วิธีการคำนวณสถิติเลเวอเรจใน r
ในเชิงสถิติ การสังเกต จะถือเป็นค่า ผิดปกติ หากค่าของตัวแปรการตอบสนองนั้นมากกว่าการสังเกตที่เหลือในชุดข้อมูลมาก
ในทำนองเดียวกัน การสังเกตถือเป็นการ ใช้ประโยชน์ สูงหากมีค่าตั้งแต่หนึ่งค่าขึ้นไปสำหรับตัวแปรทำนายที่มีความสุดขั้วมากกว่ามากเมื่อเทียบกับการสังเกตที่เหลือในชุดข้อมูล
ขั้นตอนแรกประการหนึ่งในการวิเคราะห์ประเภทใดก็ตามคือการพิจารณาข้อสังเกตที่มีการใช้ประโยชน์สูงให้ละเอียดยิ่งขึ้น เนื่องจากอาจมีผลกระทบอย่างมากต่อผลลัพธ์ของแบบจำลองที่กำหนด
บทช่วยสอนนี้แสดงตัวอย่างทีละขั้นตอนของวิธีคำนวณและแสดงภาพเลเวอเรจสำหรับการสังเกตแต่ละครั้งในแบบจำลองใน R
ขั้นตอนที่ 1: สร้างแบบจำลองการถดถอย
ขั้นแรก เราจะสร้าง โมเดลการถดถอยเชิงเส้นหลายตัว โดยใช้ชุดข้อมูล mtcars ที่สร้างไว้ใน R:
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
ขั้นตอนที่ 2: คำนวณเลเวอเรจสำหรับการสังเกตแต่ละครั้ง
ต่อไป เราจะใช้ฟังก์ชัน hatvalues() เพื่อคำนวณเลเวอเรจสำหรับการสังเกตแต่ละครั้งในโมเดล:
#calculate leverage for each observation in the model hats <- as . data . frame (hatvalues(model)) #display leverage stats for each observation hats hatvalues(model) Mazda RX4 0.04235795 Mazda RX4 Wag 0.04235795 Datsun 710 0.06287776 Hornet 4 Drive 0.07614472 Hornet Sportabout 0.08097817 Valiant 0.05945972 Duster 360 0.09828955 Merc 240D 0.08816960 Merc 230 0.05102253 Merc 280 0.03990060 Merc 280C 0.03990060 Merc 450SE 0.03890159 Merc 450SL 0.03890159 Merc 450SLC 0.03890159 Cadillac Fleetwood 0.19443875 Lincoln Continental 0.16042361 Chrysler Imperial 0.12447530 Fiat 128 0.08346304 Honda Civic 0.09493784 Toyota Corolla 0.08732818 Toyota Corona 0.05697867 Dodge Challenger 0.06954069 AMC Javelin 0.05767659 Camaro Z28 0.10011654 Pontiac Firebird 0.12979822 Fiat X1-9 0.08334018 Porsche 914-2 0.05785170 Lotus Europa 0.08193899 Ford Pantera L 0.13831817 Ferrari Dino 0.12608583 Maserati Bora 0.49663919 Volvo 142E 0.05848459
โดยทั่วไป เราจะพิจารณาข้อสังเกตที่มีค่าเลเวอเรจมากกว่า 2 ให้ละเอียดยิ่งขึ้น
วิธีง่ายๆ ในการทำเช่นนี้คือการจัดเรียงการสังเกตตามค่าเลเวอเรจ โดยเรียงลำดับจากมากไปน้อย:
#sort observations by leverage, descending hats[ order (-hats[' hatvalues(model) ']), ] [1] 0.49663919 0.19443875 0.16042361 0.13831817 0.12979822 0.12608583 [7] 0.12447530 0.10011654 0.09828955 0.09493784 0.08816960 0.08732818 [13] 0.08346304 0.08334018 0.08193899 0.08097817 0.07614472 0.06954069 [19] 0.06287776 0.05945972 0.05848459 0.05785170 0.05767659 0.05697867 [25] 0.05102253 0.04235795 0.04235795 0.03990060 0.03990060 0.03890159 [31] 0.03890159 0.03890159
เราจะเห็นว่าค่าเลเวอเรจสูงสุดคือ 0.4966 เนื่องจากจำนวนนี้ไม่เกิน 2 เราจึงทราบว่าไม่มีการสังเกตใดในชุดข้อมูลของเราที่มีการใช้ประโยชน์สูง
ขั้นตอนที่ 3: เห็นภาพการงัดของการสังเกตแต่ละครั้ง
สุดท้ายนี้ เราสามารถสร้างแผนภูมิสั้นๆ เพื่อให้เห็นภาพการงัดของการสังเกตแต่ละครั้ง:
#plot leverage values for each observation plot(hatvalues(model), type = ' h ')
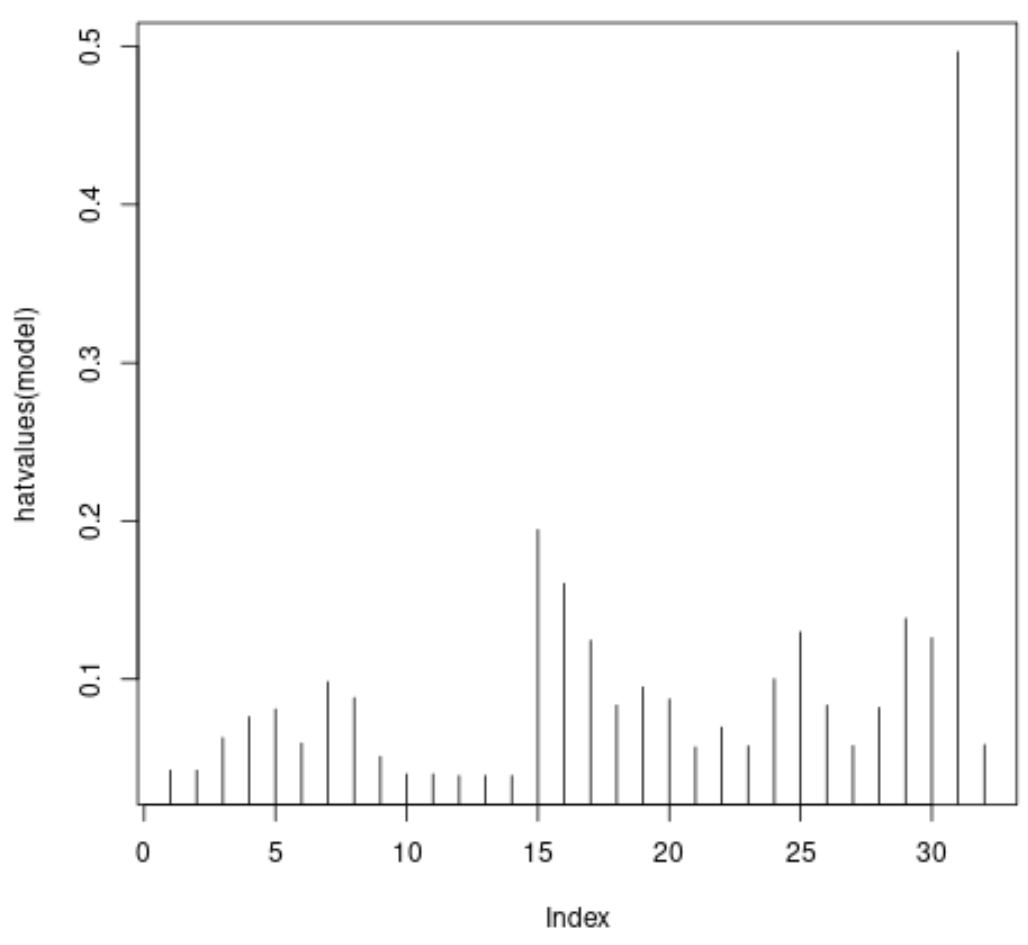
แกน x จะแสดงดัชนีของการสังเกตแต่ละครั้งในชุดข้อมูล และค่า y จะแสดงสถิติเลเวอเรจที่สอดคล้องกันสำหรับการสังเกตแต่ละครั้ง
แหล่งข้อมูลเพิ่มเติม
วิธีดำเนินการถดถอยเชิงเส้นอย่างง่ายใน R
วิธีดำเนินการถดถอยเชิงเส้นพหุคูณใน R
วิธีสร้างพล็อตที่เหลือใน R
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม