Google e-tablolarda logest fonksiyonu nasıl kullanılır (örnekli)
Verilerinize uyan üstel eğrinin formülünü hesaplamak için Google E-Tablolar’daki LOGEST işlevini kullanabilirsiniz.
Eğrinin denklemi aşağıdaki formu alacaktır:
y = b* mx
Bu işlev aşağıdaki temel sözdizimini kullanır:
= LOGEST ( known_data_y, [known_data_x], [b], [verbose] )
Altın:
- bilinen_data_y : Bilinen y değerlerinden oluşan bir dizi
- bilinen_data_x : Bilinen x değerlerinden oluşan bir dizi
- b : İsteğe bağlı argüman. TRUE ise sabit b normal şekilde işlenir. YANLIŞ ise, b sabiti 1’e ayarlanır.
- ayrıntılı : isteğe bağlı argüman. DOĞRU ise ek regresyon istatistikleri döndürülür. YANLIŞ ise ek regresyon istatistikleri döndürülmez.
Aşağıdaki adım adım örnek, bu işlevin pratikte nasıl kullanılacağını gösterir.
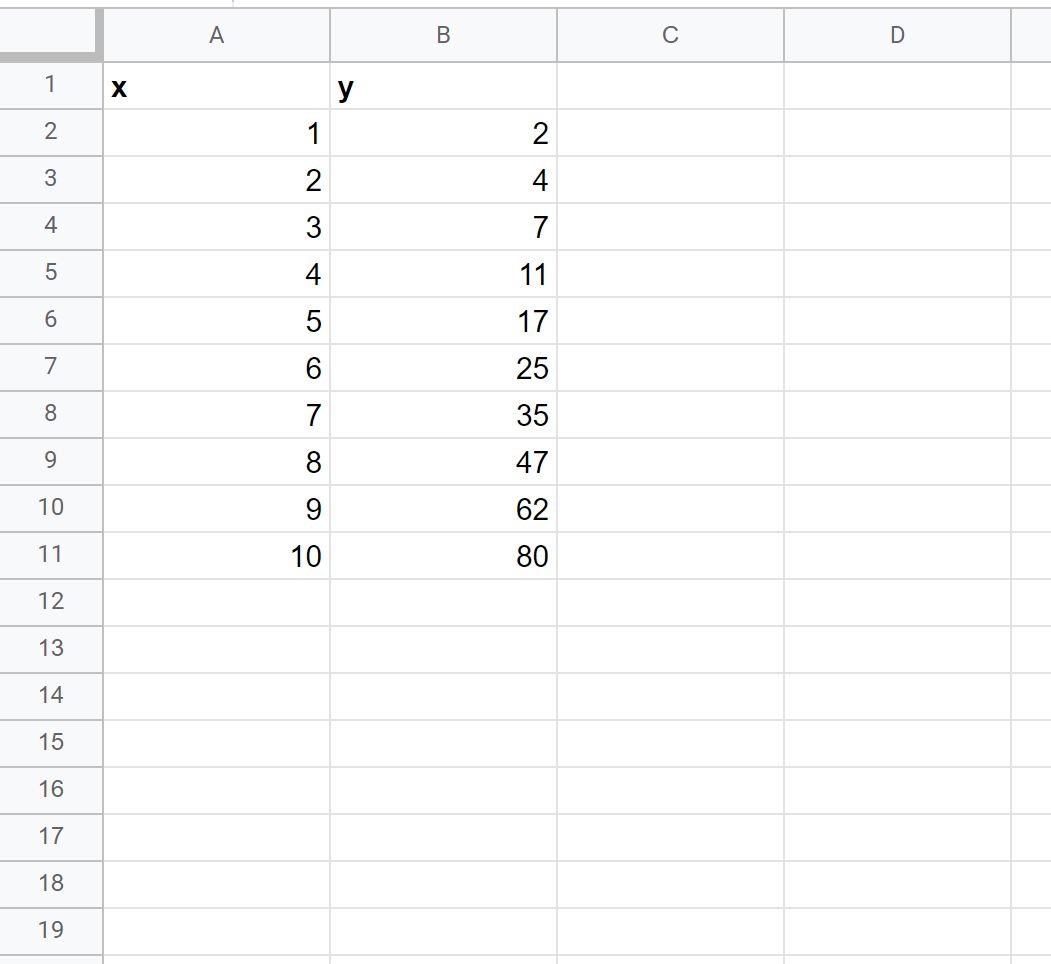
1. Adım: Verileri girin
Öncelikle aşağıdaki veri kümesini Google E-Tablolar’a girelim:
2. Adım: Verileri görselleştirin
Daha sonra, verilerin gerçekten üstel bir eğri izlediğini doğrulamak için x ve y’nin hızlı bir dağılım grafiğini oluşturalım:
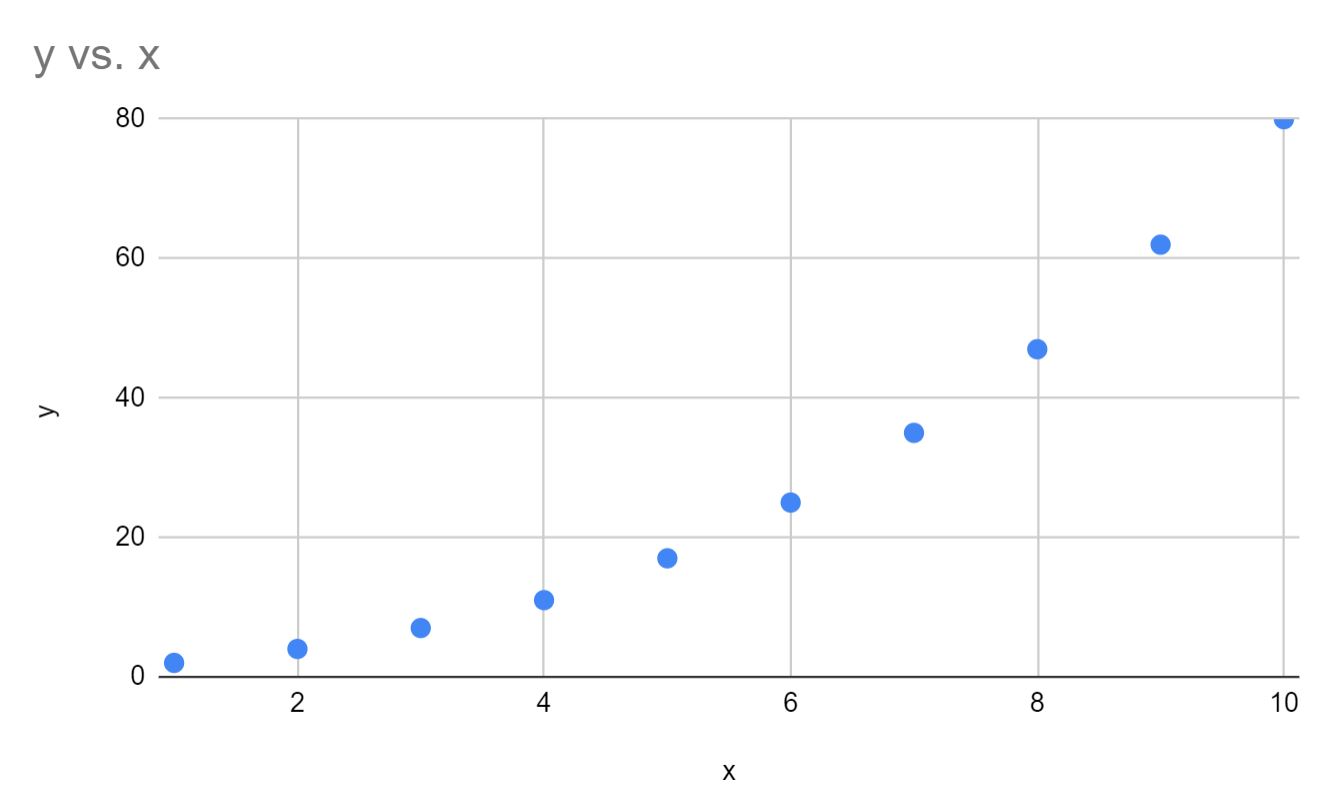
Verilerin gerçekten de üstel bir eğri izlediğini görebiliriz.
Adım 3: Üstel eğrinin formülünü bulmak için LOGEST’i kullanın
Daha sonra üstel eğri formülünü hesaplamak için herhangi bir hücreye aşağıdaki formülü yazabiliriz:
=LOGEST( B2:B11 , A2:A11 )
Aşağıdaki ekran görüntüsü bu formülün pratikte nasıl kullanılacağını göstermektedir:
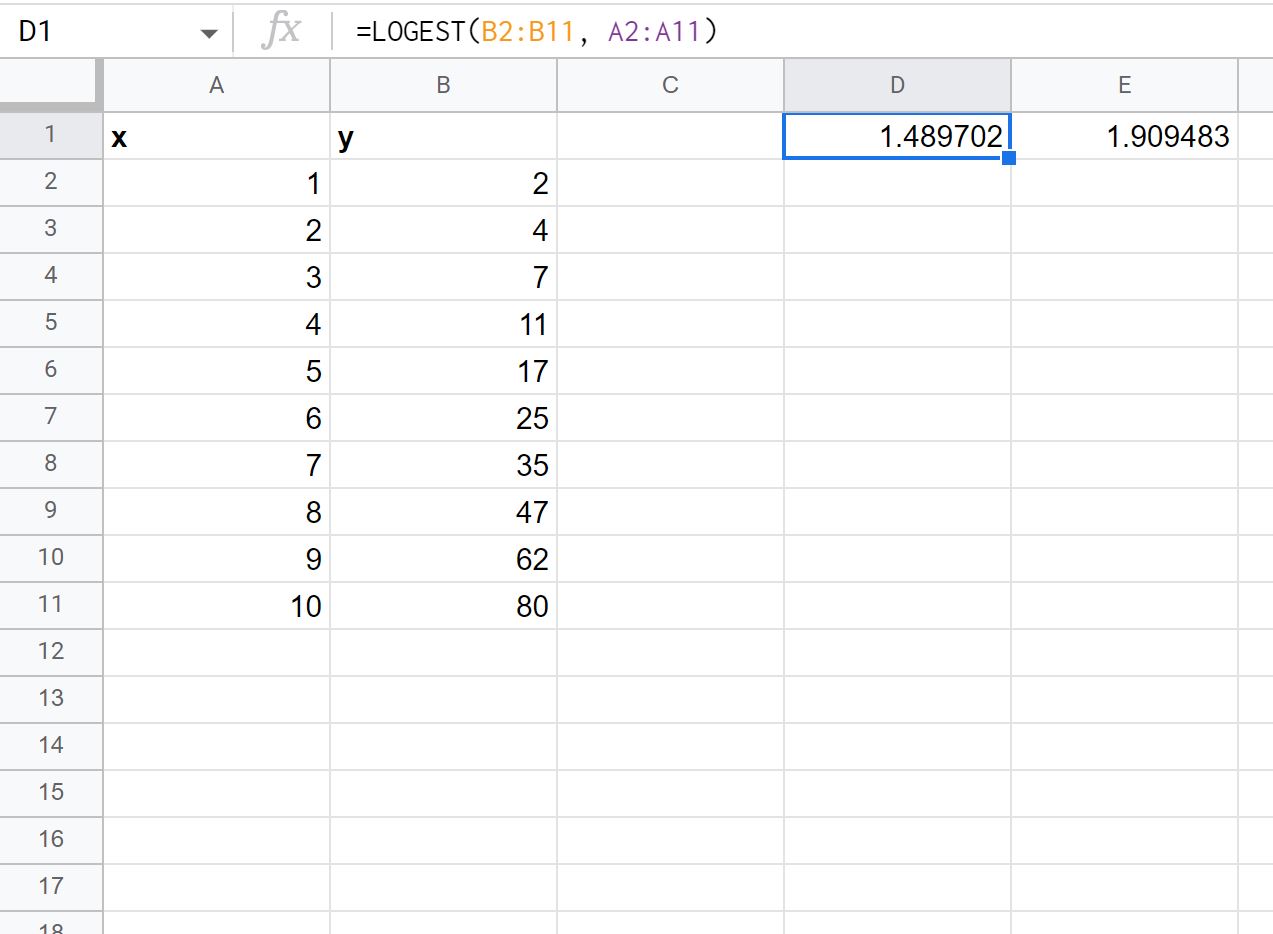
Çıkışın ilk değeri m değerini, ikinci değeri ise b değerini temsil eder:
y = b* mx
Bu üstel eğri formülünü şu şekilde yazabiliriz:
y = 1,909483 * 1,489702x
Daha sonra bu formülü kullanarak x’in değerine bağlı olarak y’nin değerlerini tahmin edebiliriz.
Örneğin, xa’nın değeri 8 ise y’nin değerinin 46,31 olacağını tahmin ederiz:
y = 1,909483 * 1,489702 8 = 46,31
4. Adım (İsteğe bağlı): Ek regresyon istatistiklerini görüntüleyin
Uygun regresyon denklemi için ek regresyon istatistiklerini görüntülemek üzere LOGEST işlevindeki ayrıntılı bağımsız değişken değerini TRUE’ya eşitleyebiliriz:
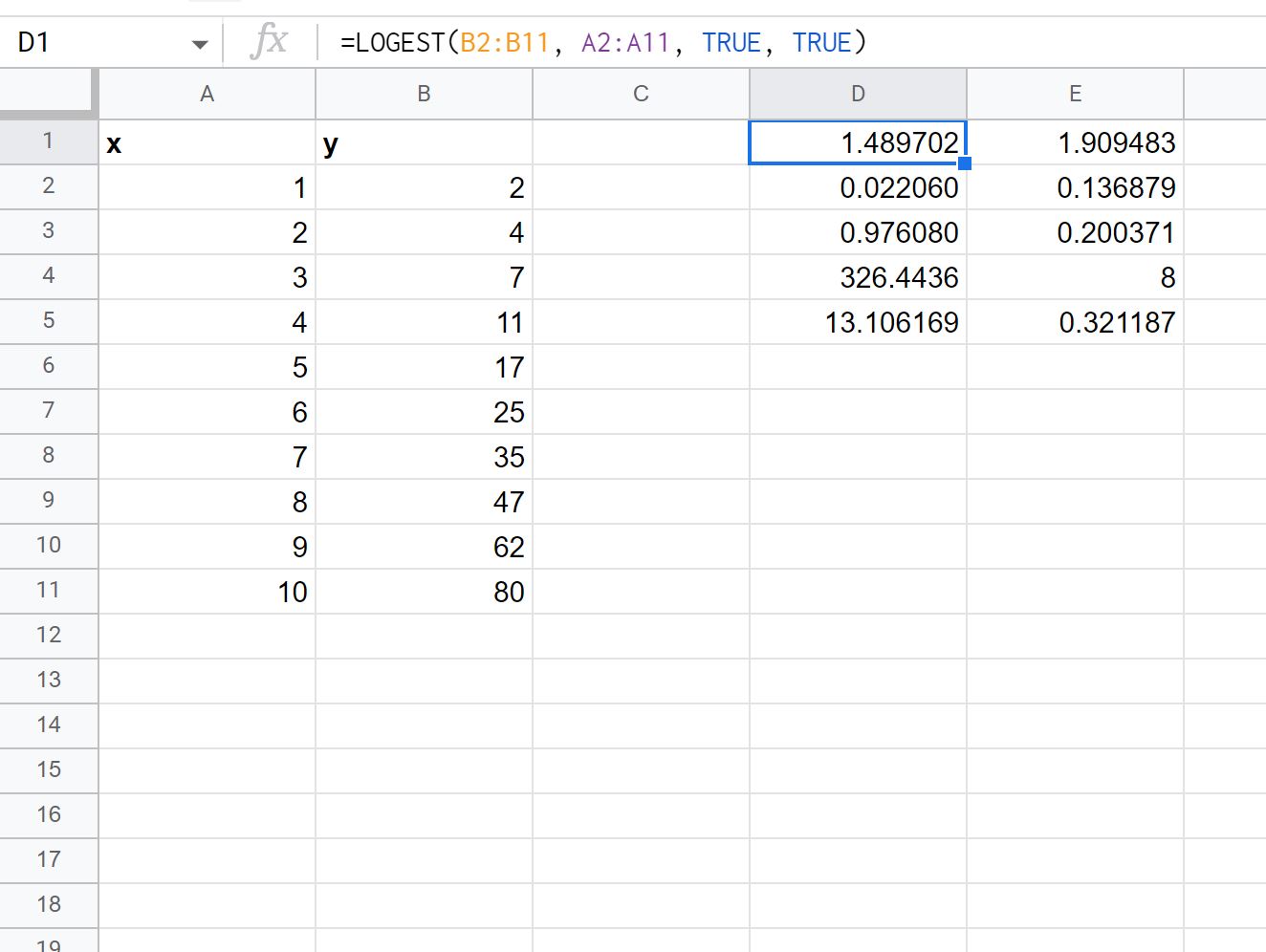
Sonuçtaki her bir değerin nasıl yorumlanacağı aşağıda açıklanmıştır:
- M’nin standart hatası 0,02206’dır .
- b’nin standart hatası 0,136879’dur .
- Modelin R 2’si .97608’dir .
- Y’nin standart hatası 0,200371’dir .
- F istatistiği 326.4436’dır .
- Serbestlik derecesi 8’dir .
- Karelerin regresyon toplamı 13,106169’dur .
- Kalan kareler toplamı 0,321187’dir .
Genel olarak, bu ek istatistiklerde en çok ilgi duyulan ölçü, yordayıcı değişken tarafından açıklanabilen yanıt değişkenindeki varyansın oranını temsil eden R2 değeridir.
R2’nin değeri 0 ila 1 arasında değişebilir.
Bu özel modelin R2’si 1’e yakın olduğundan, bu bize yordayıcı değişken x’in yanıt değişkeni y’nin değerini iyi tahmin ettiğini söyler.
İlgili: İyi bir R-kare değeri nedir?
Ek kaynaklar
Aşağıdaki eğitimlerde Google E-Tablolar’da diğer yaygın işlemlerin nasıl yapılacağı açıklanmaktadır:
Google E-Tablolarda doğrusal regresyon nasıl gerçekleştirilir?
Google E-Tablolar’da polinom regresyonu nasıl gerçekleştirilir?
Google E-Tablolarda R-kare nasıl hesaplanır
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil