วิธีใช้ความแตกต่างที่มีนัยสำคัญน้อยที่สุดของฟิชเชอร์ (lsd) ใน r
การวิเคราะห์ความแปรปรวนแบบทางเดียว ใช้เพื่อพิจารณาว่ามีความแตกต่างที่มีนัยสำคัญทางสถิติระหว่างค่าเฉลี่ยของกลุ่มอิสระสามกลุ่มขึ้นไปหรือไม่
สมมติฐาน ที่ใช้ในการวิเคราะห์ความแปรปรวนแบบทางเดียวคือ:
- H 0 : ค่าเฉลี่ยเท่ากันในแต่ละกลุ่ม
- HA : อย่างน้อยก็มีวิธีหนึ่งที่แตกต่างจากวิธีอื่นๆ
หาก ค่า p ของ ANOVA ต่ำกว่าระดับนัยสำคัญที่กำหนด (เช่น α = 0.05) เราสามารถปฏิเสธสมมติฐานว่างและสรุปได้ว่าค่าเฉลี่ยของกลุ่มอย่างน้อยหนึ่งรายการแตกต่างจากค่าเฉลี่ยอื่นๆ
แต่หากต้องการทราบว่ากลุ่มใดมีความแตกต่างกัน เราต้องทำการทดสอบหลังการทดสอบ
การทดสอบหลังการทดสอบที่ใช้กันทั่วไปคือ การทดสอบความแตกต่างที่มีนัยสำคัญน้อยที่สุดของฟิชเชอร์ (LSD)
คุณสามารถใช้ฟังก์ชัน LSD.test() จากแพ็คเกจ agricolae เพื่อทำการทดสอบนี้ใน R
ตัวอย่างต่อไปนี้แสดงวิธีใช้ฟังก์ชันนี้ในทางปฏิบัติ
ตัวอย่าง: การทดสอบ LSD ของฟิชเชอร์ใน R
สมมติว่าอาจารย์ต้องการทราบว่าเทคนิคการเรียนสามแบบที่แตกต่างกันนำไปสู่คะแนนสอบที่แตกต่างกันของนักเรียนหรือไม่
เพื่อทดสอบสิ่งนี้ เธอสุ่มมอบหมายให้นักเรียน 10 คนใช้เทคนิคการเรียนแต่ละเทคนิคและบันทึกผลการสอบ
ตารางต่อไปนี้แสดง ผลการสอบของนักเรียนแต่ละคนตามเทคนิคการเรียนที่ใช้:
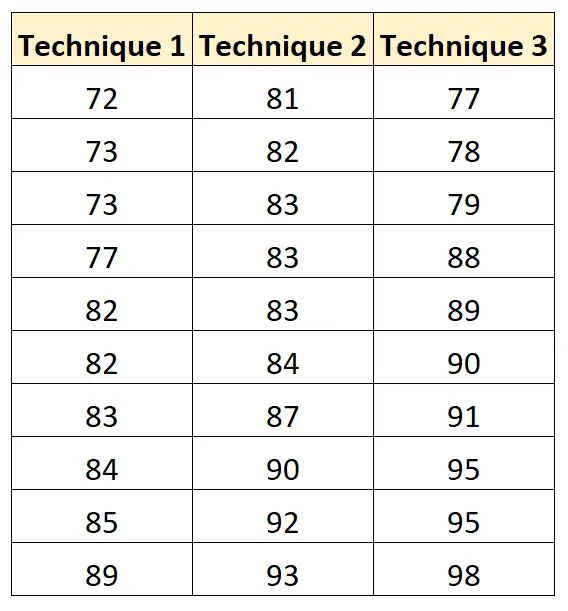
เราสามารถใช้โค้ดต่อไปนี้เพื่อสร้างชุดข้อมูลนี้และดำเนินการวิเคราะห์ความแปรปรวนแบบทางเดียวใน R:
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
เนื่องจากค่า p ในตาราง ANOVA (0.0188) น้อยกว่า 0.05 จึงสรุปได้ว่าคะแนนสอบเฉลี่ยระหว่างทั้งสามกลุ่มไม่เท่ากัน
ดังนั้นเราจึงสามารถทำการทดสอบ LSD ของฟิชเชอร์เพื่อพิจารณาว่าค่าเฉลี่ยของกลุ่มใดแตกต่างกัน
รหัสต่อไปนี้แสดงวิธีการทำเช่นนี้:
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
ส่วนของผลลัพธ์ที่เราสนใจมากที่สุดคือส่วนที่เรียกว่า $groups เทคนิคที่มีตัวละครต่างกันใน กลุ่ม คอลัมน์จะต่างกันมาก
จากผลลัพธ์เราจะเห็นได้ว่า:
- เทคนิคที่ 1 และเทคนิคที่ 3 มีคะแนนสอบเฉลี่ยที่แตกต่างกันอย่างมีนัยสำคัญ (เนื่องจากเทคโนโลยี 1 มีค่าเป็น “b” และเทคนิค 3 มีค่าเป็น “a”)
- เทคนิคที่ 1 และเทคนิคที่ 2 มีคะแนนสอบเฉลี่ยที่แตกต่างกันอย่างมีนัยสำคัญ (เนื่องจากเทคโนโลยี 1 มีค่าเป็น “b” และเทคนิค 2 มีค่าเป็น “a”)
- เทคนิคที่ 2 และเทคนิคที่ 3 ไม่มี คะแนนสอบเฉลี่ยที่แตกต่างกันอย่างมีนัยสำคัญ (เนื่องจากทั้งสองค่ามีค่า “a”)
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีดำเนินการงานทั่วไปอื่นๆ ใน R:
วิธีดำเนินการวิเคราะห์ความแปรปรวนแบบทางเดียวใน R
วิธีทำการทดสอบหลังการทดสอบ Bonferroni ใน R
วิธีทำการทดสอบ Scheffe post-hoc ใน R
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม