การวิเคราะห์จำแนกเชิงเส้นใน python (ทีละขั้นตอน)
การวิเคราะห์จำแนกเชิงเส้น เป็นวิธีการที่คุณสามารถใช้เมื่อคุณมีชุดตัวแปรทำนายและต้องการจัด ประเภทตัวแปรตอบสนอง เป็นสองคลาสขึ้นไป
บทช่วยสอนนี้ให้ตัวอย่างทีละขั้นตอนของวิธีการวิเคราะห์จำแนกเชิงเส้นใน Python
ขั้นตอนที่ 1: โหลดไลบรารีที่จำเป็น
ขั้นแรก เราจะโหลดฟังก์ชันและไลบรารีที่จำเป็นสำหรับตัวอย่างนี้:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
ขั้นตอนที่ 2: โหลดข้อมูล
สำหรับตัวอย่างนี้ เราจะใช้ชุดข้อมูล ม่านตา จากไลบรารี sklearn รหัสต่อไปนี้แสดงวิธีการโหลดชุดข้อมูลนี้และแปลงเป็น DataFrame ของแพนด้าเพื่อความสะดวกในการใช้งาน:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
เราจะเห็นว่าชุดข้อมูลนี้มีข้อสังเกตทั้งหมด 150 รายการ
สำหรับตัวอย่างนี้ เราจะสร้างแบบจำลองการวิเคราะห์จำแนกเชิงเส้นเพื่อจำแนกดอกไม้ที่เป็นของดอกไม้ชนิดใด
เราจะใช้ตัวแปรทำนายต่อไปนี้ในแบบจำลอง:
- ความยาวกลีบเลี้ยง
- ความกว้างของกลีบเลี้ยง
- ความยาวกลีบดอก
- ความกว้างของกลีบดอก
และเราจะใช้พวกมันเพื่อทำนายตัวแปรการตอบสนอง ของสปีชีส์ ซึ่งรองรับคลาสที่เป็นไปได้สามคลาสต่อไปนี้:
- เซโตซ่า
- เวอร์ซิคัลเลอร์
- เวอร์จิเนีย
ขั้นตอนที่ 3: ปรับโมเดล LDA
ต่อไป เราจะปรับโมเดล LDA ให้พอดีกับข้อมูลของเราโดยใช้ฟังก์ชัน LinearDiscriminantAnalsys ของ sklearn:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
ขั้นตอนที่ 4: ใช้แบบจำลองเพื่อคาดการณ์
เมื่อเราติดตั้งโมเดลโดยใช้ข้อมูลของเราแล้ว เราก็สามารถประเมินประสิทธิภาพของโมเดลได้โดยใช้การตรวจสอบความถูกต้องข้ามแบบแบ่งชั้น k-fold ซ้ำ
สำหรับตัวอย่างนี้ เราจะใช้การพับ 10 ครั้งและการทำซ้ำ 3 ครั้ง:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
เราจะเห็นได้ว่าโมเดลนี้มีความแม่นยำโดยเฉลี่ย 97.78% .
นอกจากนี้เรายังสามารถใช้แบบจำลองเพื่อทำนายว่าดอกไม้ใหม่อยู่ในคลาสใด โดยพิจารณาจากค่าอินพุต:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
เราเห็นว่าแบบจำลองทำนายว่าการสังเกตใหม่นี้เป็นของสปีชีส์ที่เรียกว่า เซโตซา
ขั้นตอนที่ 5: เห็นภาพผลลัพธ์
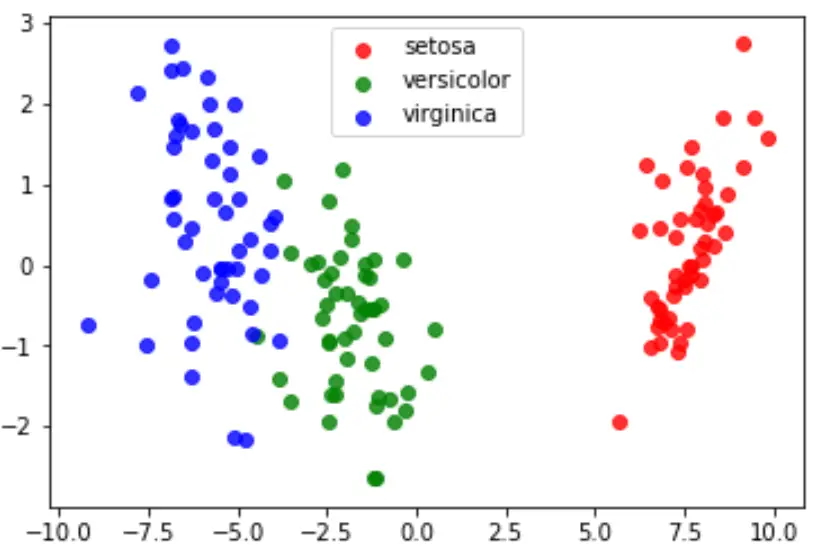
สุดท้ายนี้ เราสามารถสร้างพล็อต LDA เพื่อแสดงภาพการแบ่งแยกเชิงเส้นของแบบจำลอง และเห็นภาพว่ามันแยกสามสายพันธุ์ที่แตกต่างกันในชุดข้อมูลของเราได้ดีเพียงใด:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
คุณสามารถค้นหาโค้ด Python แบบเต็มที่ใช้ในบทช่วยสอนนี้ ได้ที่นี่
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม