การสุ่มตัวอย่างทางสถิติ: คำจำกัดความและตัวอย่าง
ในสาขาสถิติ การสุ่ม หมายถึงการสุ่มมอบหมายอาสาสมัครในการศึกษาให้กับกลุ่มการรักษาต่างๆ
ตัวอย่างเช่น สมมติว่านักวิจัยรับสมัครผู้เข้าร่วม 100 รายเพื่อเข้าร่วมในการศึกษาโดยหวังว่าจะเข้าใจว่ายาสองชนิดที่แตกต่างกันมีผลแตกต่างกันต่อความดันโลหิตหรือไม่
พวกเขาอาจตัดสินใจใช้เครื่องสร้างตัวเลขสุ่มเพื่อสุ่มให้แต่ละวิชาใช้ยาเม็ดที่ 1 หรือเม็ดที่ 2
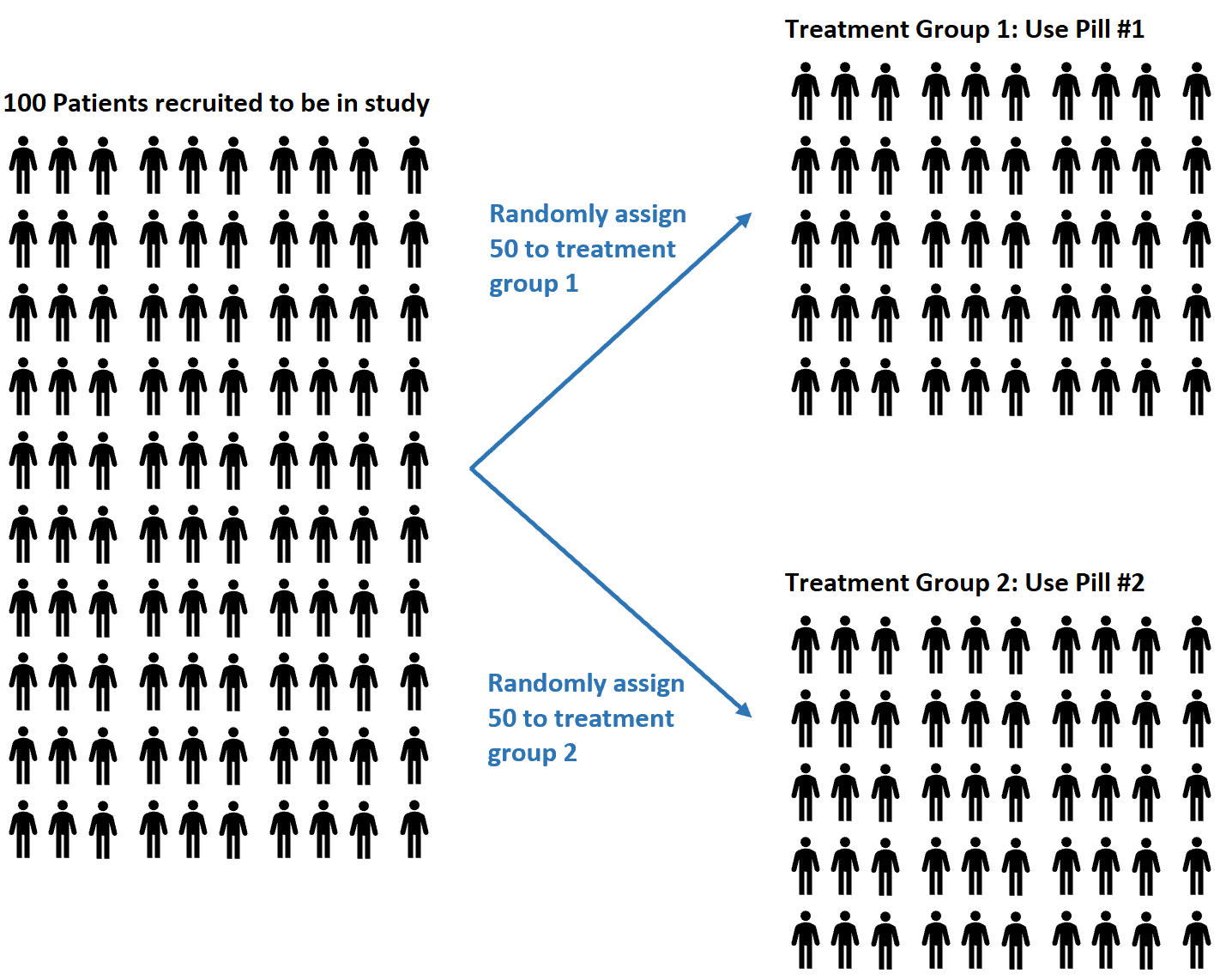
ข้อดีของการสุ่ม
วัตถุประสงค์ของการสุ่มคือเพื่อควบคุม ตัวแปรที่ซ่อนอยู่ ซึ่งเป็นตัวแปรที่ไม่ได้รวมไว้ในการวิเคราะห์โดยตรง แต่ยังส่งผลกระทบต่อการวิเคราะห์ในทางใดทางหนึ่ง
ตัวอย่างเช่น หากนักวิจัยศึกษาผลของยาสองเม็ดที่แตกต่างกันต่อความดันโลหิต ตัวแปรที่ซ่อนอยู่ต่อไปนี้อาจส่งผลต่อการวิเคราะห์:
- เสื้อผ้าทักซิโด้
- อาหาร
- ออกกำลังกาย
ด้วยการสุ่มกำหนดอาสาสมัครให้กับกลุ่มการรักษา เราจะเพิ่มโอกาสสูงสุดที่ตัวแปรที่ซ่อนอยู่จะส่งผลกระทบต่อทั้งสองกลุ่มการรักษาอย่างเท่าเทียมกัน
ซึ่งหมายความว่า ความแตกต่างของความดันโลหิตสามารถนำมาประกอบกับประเภทของยาเม็ดมากกว่าผลของตัวแปรที่ซ่อนอยู่
บล็อกการสุ่ม
ส่วนขยายของการสุ่มเรียกว่า การสุ่มแบบบล็อก นี่เป็นกระบวนการของการแบ่งกลุ่มตัวอย่างออกเป็นบล็อกแรก จากนั้นจึงใช้การสุ่มเพื่อกำหนดกลุ่มตัวอย่างให้ทำการรักษาที่แตกต่างกัน
ตัวอย่างเช่น หากนักวิจัยต้องการทราบว่ายาสองชนิดที่ต่างกันส่งผลต่อความดันโลหิตแตกต่างกันหรือไม่ อันดับแรกสามารถแยกหัวข้อทั้งหมดออกเป็นสองช่วงตึกตามเพศ: ชายหรือหญิง
จากนั้นในแต่ละบล็อก พวกเขาสามารถใช้การสุ่มเพื่อสุ่มมอบหมายให้ผู้เข้าร่วมใช้ยาเม็ด #1 หรือเม็ด #2
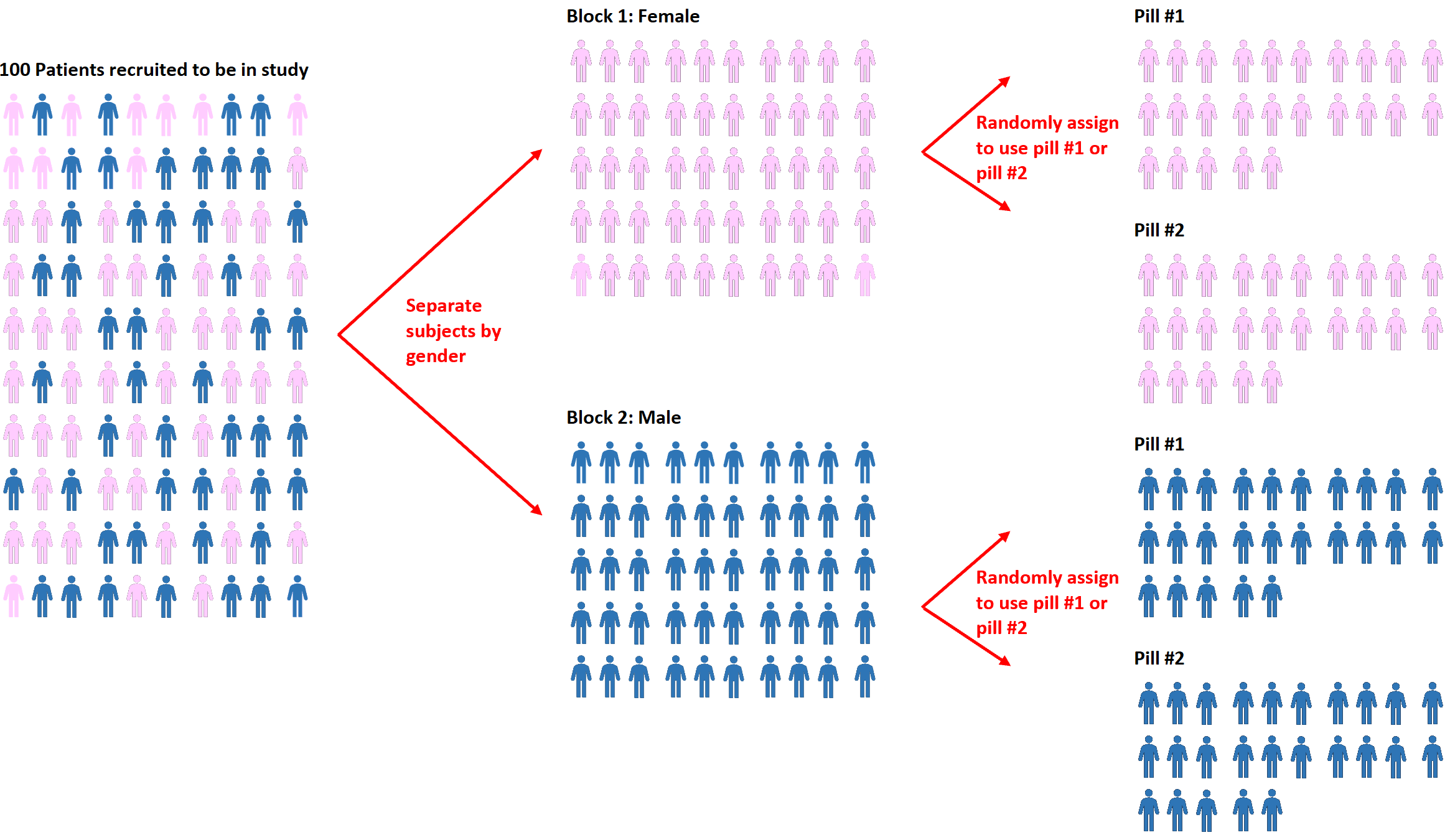
ข้อดีของแนวทางนี้คือนักวิจัยสามารถควบคุมผลกระทบที่เพศอาจมีต่อความดันโลหิตได้โดยตรง เนื่องจากเรารู้ว่าชายและหญิงมีแนวโน้มที่จะตอบสนองต่อยาแต่ละเม็ดแตกต่างกัน
ด้วยการใช้เพศเป็นตัวกั้น เราสามารถกำจัดตัวแปรนี้ซึ่งเป็นแหล่งที่มาของความแปรปรวนได้ หากความดันโลหิตระหว่างยาทั้งสองชนิดแตกต่างกัน เราก็จะทราบได้ว่าเพศไม่ใช่สาเหตุของความแตกต่างเหล่านี้
แหล่งข้อมูลเพิ่มเติม
การบล็อกทางสถิติ: คำจำกัดความและตัวอย่าง
การสุ่มบล็อกที่เรียงสับเปลี่ยน: คำจำกัดความและตัวอย่าง
ตัวแปรที่ซ่อนอยู่: คำจำกัดความและตัวอย่าง
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม