วิธีการปรับขนาดหลายมิติใน r (พร้อมตัวอย่าง)
ในสถิติ มาตราส่วนหลายมิติ เป็นวิธีหนึ่งในการแสดงภาพความคล้ายคลึงของการสังเกตในชุดข้อมูลในปริภูมิคาร์ทีเซียนเชิงนามธรรม (โดยปกติจะเป็นปริภูมิ 2 มิติ)
วิธีที่ง่ายที่สุดในการปรับขนาดหลายมิติใน R คือการใช้ฟังก์ชัน cmdscale() ในตัว ซึ่งใช้ไวยากรณ์พื้นฐานต่อไปนี้:
cmdscale(d, eig = FALSE, k = 2, …)
ทอง:
- d : เมทริกซ์ระยะทางโดยทั่วไปคำนวณโดยฟังก์ชัน dist()
- eig : ไม่ว่าจะส่งคืนค่าลักษณะเฉพาะหรือไม่
- k : จำนวนมิติที่จะดูข้อมูล ค่าเริ่มต้นคือ 2
ตัวอย่างต่อไปนี้แสดงวิธีใช้ฟังก์ชันนี้ในทางปฏิบัติ
ตัวอย่าง: มาตราส่วนหลายมิติใน R
สมมติว่าเรามีกรอบข้อมูลต่อไปนี้ใน R ซึ่งมีข้อมูลเกี่ยวกับผู้เล่นบาสเกตบอลต่างๆ:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
เราสามารถใช้โค้ดต่อไปนี้เพื่อทำการปรับขนาดหลายมิติด้วยฟังก์ชัน cmdscale() และแสดงภาพผลลัพธ์ในพื้นที่ 2D:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
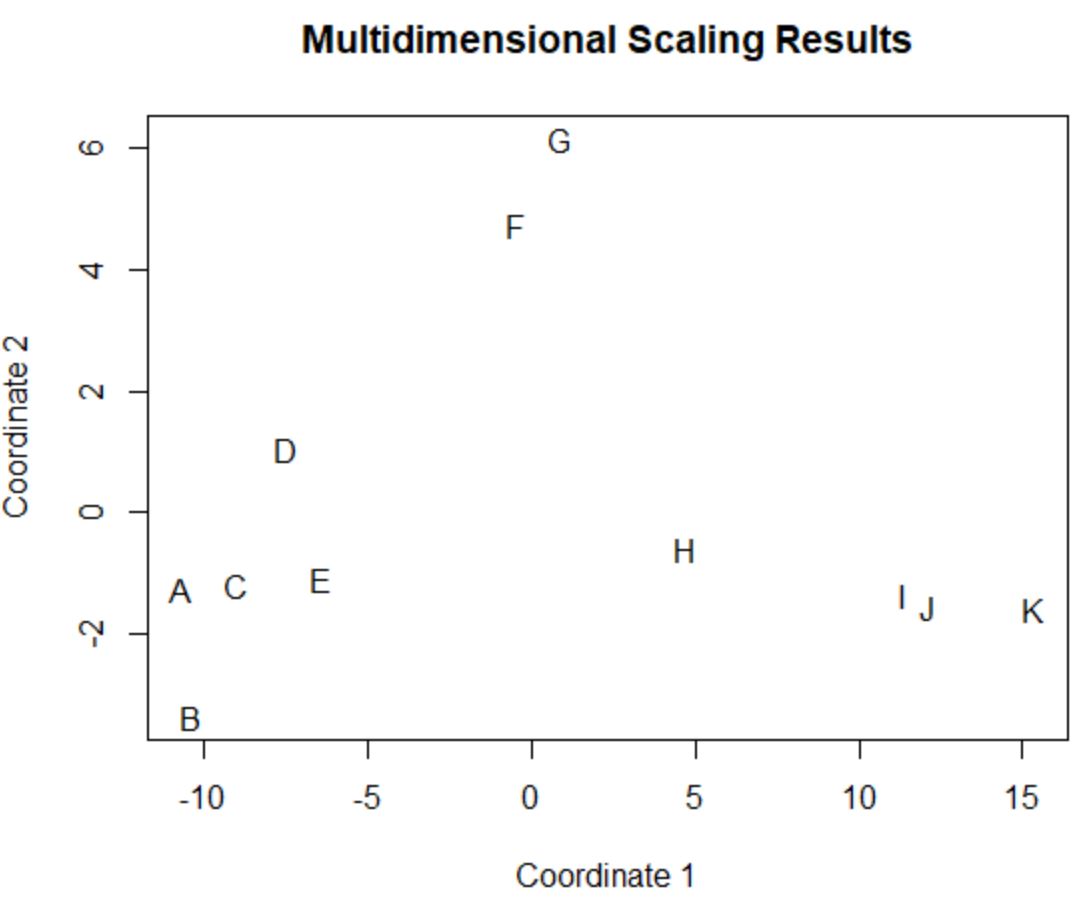
ผู้เล่นในกรอบข้อมูลดั้งเดิมที่มีค่าใกล้เคียงกันในสี่คอลัมน์ดั้งเดิม (แต้ม แอสซิสต์ บล็อก และรีบาวด์) จะอยู่ใกล้กันในโครงเรื่อง
ตัวอย่างเช่น ผู้เล่น A และ C อยู่ใกล้กัน นี่คือค่าจากกรอบข้อมูลดั้งเดิม:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
ค่าแต้ม แอสซิสต์ บล็อก และรีบาวด์ของพวกมันค่อนข้างคล้ายกัน ซึ่งอธิบายได้ว่าทำไมพวกมันถึงอยู่ใกล้กันมากในพล็อต 2 มิติ
ในทางตรงกันข้าม ลองพิจารณาผู้เล่น B และ K ที่อยู่ห่างไกลกันในโครงเรื่อง
หากเราอ้างถึงค่าของมันในข้อมูลดั้งเดิมเราจะเห็นว่ามันแตกต่างกันมาก:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
ดังนั้น พล็อตแบบ 2 มิติจึงเป็นวิธีที่ดีในการแสดงให้เห็นว่าผู้เล่นแต่ละคนมีความคล้ายคลึงกันอย่างไรในตัวแปรทั้งหมดในกรอบข้อมูล
ผู้เล่นที่มีสถิติใกล้เคียงกันจะถูกจัดกลุ่มไว้ใกล้กัน ในขณะที่ผู้เล่นที่มีสถิติต่างกันมากจะอยู่ห่างจากกันในเนื้อเรื่อง
โปรดทราบว่าคุณยังสามารถแยกพิกัดที่แน่นอน (x, y) ของผู้เล่นแต่ละคนในพล็อตได้โดยการพิมพ์ fit ซึ่งเป็นชื่อของตัวแปรที่เราจัดเก็บผลลัพธ์ของฟังก์ชัน cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีดำเนินการงานทั่วไปอื่นๆ ใน R:
วิธีทำให้ข้อมูลเป็นมาตรฐานใน R
วิธีศูนย์ข้อมูลใน R
วิธีลบค่าผิดปกติใน R
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม