ข้อมูลมิติสูงคืออะไร? (คำจำกัดความและตัวอย่าง)
ข้อมูลมิติสูง หมายถึงชุดข้อมูลที่จำนวนคุณลักษณะ p มากกว่าจำนวน การสังเกต N ซึ่งมักเขียนเป็น p >> N
ตัวอย่างเช่น ชุดข้อมูลที่มีคุณลักษณะ p = 6 และการสังเกตเพียง N = 3 เท่านั้นที่จะถือว่าเป็นข้อมูลมิติสูง เนื่องจากจำนวนคุณลักษณะมากกว่าจำนวนการสังเกต
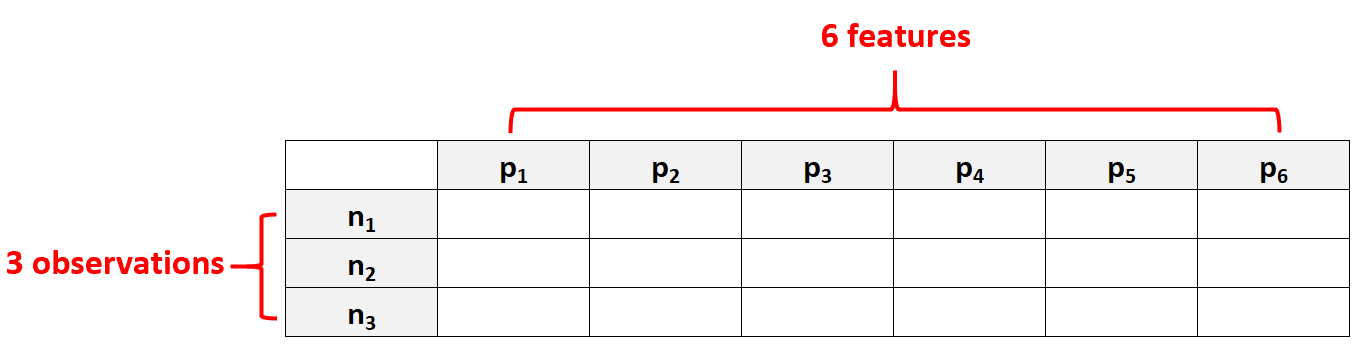
ข้อผิดพลาดทั่วไปที่ผู้คนทำคือการสันนิษฐานว่า “ข้อมูลมิติสูง” นั้นหมายถึงชุดข้อมูลที่มีคุณสมบัติมากมาย อย่างไรก็ตาม สิ่งนี้ไม่ถูกต้อง ชุดข้อมูลอาจมี 10,000 คุณลักษณะ แต่ถ้ามีการสังเกต 100,000 ครั้ง ก็ไม่ใช่มิติสูง
หมายเหตุ: โปรดดูบทที่ 18 ขององค์ประกอบของการเรียนรู้ทางสถิติ สำหรับการอภิปรายเชิงลึกเกี่ยวกับคณิตศาสตร์ที่อยู่เบื้องหลังข้อมูลมิติสูง
เหตุใดข้อมูลมิติสูงจึงเป็นปัญหา
เมื่อจำนวนคุณลักษณะในชุดข้อมูลเกินจำนวนการสังเกต เราจะไม่มีทางได้รับคำตอบที่กำหนดได้
กล่าวอีกนัยหนึ่ง มันเป็นไปไม่ได้ที่จะหาแบบจำลองที่สามารถอธิบายความสัมพันธ์ระหว่างตัวแปรทำนายและ ตัวแปรตอบสนอง เนื่องจากเราไม่มีข้อสังเกตเพียงพอที่จะฝึกแบบจำลอง
ตัวอย่างข้อมูลมิติสูง
ตัวอย่างต่อไปนี้แสดงชุดข้อมูลมิติสูงในโดเมนที่แตกต่างกัน
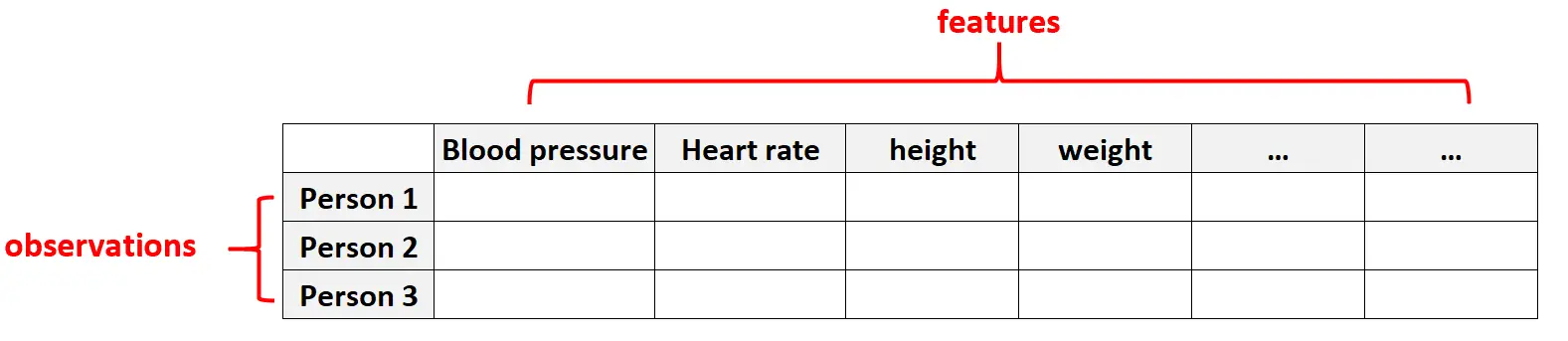
ตัวอย่างที่ 1: ข้อมูลสุขภาพ
ข้อมูลที่มีมิติสูงเป็นเรื่องปกติในชุดข้อมูลด้านการดูแลสุขภาพ ซึ่งคุณลักษณะต่างๆ มากมายสำหรับแต่ละบุคคลอาจมีปริมาณมหาศาล (เช่น ความดันโลหิต อัตราการเต้นของหัวใจขณะพัก สถานะของระบบภูมิคุ้มกัน ประวัติการผ่าตัด ส่วนสูง น้ำหนัก สภาพที่เป็นอยู่ เป็นต้น)
ในชุดข้อมูลเหล่านี้ เป็นเรื่องปกติที่จำนวนคุณลักษณะจะมากกว่าจำนวนการสังเกต
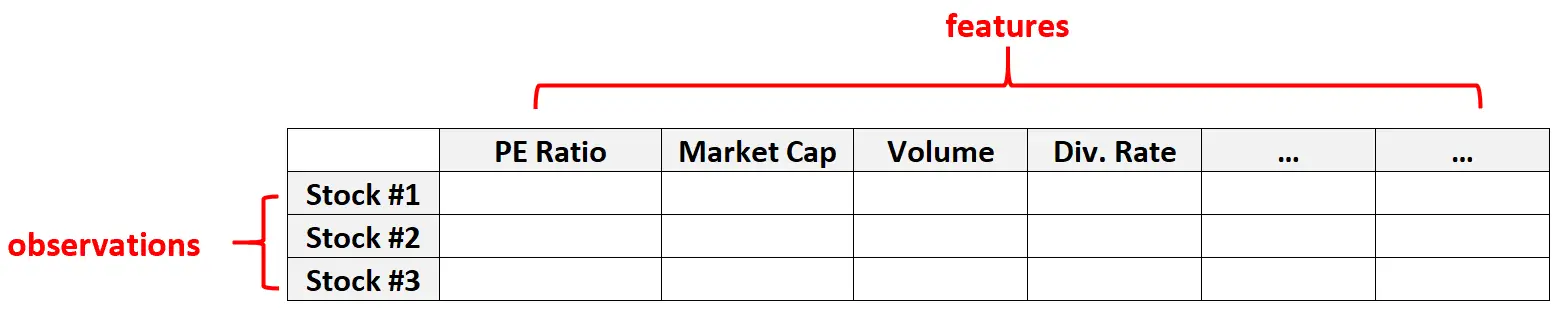
ตัวอย่างที่ 2: ข้อมูลทางการเงิน
ข้อมูลที่มีมิติสูงยังเป็นเรื่องปกติในชุดข้อมูลทางการเงิน ซึ่งจำนวนคุณลักษณะของหุ้นที่ระบุอาจมีค่อนข้างมาก (เช่น อัตราส่วน PE มูลค่าหลักทรัพย์ตามราคาตลาด ปริมาณการซื้อขาย อัตราเงินปันผล ฯลฯ)
ในชุดข้อมูลประเภทนี้ เป็นเรื่องปกติที่จำนวนเอนทิตีจะมากกว่าจำนวนการดำเนินการแต่ละรายการมาก
ตัวอย่างที่ 3: จีโนมิกส์
ข้อมูลมิติสูงยังพบได้ทั่วไปในสาขาจีโนมิกส์ ซึ่งลักษณะทางพันธุกรรมของบุคคลนั้นมีจำนวนมหาศาล

วิธีจัดการกับข้อมูลขนาดใหญ่
มีสองวิธีทั่วไปในการประมวลผลข้อมูลมิติสูง:
1. เลือกที่จะรวมคุณสมบัติให้น้อยลง
วิธีที่ชัดเจนที่สุดในการหลีกเลี่ยงการจัดการกับข้อมูลที่มีมิติสูงคือการใส่คุณลักษณะน้อยลงในชุดข้อมูล
มีหลายวิธีในการตัดสินใจว่าจะลบคุณลักษณะใดออกจากชุดข้อมูล ได้แก่:
- ลบคุณลักษณะที่มีค่าที่ขาดหายไปจำนวนมาก: หากคอลัมน์ที่กำหนดในชุดข้อมูลมีค่าที่ขาดหายไปจำนวนมาก คุณอาจสามารถลบออกได้ทั้งหมดโดยไม่สูญเสียข้อมูลมากนัก
- ลบคุณลักษณะความแปรปรวนต่ำ: หากคอลัมน์ที่กำหนดในชุดข้อมูลมีค่าที่เปลี่ยนแปลงน้อยมาก คุณอาจลบออกได้เนื่องจากไม่น่าจะให้ข้อมูลที่เป็นประโยชน์เกี่ยวกับตัวแปรตอบสนองได้มากเท่ากับคุณลักษณะอื่น ๆ
- ลบคุณลักษณะที่มีความสัมพันธ์ต่ำกับตัวแปรการตอบสนอง: หากคุณลักษณะบางอย่างไม่มีความสัมพันธ์อย่างมากกับตัวแปรการตอบสนองที่คุณสนใจ คุณอาจลบออกจากชุดข้อมูลได้ เนื่องจากไม่น่าจะเป็นไปได้ว่าคุณลักษณะนั้นจะมีประโยชน์ในแบบจำลอง
2. ใช้วิธีการทำให้เป็นมาตรฐาน
อีกวิธีในการจัดการข้อมูลมิติสูงโดยไม่ต้องลบคุณลักษณะออกจากชุดข้อมูลคือการใช้เทคนิคการทำให้เป็นมาตรฐาน เช่น:
แต่ละเทคนิคเหล่านี้สามารถใช้เพื่อประมวลผลข้อมูลมิติสูงได้อย่างมีประสิทธิภาพ
คุณสามารถดูรายการบทช่วยสอนการเรียนรู้ของเครื่องเชิงสถิติทั้งหมดได้ใน หน้านี้
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม