Python'da box-cox dönüşümü nasıl gerçekleştirilir?
Box-cox dönüşümü, normal olarak dağıtılmayan bir veri kümesini daha normal olarak dağıtılan bir kümeye dönüştürmek için yaygın olarak kullanılan bir yöntemdir.
Bu yöntemin arkasındaki temel fikir, aşağıdaki formülü kullanarak dönüştürülen verinin normal dağılıma mümkün olduğunca yakın olmasını sağlayacak bir λ değeri bulmaktır:
- y(λ) = (y λ – 1) / λ eğer y ≠ 0 ise
- y(λ) = log(y) eğer y = 0 ise
Python’da scipy.stats.boxcox() fonksiyonunu kullanarak box-cox dönüşümü gerçekleştirebiliriz.
Aşağıdaki örnekte bu fonksiyonun pratikte nasıl kullanılacağı gösterilmektedir.
Örnek: Python’da Box-Cox dönüşümü
Üstel bir dağılımdan rastgele 1000 değer kümesi oluşturduğumuzu varsayalım:
#load necessary packages import numpy as np from scipy. stats import boxcox import seaborn as sns #make this example reproducible n.p. random . seeds (0) #generate dataset data = np. random . exponential (size= 1000 ) #plot the distribution of data values sns. distplot (data, hist= False , kde= True )
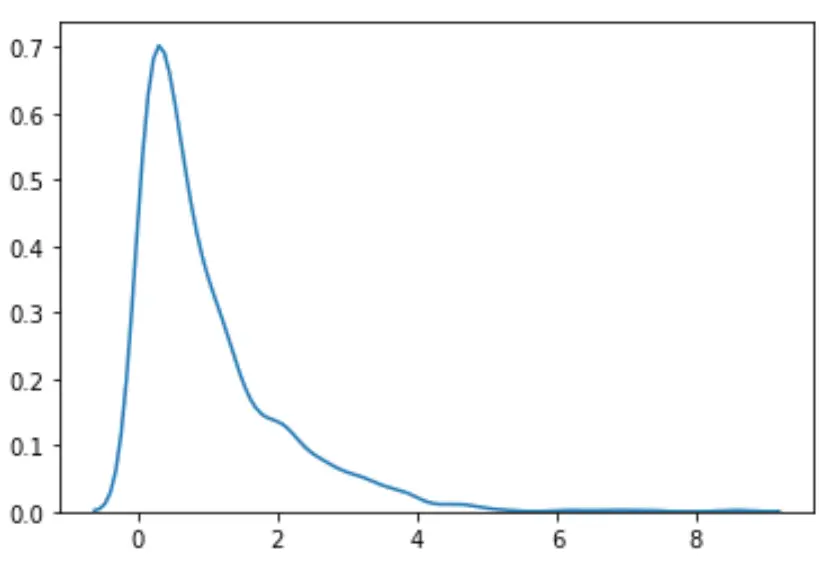
Dağılımın normal görünmediğini görebiliyoruz.
Daha normal bir dağılım üreten optimal lambda değerini bulmak için boxcox() işlevini kullanabiliriz:
#perform Box-Cox transformation on original data transformed_data, best_lambda = boxcox(data) #plot the distribution of the transformed data values sns. distplot (transformed_data, hist= False , kde= True )
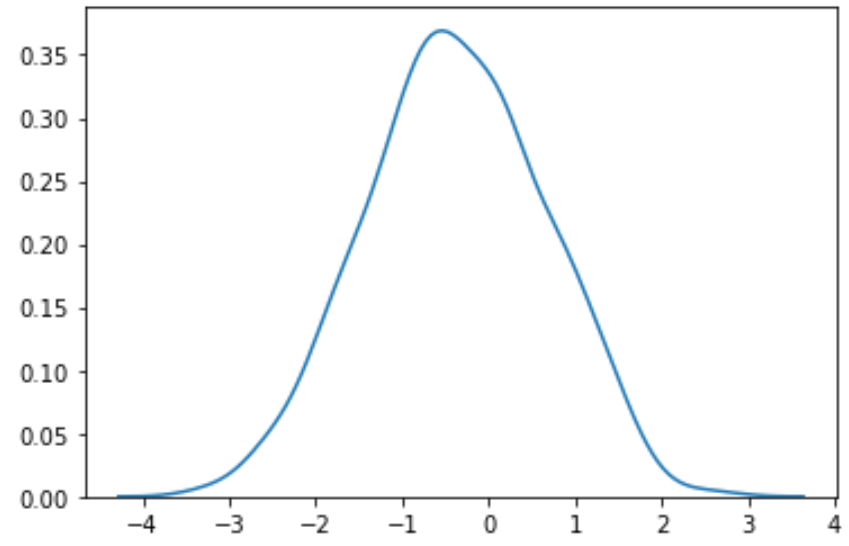
Dönüştürülen verilerin çok daha normal bir dağılım izlediğini görüyoruz.
Box-Cox dönüşümünü gerçekleştirmek için kullanılan tam lambda değerini de bulabiliriz:
#display optimal lambda value print (best_lambda) 0.2420131978174143
Optimum lambdanın 0,242 civarında olduğu bulundu.
Böylece, her bir veri değeri aşağıdaki denklem kullanılarak dönüştürüldü:
Yeni = (eski 0,242 – 1) / 0,242
Orijinal verinin değerleri ile dönüştürülmüş verinin değerlerine bakarak bunu doğrulayabiliriz:
#view first five values of original dataset data[0:5] array([0.79587451, 1.25593076, 0.92322315, 0.78720115, 0.55104849]) #view first five values of transformed dataset transformed_data[0:5] array([-0.22212062, 0.23427768, -0.07911706, -0.23247555, -0.55495228])
Orijinal veri kümesindeki ilk değer 0,79587 idi. Bu değeri dönüştürmek için aşağıdaki formülü uyguladık:
Yeni = (.79587 0.242 – 1) / 0.242 = -0.222
Dönüştürülen veri kümesindeki ilk değerin gerçekten -0,222 olduğunu doğrulayabiliriz.
Ek kaynaklar
Python’da QQ Grafiği Nasıl Oluşturulur ve Yorumlanır
Python’da Shapiro-Wilk Normallik Testi Nasıl Yapılır
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil