Pandalar get dummies nasıl kullanılır – pd.get_dummies
İstatistiklerde sıklıkla çalıştığımız veri kümeleri kategorik değişkenleri içerir.
Bunlar isim veya etiket alan değişkenlerdir. Örnekler şunları içerir:
- Medeni durum (“evli”, “bekar”, “boşanmış”)
- Sigara içme durumu (“sigara içen”, “sigara içmeyen”)
- Göz rengi (“mavi”, “yeşil”, “ela”)
- Eğitim düzeyi (örneğin “lise”, “lisans”, “yüksek lisans”)
Makine öğrenimi algoritmalarını ayarlarken ( doğrusal regresyon , lojistik regresyon , rastgele ormanlar vb. gibi), genellikle kategorik değişkenleri, kategorik verileri temsil etmek için kullanılan sayısal değişkenler olan kukla değişkenlere dönüştürürüz.
Örneğin, Gender kategorik değişkenini içeren bir veri kümemiz olduğunu varsayalım. Bu değişkeni bir regresyon modelinde yordayıcı olarak kullanmak için öncelikle onu kukla değişkene dönüştürmek gerekir.
Bu kukla değişkeni oluşturmak için değerlerden birini (“Erkek”) 0’ı, diğer değeri (“Kadın”) 1’i temsil edecek şekilde seçebiliriz:
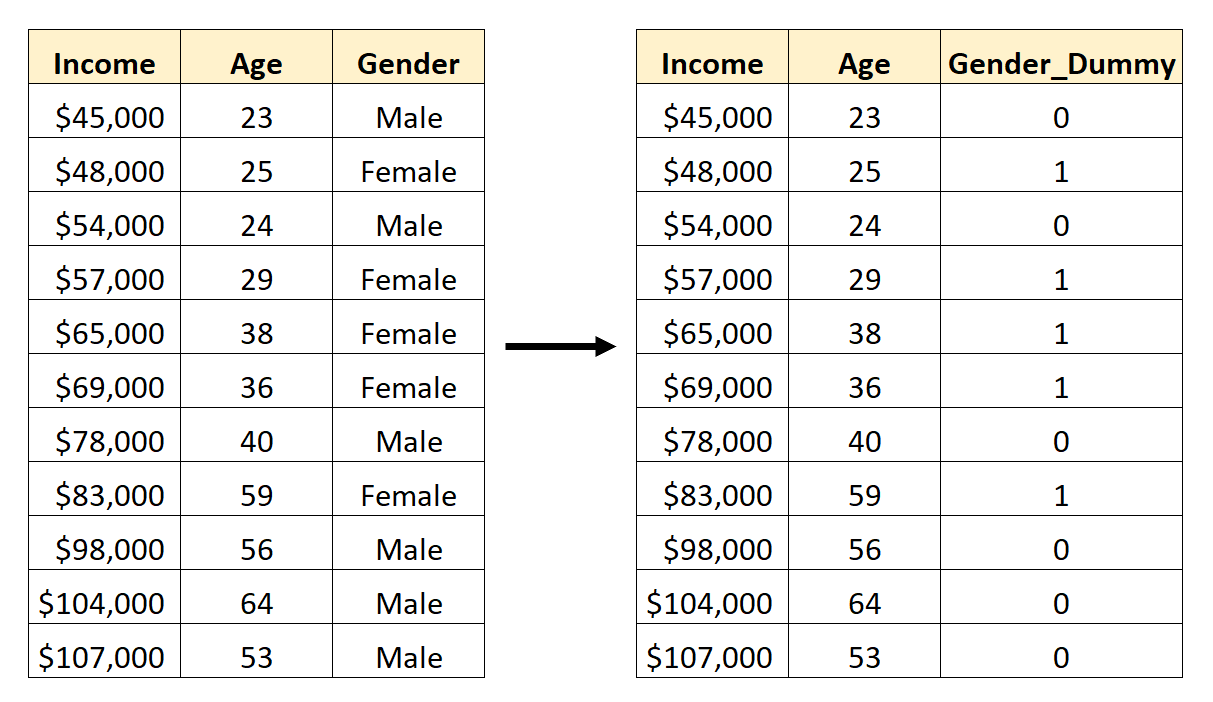
Pandalarda kukla değişkenler nasıl oluşturulur?
Bir panda DataFrame’indeki bir değişken için kuklalar oluşturmak için aşağıdaki temel sözdizimini kullanan pandas.get_dummies() işlevini kullanabiliriz:
pandas.get_dummies(veri, önek=Yok, sütunlar=Yok, drop_first=Yanlış)
Altın:
- data : Pandaların DataFrame adı
- önek : yeni kukla değişken sütununun başına eklenecek bir dize
- sütunlar : Yapay değişkene dönüştürülecek sütunların adı
- drop_first : ilk kukla değişken sütununun bırakılıp bırakılmayacağı
Aşağıdaki örnekler bu fonksiyonun pratikte nasıl kullanılacağını göstermektedir.
Örnek 1: Tek bir kukla değişken oluşturun
Aşağıdaki pandalara sahip olduğumuzu varsayalım DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Cinsiyeti yapay bir değişkene dönüştürmek için pd.get_dummies() işlevini kullanabiliriz:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
Cinsiyet sütunu artık kukla bir değişkendir:
- 0 değeri “Kadın”ı temsil eder
- 1 değeri “Erkek”i temsil eder
Örnek 2: Birden fazla kukla değişken oluşturma
Aşağıdaki pandalara sahip olduğumuzu varsayalım DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Cinsiyet ve üniversiteyi kukla değişkenlere dönüştürmek için pd.get_dummies() işlevini kullanabiliriz:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
Cinsiyet sütunu artık kukla bir değişkendir:
- 0 değeri “Kadın”ı temsil eder
- 1 değeri “Erkek”i temsil eder
Ve üniversite sütunu artık kukla bir değişkendir:
- 0 değeri “Hayır” üniversitesini temsil eder
- 1 değeri üniversiteye “Evet”i temsil eder
Ek kaynaklar
Regresyon analizinde kukla değişkenler nasıl kullanılır?
Kukla değişken tuzağı nedir?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil