้อเดียวกัน แกน x จะแสดงค่าที่พอดี และแกน y จะแสดงค่าคงเหลือ ตราบใดที่ส่วนที่เหลือปรากฏว่ามีการกระจายแบบสุ่มและสม่ำเสมอทั่วทั้งกราฟรอบๆ ค่าศูนย์ เราสามารถสรุปได้ว่าความเป็นเนื้อเดียวกันจะไม่ถูกละเมิด:
#define residuals res <- resid(model) #produce residual vs. fitted plot plot(fitted(model), res) #add a horizontal line at 0 abline(0,0)
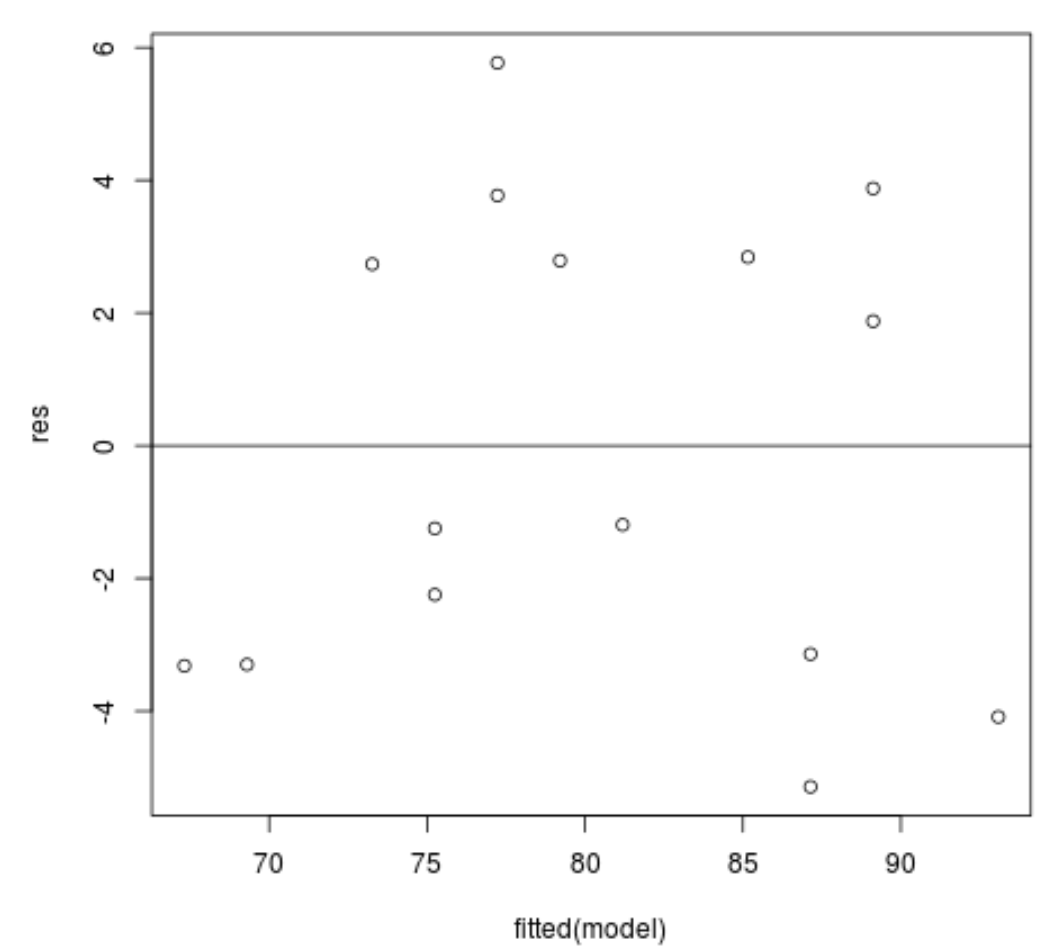
ส่วนที่เหลือดูเหมือนจะกระจัดกระจายแบบสุ่มรอบๆ ศูนย์ และไม่มีรูปแบบที่เห็นได้ชัดเจน ดังนั้นจึงเป็นไปตามสมมติฐานนี้
พล็อต QQ: พล็อตนี้มีประโยชน์ในการพิจารณาว่าส่วนที่เหลือเป็นไปตามการแจกแจงแบบปกติหรือไม่ หากค่าข้อมูลในพล็อตเป็นเส้นตรงประมาณ 45 องศา แสดงว่าข้อมูลมีการกระจายตามปกติ:
#create QQ plot for residuals qqnorm(res) #add a straight diagonal line to the plot qqline(res)
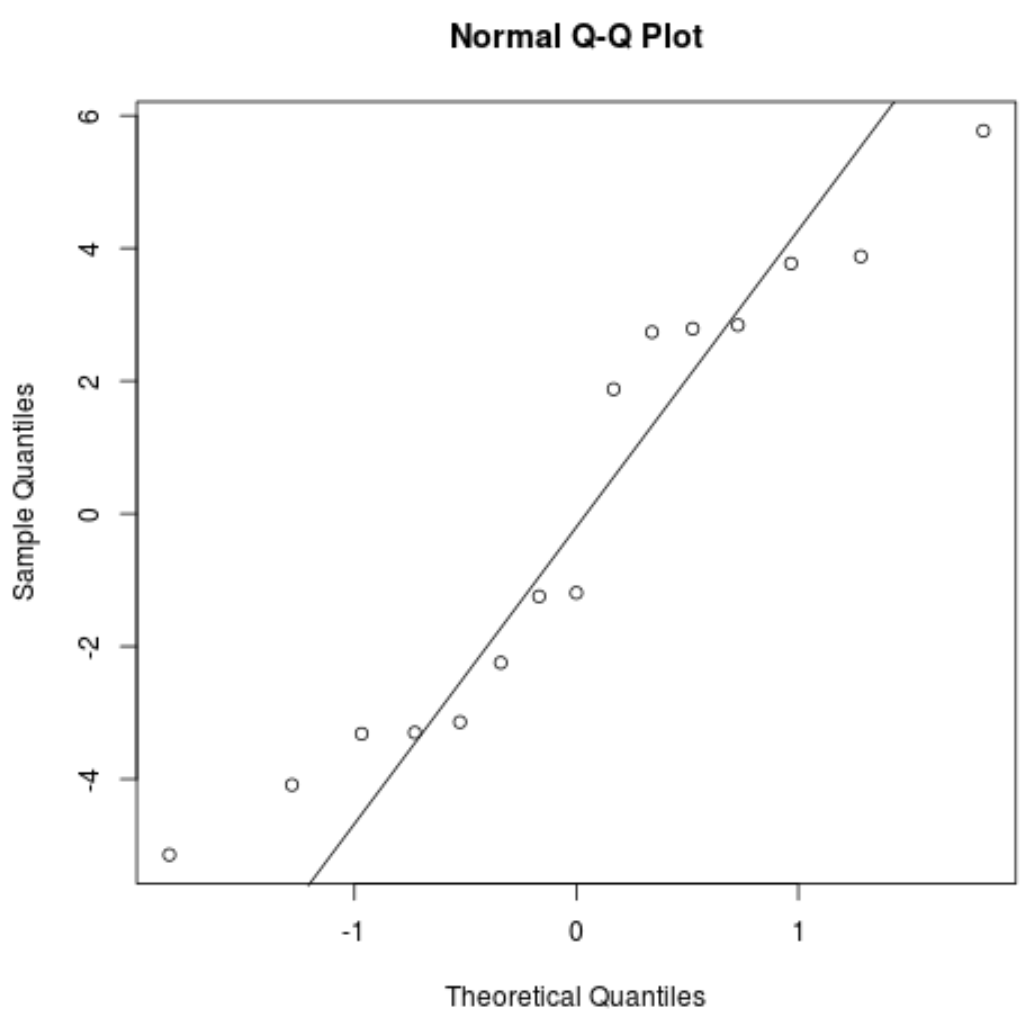
สารตกค้างเบี่ยงเบนไปจากเส้น 45 องศาเล็กน้อย แต่ไม่มากพอที่จะทำให้เกิดความกังวลร้ายแรง เราสามารถสรุปได้ว่าเป็นไปตามสมมติฐานปกติ
เนื่องจากส่วนที่เหลือมีการกระจายตามปกติและเป็นโฮโมสซิดาสติก เราจึงตรวจสอบได้ว่าเป็นไปตามสมมติฐานของแบบจำลองการถดถอยเชิงเส้นอย่างง่าย ดังนั้นผลลัพธ์ของแบบจำลองของเราจึงมีความน่าเชื่อถือ
รหัส R แบบเต็มที่ใช้ในบทช่วยสอนนี้สามารถพบได้ ที่นี่
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม