วิธีสร้างป่าสุ่มใน r (ทีละขั้นตอน)
เมื่อความสัมพันธ์ระหว่างชุดของตัวแปรทำนายและ ตัวแปรตอบสนอง มีความซับซ้อนมาก เรามักจะใช้วิธีการแบบไม่เชิงเส้นเพื่อสร้างแบบจำลองความสัมพันธ์ระหว่างตัวแปรเหล่านั้น
วิธีหนึ่งคือการสร้าง แผนผังการตัดสินใจ อย่างไรก็ตาม ข้อเสียของการใช้แผนผังการตัดสินใจเดี่ยวคือมีแนวโน้มที่จะได้รับผลกระทบจาก ความแปรปรวนสูง
นั่นคือ ถ้าเราแบ่งชุดข้อมูลออกเป็นสองซีกและใช้แผนผังการตัดสินใจกับทั้งสองซีก ผลลัพธ์ที่ได้อาจแตกต่างกันมาก
วิธีหนึ่งที่เราสามารถใช้เพื่อลดความแปรปรวนของแผนผังการตัดสินใจเดี่ยวคือการสร้าง แบบจำลองฟอเรสต์แบบสุ่ม ซึ่งทำงานดังนี้:
1. นำตัวอย่างที่บูตสแตรป b จากชุดข้อมูลต้นฉบับ
2. สร้างแผนผังการตัดสินใจสำหรับตัวอย่างบูตสแตรปแต่ละรายการ
- เมื่อสร้างแผนภูมิต้นไม้ แต่ละครั้งที่มีการพิจารณาการแยก จะมีเพียงตัวอย่างสุ่มของตัวทำนาย m เท่านั้นที่จะได้รับการพิจารณาว่าเป็นตัวเลือกสำหรับการแยกจากชุดตัวทำนาย p ครบชุด โดยทั่วไปเราเลือก m เท่ากับ √p .
3. เฉลี่ยการคาดการณ์จากต้นไม้แต่ละต้นเพื่อให้ได้แบบจำลองขั้นสุดท้าย
ปรากฎว่าป่าสุ่มมีแนวโน้มที่จะสร้างแบบจำลองที่แม่นยำมากกว่าแผนผังการตัดสินใจเดี่ยวและแม้แต่ แบบจำลองแบบถุง
บทช่วยสอนนี้ให้ตัวอย่างทีละขั้นตอนของวิธีสร้างแบบจำลองฟอเรสต์แบบสุ่มสำหรับชุดข้อมูลใน R
ขั้นตอนที่ 1: โหลดแพ็คเกจที่จำเป็น
ขั้นแรก เราจะโหลดแพ็คเกจที่จำเป็นสำหรับตัวอย่างนี้ สำหรับตัวอย่างง่ายๆ นี้ เราต้องการเพียงแพ็คเกจเดียวเท่านั้น:
library (randomForest)
ขั้นตอนที่ 2: ปรับโมเดลฟอเรสต์แบบสุ่ม
สำหรับตัวอย่างนี้ เราจะใช้ชุดข้อมูล R ในตัวที่เรียกว่า คุณภาพอากาศ ซึ่งมีการตรวจวัดคุณภาพอากาศในนิวยอร์กซิตี้มากกว่า 153 วันในแต่ละวัน
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
ชุดข้อมูลนี้มี 42 แถวที่มีค่าหายไป ดังนั้น ก่อนที่จะปรับแบบจำลองฟอเรสต์แบบสุ่ม เราจะกรอกค่าที่หายไปในแต่ละคอลัมน์ด้วยค่ามัธยฐานของคอลัมน์:
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
ที่เกี่ยวข้อง: วิธีกำหนดค่าที่หายไปใน R
รหัสต่อไปนี้แสดงวิธีการใส่โมเดลฟอเรสต์แบบสุ่มใน R โดยใช้ฟังก์ชัน RandomForest() จากแพ็คเกจ RandomForest
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
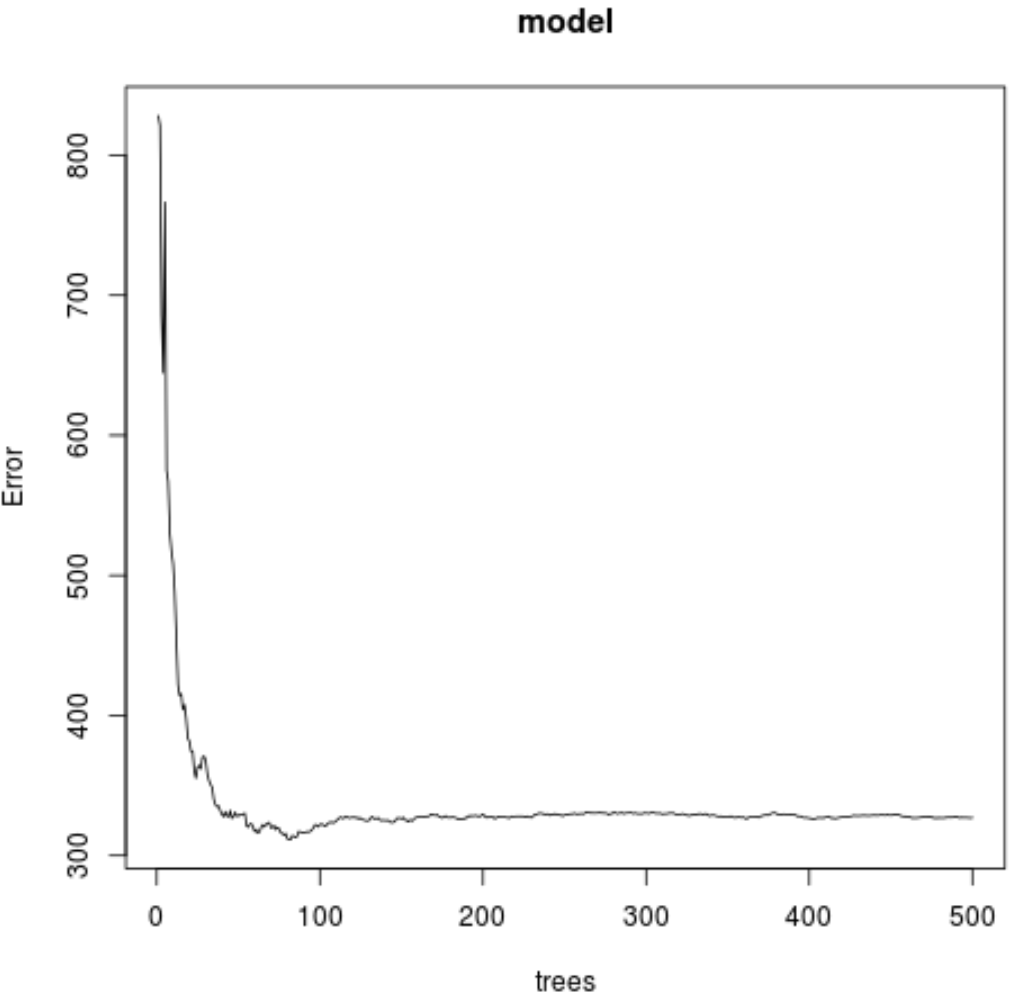
จากผลลัพธ์ เราจะเห็นว่าแบบจำลองที่สร้างค่าความคลาดเคลื่อนกำลังสองเฉลี่ยการทดสอบต่ำสุด (MSE) ใช้ต้นไม้ 82 ต้น
เรายังเห็นได้ว่าค่าคลาดเคลื่อนกำลังสองเฉลี่ยรูตของโมเดลนี้คือ 17.64392 เราสามารถมองได้ว่านี่เป็นความแตกต่างโดยเฉลี่ยระหว่างค่าที่คาดการณ์ไว้สำหรับโอโซนกับค่าที่สังเกตได้จริง
นอกจากนี้เรายังสามารถใช้โค้ดต่อไปนี้เพื่อสร้างพล็อตของการทดสอบ MSE ตามจำนวนต้นไม้ที่ใช้:
#plot the MSE test by number of trees
plot(model)
และเราสามารถใช้ฟังก์ชัน varImpPlot() เพื่อสร้างพล็อตที่แสดงความสำคัญของตัวแปรตัวทำนายแต่ละตัวในโมเดลสุดท้าย:
#produce variable importance plot
varImpPlot(model)
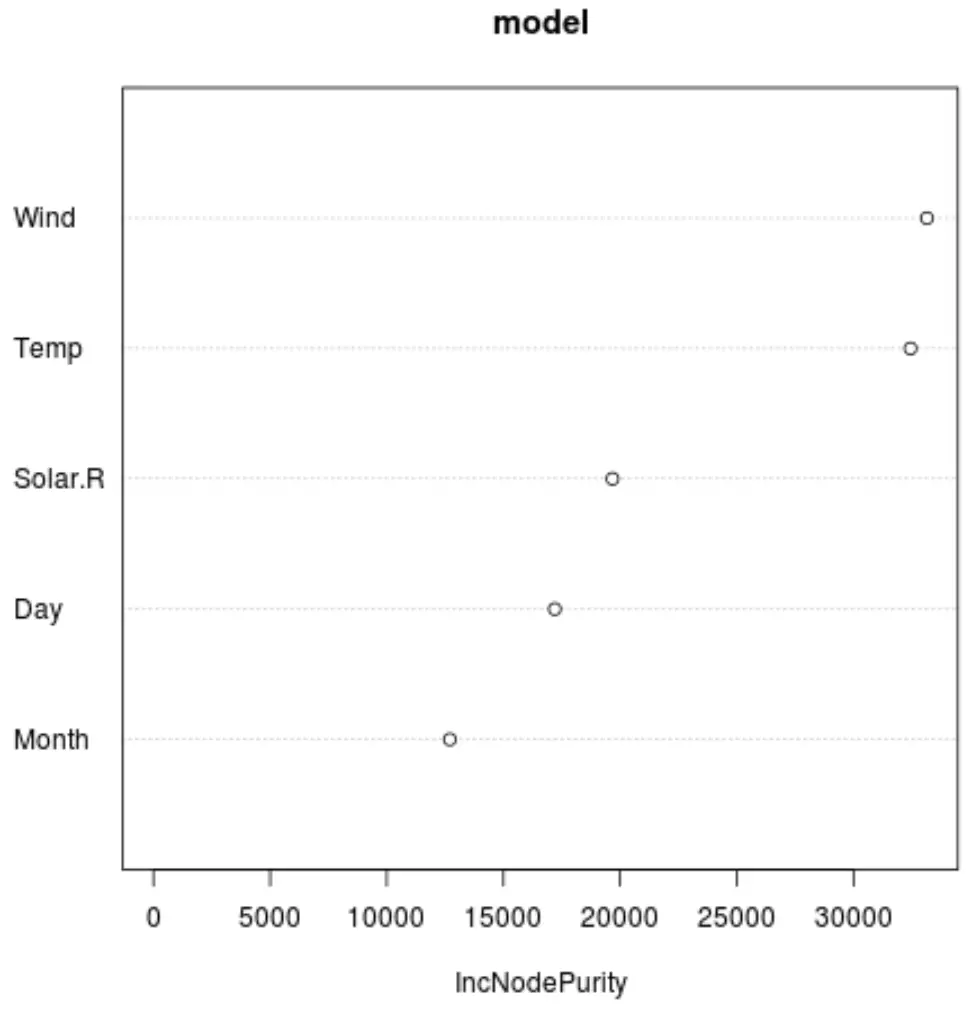
แกน x แสดงการเพิ่มขึ้นโดยเฉลี่ยในความบริสุทธิ์ของโหนดของแผนภูมิการถดถอย โดยเป็นฟังก์ชันของการแยกตัวทำนายต่างๆ ที่แสดงบนแกน y
จากกราฟเราจะเห็นว่า ลม เป็นตัวแปรทำนายที่สำคัญที่สุด รองลงมาคือ Temp
ขั้นตอนที่ 3: ปรับโมเดล
ตามค่าเริ่มต้น ฟังก์ชัน RandomForest() จะใช้ต้นไม้ 500 ต้นและ (ตัวทำนายทั้งหมด/3) ตัวทำนายที่เลือกแบบสุ่มเป็นตัวเลือกที่เป็นไปได้สำหรับการแยกแต่ละครั้ง เราสามารถปรับพารามิเตอร์เหล่านี้ได้โดยใช้ฟังก์ชัน tuneRF()
รหัสต่อไปนี้แสดงวิธีการค้นหาโมเดลที่เหมาะสมที่สุดโดยใช้ข้อกำหนดต่อไปนี้:
- ntreeTry: จำนวนต้นไม้ที่จะสร้าง
- mtryStart: จำนวนตัวแปรทำนายเริ่มต้นที่ต้องพิจารณาในแต่ละดิวิชั่น
- ปัจจัยขั้นตอน: ปัจจัยที่จะเพิ่มขึ้นจนกว่าข้อผิดพลาดเมื่อสินค้าหมดถุงโดยประมาณจะหยุดดีขึ้นตามจำนวนที่กำหนด
- ปรับปรุง: จำนวนที่ต้องปรับปรุงข้อผิดพลาดในการออกจากถุงเพื่อเพิ่มปัจจัยขั้นตอนต่อไป
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
ฟังก์ชันนี้สร้างพล็อตต่อไปนี้ ซึ่งแสดงจำนวนตัวทำนายที่ใช้ในแต่ละการแยกเมื่อสร้างต้นไม้บนแกน x และข้อผิดพลาดเมื่อหมดถุงโดยประมาณบนแกน y:
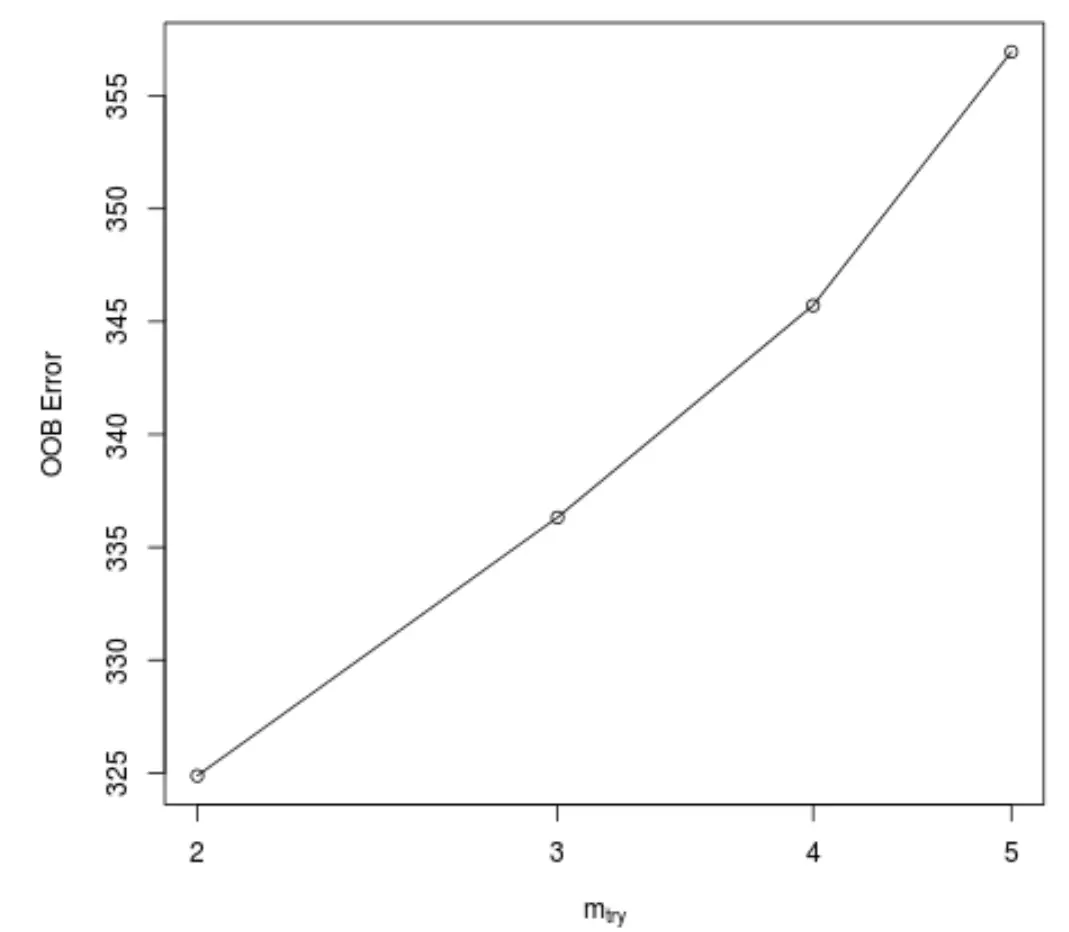
เราจะเห็นว่าได้รับข้อผิดพลาด OOB ต่ำสุดโดยใช้ตัวทำนายที่เลือกแบบสุ่ม 2 ตัว ในแต่ละการแยกเมื่อสร้างต้นไม้
ซึ่งจริงๆ แล้วสอดคล้องกับการตั้งค่าเริ่มต้น (ตัวทำนายทั้งหมด/3 = 6/3 = 2) ที่ใช้โดยฟังก์ชัน RandomForest() เริ่มต้น
ขั้นตอนที่ 4: ใช้แบบจำลองสุดท้ายเพื่อคาดการณ์
สุดท้ายนี้ เราสามารถใช้แบบจำลองฟอเรสต์แบบสุ่มที่ปรับปรุงแล้วเพื่อคาดการณ์เกี่ยวกับการสังเกตการณ์ใหม่ๆ
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
จากค่าของตัวแปรทำนาย โมเดลฟอเรสต์สุ่มที่ติดตั้งคาดการณ์ว่าค่าโอโซนจะเป็น 27.19442 ในวันนี้
สามารถดูโค้ด R แบบเต็มที่ใช้ในตัวอย่างนี้ ได้ ที่นี่
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม