วิธีการทดสอบการขาดความพอดีใน r (ทีละขั้นตอน)
การทดสอบการขาดความพอดี ใช้เพื่อพิจารณาว่า แบบจำลองการถดถอย แบบเต็มมีความเหมาะสมกับชุดข้อมูลมากกว่าแบบจำลองเวอร์ชันย่อหรือไม่
ตัวอย่างเช่น สมมติว่าเราต้องการใช้ จำนวนชั่วโมงเรียน เพื่อทำนาย คะแนนสอบ ของนักเรียนในวิทยาลัยแห่งใดแห่งหนึ่ง เราสามารถตัดสินใจปรับใช้แบบจำลองการถดถอยสองแบบต่อไปนี้:
แบบจำลองเต็ม: คะแนน = β 0 + B 1 (ชั่วโมง) + B 2 (ชั่วโมง) 2
แบบจำลองที่ลดลง: คะแนน = β 0 + B 1 (ชั่วโมง)
ตัวอย่างทีละขั้นตอนต่อไปนี้แสดงวิธีการทดสอบการขาดความพอดีใน R เพื่อตรวจสอบว่าแบบจำลองแบบเต็มมีความพอดีที่ดีกว่าแบบจำลองแบบลดขนาดอย่างมากหรือไม่
ขั้นตอนที่ 1: สร้างและแสดงภาพชุดข้อมูล
ขั้นแรก เราจะใช้โค้ดต่อไปนี้เพื่อสร้างชุดข้อมูลที่ประกอบด้วยจำนวนชั่วโมงที่เรียนและคะแนนสอบที่ได้รับสำหรับนักเรียน 50 คน:
#make this example reproducible set. seeds (1) #create dataset df <- data. frame (hours = runif (50, 5, 15), score=50) df$score = df$score + df$hours^3/150 + df$hours* runif (50, 1, 2) #view first six rows of data head(df) hours score 1 7.655087 64.30191 2 8.721239 70.65430 3 10.728534 73.66114 4 14.082078 86.14630 5 7.016819 59.81595 6 13.983897 83.60510
ต่อไป เราจะสร้างแผนภาพกระจายเพื่อแสดงความสัมพันธ์ระหว่างชั่วโมงและคะแนนเป็นภาพ:
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(df, aes (x=hours, y=score)) + geom_point()
ขั้นตอนที่ 2: ใส่โมเดลสองแบบที่แตกต่างกันเข้ากับชุดข้อมูล
ต่อไป เราจะใส่โมเดลการถดถอยที่แตกต่างกันสองแบบเข้ากับชุดข้อมูล:
#fit full model full <- lm(score ~ poly (hours,2), data=df) #fit reduced model reduced <- lm(score ~ hours, data=df)
ขั้นตอนที่ 3: ทำการทดสอบการขาดความพอดี
ต่อไป เราจะใช้คำสั่ง anova() เพื่อทำการทดสอบการขาดความพอดีระหว่างทั้งสองรุ่น:
#lack of fit test
anova(full, reduced)
Analysis of Variance Table
Model 1: score ~ poly(hours, 2)
Model 2: score ~ hours
Res.Df RSS Df Sum of Sq F Pr(>F)
1 47 368.48
2 48 451.22 -1 -82.744 10.554 0.002144 **
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
สถิติการทดสอบ F กลายเป็น 10.554 และค่า p ที่สอดคล้องกันคือ 0.002144 เนื่องจากค่า p นี้น้อยกว่า 0.05 เราจึงสามารถปฏิเสธสมมติฐานว่างของการทดสอบได้ และสรุปได้ว่าแบบจำลองแบบเต็มมีความพอดีที่ดีกว่าแบบจำลองแบบลดขนาดอย่างมีนัยสำคัญทางสถิติ
ขั้นตอนที่ 4: เห็นภาพโมเดลขั้นสุดท้าย
สุดท้ายนี้ เราสามารถเห็นภาพโมเดลขั้นสุดท้าย (โมเดลเต็ม) เทียบกับชุดข้อมูลดั้งเดิม:
ggplot(df, aes (x=hours, y=score)) +
geom_point() +
stat_smooth(method=' lm ', formula = y ~ poly (x,2), size = 1) +
xlab(' Hours Studied ') +
ylab(' Score ')
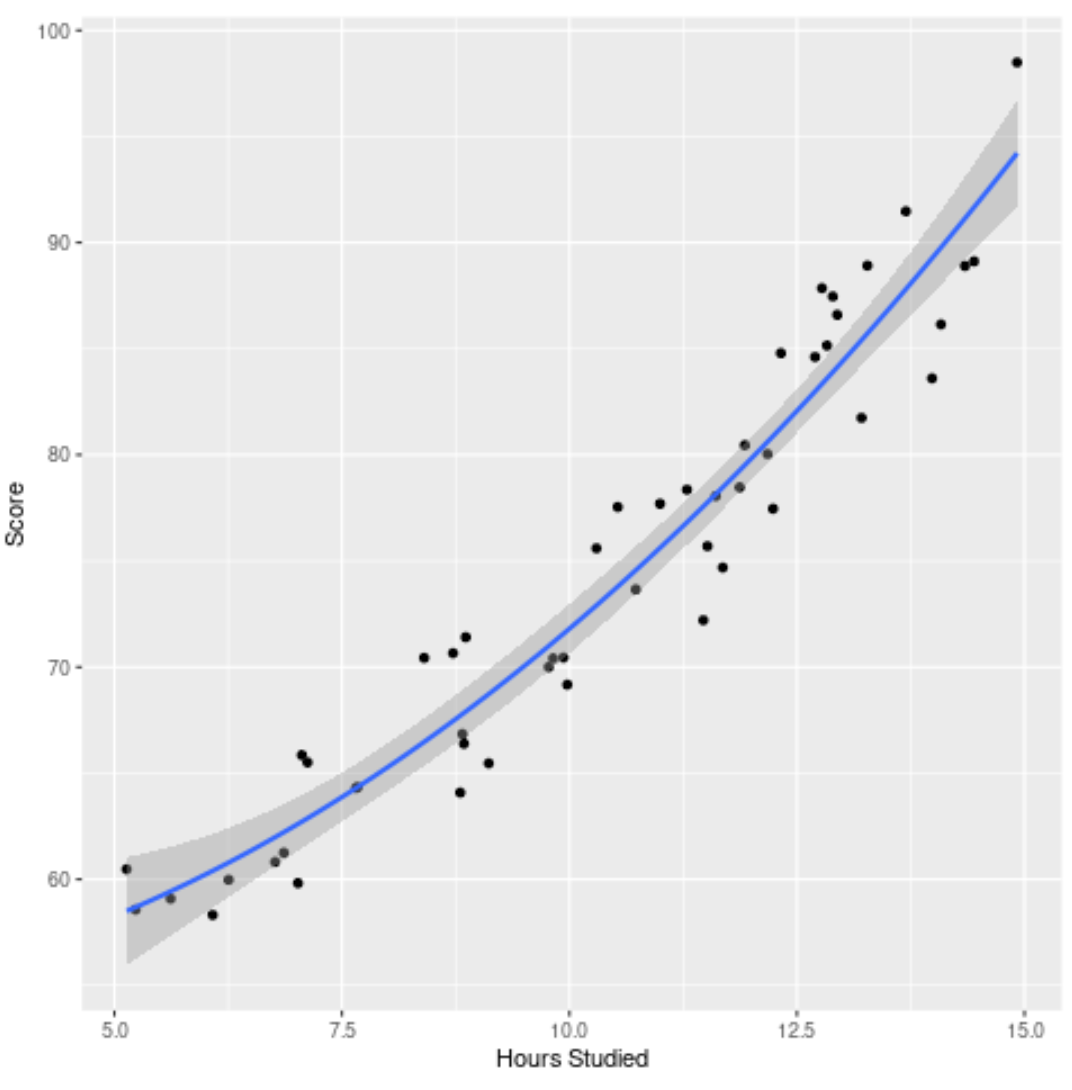
เราจะเห็นได้ว่าเส้นโค้งแบบจำลองเหมาะสมกับข้อมูลค่อนข้างดี
แหล่งข้อมูลเพิ่มเติม
วิธีดำเนินการถดถอยเชิงเส้นอย่างง่ายใน R
วิธีดำเนินการถดถอยเชิงเส้นพหุคูณใน R
วิธีดำเนินการถดถอยพหุนามใน R
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม