การสุ่มตัวอย่าง hypercube แบบละตินคืออะไร
การสุ่มตัวอย่างไฮเปอร์คิวบ์แบบลาติน เป็นวิธีการที่สามารถใช้ในการสุ่มตัวอย่างตัวเลขสุ่ม โดยที่ตัวอย่างมีการกระจายอย่างสม่ำเสมอในพื้นที่ตัวอย่าง
มีการใช้กันอย่างแพร่หลายในการสร้างตัวอย่างที่เรียกว่า ตัวอย่างแบบสุ่มควบคุม และมักใช้ในการวิเคราะห์แบบมอนติคาร์โล เนื่องจากสามารถลดจำนวนการจำลองที่จำเป็นเพื่อให้ได้ผลลัพธ์ที่แม่นยำได้อย่างมาก
การแนะนำตัวอย่าง
เพื่อให้เข้าใจถึงแนวคิดของการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละติน ให้พิจารณาตัวอย่างง่ายๆ ต่อไปนี้:
สมมติว่าเราต้องการได้ตัวอย่าง 2 ค่าจากชุดข้อมูลที่แจกแจงแบบปกติโดยมีค่าเฉลี่ย 0 และค่าเบี่ยงเบนมาตรฐาน 1
หากเราใช้เครื่องกำเนิดตัวเลขสุ่มจริงเพื่อให้ได้ตัวอย่างนี้ อาจเป็นไปได้ว่าทั้งสองค่ามากกว่า 0 หรือทั้งสองค่าน้อยกว่า 0
อย่างไรก็ตาม หากเราใช้การสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินเพื่อให้ได้ตัวอย่างนี้ ก็รับประกันได้ว่าค่าหนึ่งจะมากกว่า 0 และอีกค่าน้อยกว่า 0 เนื่องจากเราสามารถแบ่งพาร์ติชัน พื้นที่ตัวอย่าง โดยเฉพาะในภูมิภาคที่มีค่ามากกว่า 0 ได้ และภูมิภาคที่มีค่าน้อยกว่า 0 จากนั้นเลือกสุ่มตัวอย่างจากแต่ละภูมิภาค
การสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินมิติเดียว
แนวคิดเบื้องหลังการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินมิติเดียวนั้นง่ายมาก: แบ่ง CDF ที่กำหนดออกเป็น n ขอบเขตที่แตกต่างกัน และสุ่มเลือกค่าในแต่ละภูมิภาคเพื่อให้ได้ตัวอย่างขนาด n
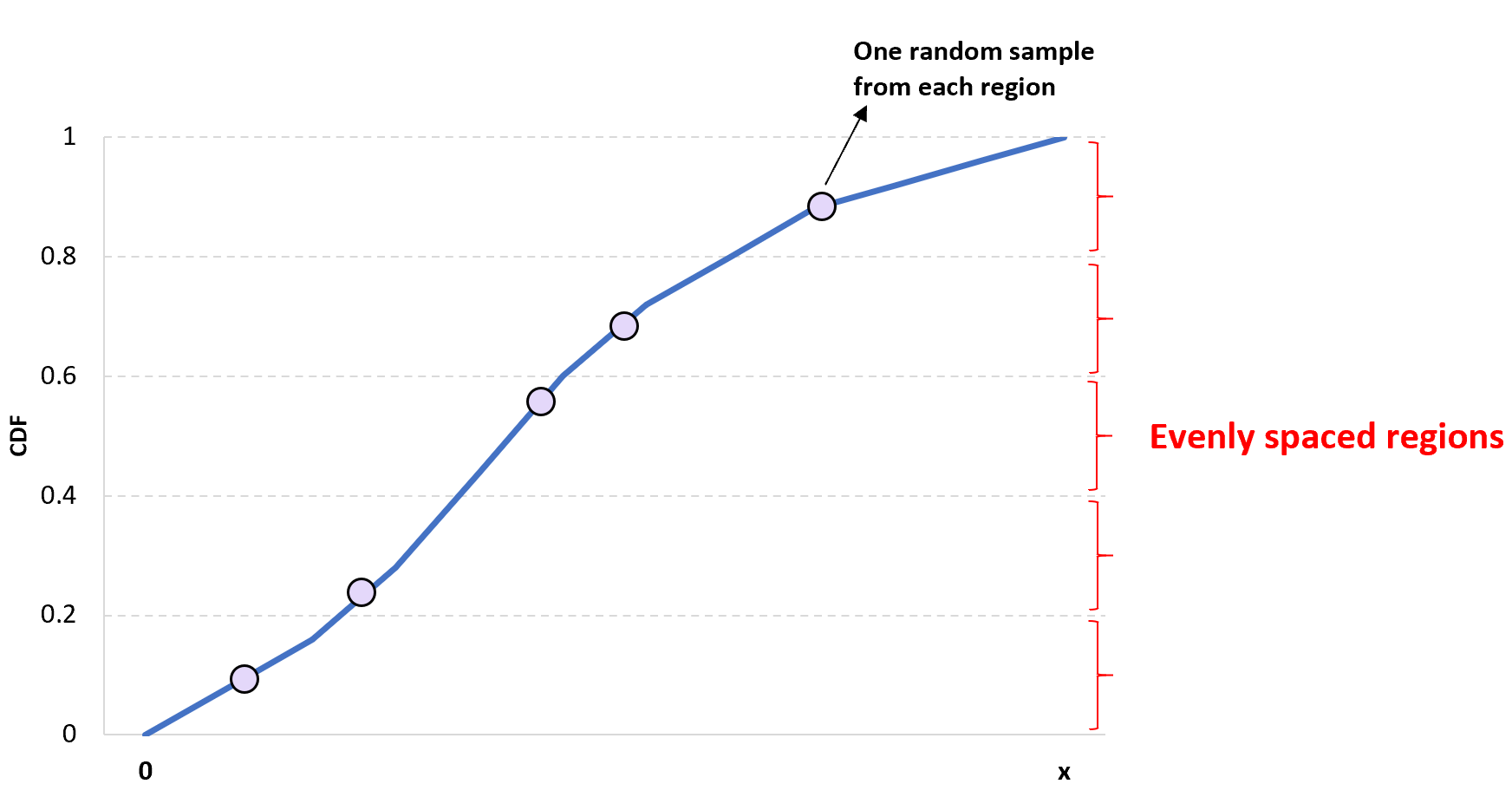
ข้อดีของแนวทางนี้คือช่วยให้แน่ใจได้ว่าจะมีค่าอย่างน้อยหนึ่งค่าจากแต่ละภูมิภาครวมอยู่ในตัวอย่าง
การสุ่มตัวอย่างไฮเปอร์คิวบ์ละตินสองมิติ
เราสามารถขยายแนวคิดของการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินหนึ่งมิติเป็นสองมิติได้อย่างง่ายดายเช่นกัน
สำหรับตัวแปรสองตัวคือ x และ y เราสามารถแบ่งพื้นที่ตัวอย่างของแต่ละตัวแปรออกเป็นส่วนที่มีระยะห่างเท่ากัน n ส่วน และเลือกตัวอย่างแบบสุ่มจากแต่ละพื้นที่ตัวอย่างเพื่อให้ได้ค่าสุ่มในสองมิติ
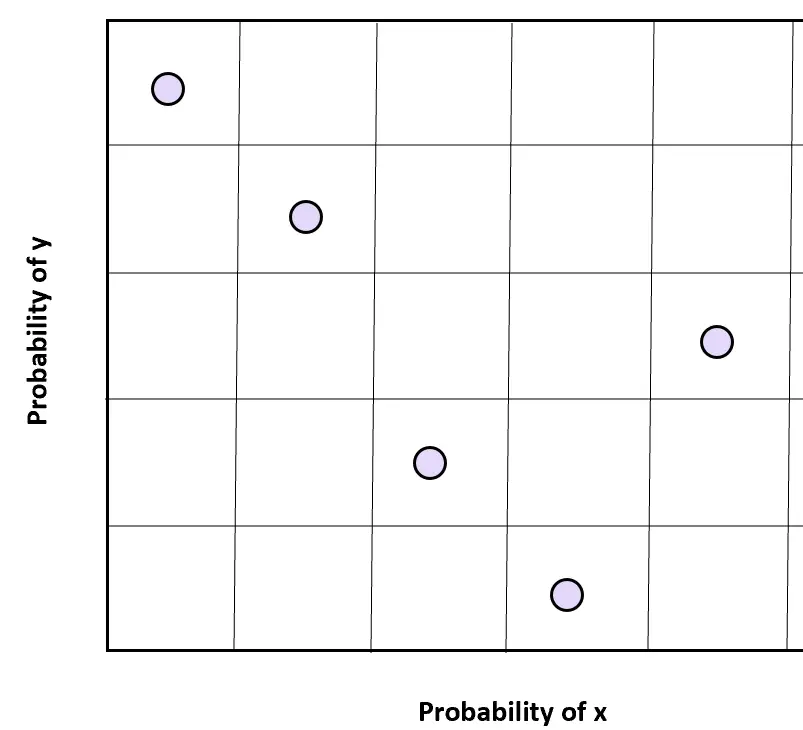
สิ่งสำคัญคือต้องทราบว่าตัวแปรทั้งสองต้องเป็นอิสระต่อกันสำหรับเทคนิคการสุ่มตัวอย่างนี้เพื่อให้ได้ผลลัพธ์ตามที่ต้องการ
การสุ่มตัวอย่างไฮเปอร์คิวบ์ละตินมิติ N
หากต้องการทำการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินในมิติที่ใหญ่ขึ้น เราสามารถขยายแนวคิดของการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบละตินแบบสองมิติไปสู่มิติที่มากขึ้นได้
ตัวแปรแต่ละตัวจะถูกแบ่งออกเป็นบริเวณที่มีระยะห่างเท่าๆ กัน จากนั้นสุ่มเลือกตัวอย่างจากแต่ละภูมิภาคเพื่อให้ได้ตัวอย่างแบบสุ่มที่มีการควบคุม
ที่เกี่ยวข้อง: ข้อมูลมิติสูงคืออะไร?
เหตุใดจึงใช้การสุ่มตัวอย่าง Latin Hypercube
ข้อได้เปรียบหลักของการสุ่มตัวอย่างไฮเปอร์คิวบ์แบบลาตินก็คือ มันสร้างตัวอย่างที่สะท้อนถึงการกระจายตัวที่แท้จริง และมีแนวโน้มว่าจะต้องใช้ขนาดตัวอย่างที่เล็กกว่า การสุ่มตัวอย่างแบบธรรมดา มาก
วิธีการสุ่มตัวอย่างนี้จะเป็นประโยชน์อย่างยิ่งหากคุณทำงานกับข้อมูลที่มีมิติข้อมูลจำนวนมาก และจำเป็นต้องได้รับตัวอย่างแบบสุ่มที่สะท้อนถึงการกระจายตัวของข้อมูลที่แท้จริงอย่างแท้จริง
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม