Denetimli ve denetimsiz öğrenmeye hızlı bir giriş
Makine öğrenimi alanı, verileri anlamak için kullanılabilecek çok sayıda algoritma içerir. Bu algoritmalar aşağıdaki iki kategoriden birinde sınıflandırılabilir:
1. Denetimli öğrenme algoritmaları: bir veya daha fazla girdiye dayalı olarak bir sonucu tahmin etmek veya tahmin etmek için bir model oluşturmayı içerir.
2. Denetimsiz öğrenme algoritmaları: girdilerden yapı ve ilişkiler bulmayı içerir. “Denetim” çıkışı yoktur.
Bu eğitimde, bu iki algoritma türü arasındaki fark, her birinin çeşitli örnekleriyle birlikte açıklanmaktadır.
Denetimli öğrenme algoritmaları
Denetimli öğrenme algoritması, bir veya daha fazla açıklayıcı değişkene ( X1 , X2 , X3 ,…, Xp ) ve bir yanıt değişkenine (Y) sahip olduğumuzda ve açıklayıcı değişkenler ile açıklayıcı değişkenler arasındaki ilişkiyi tanımlayan bir fonksiyon bulmak istediğimizde kullanılabilir. yanıt değişkeni:
Y = f (X) + ε
burada f, X’in Y hakkında sağladığı sistematik bilgiyi temsil eder ve burada ε, X’ten bağımsız, ortalaması sıfır olan rastgele bir hata terimidir.
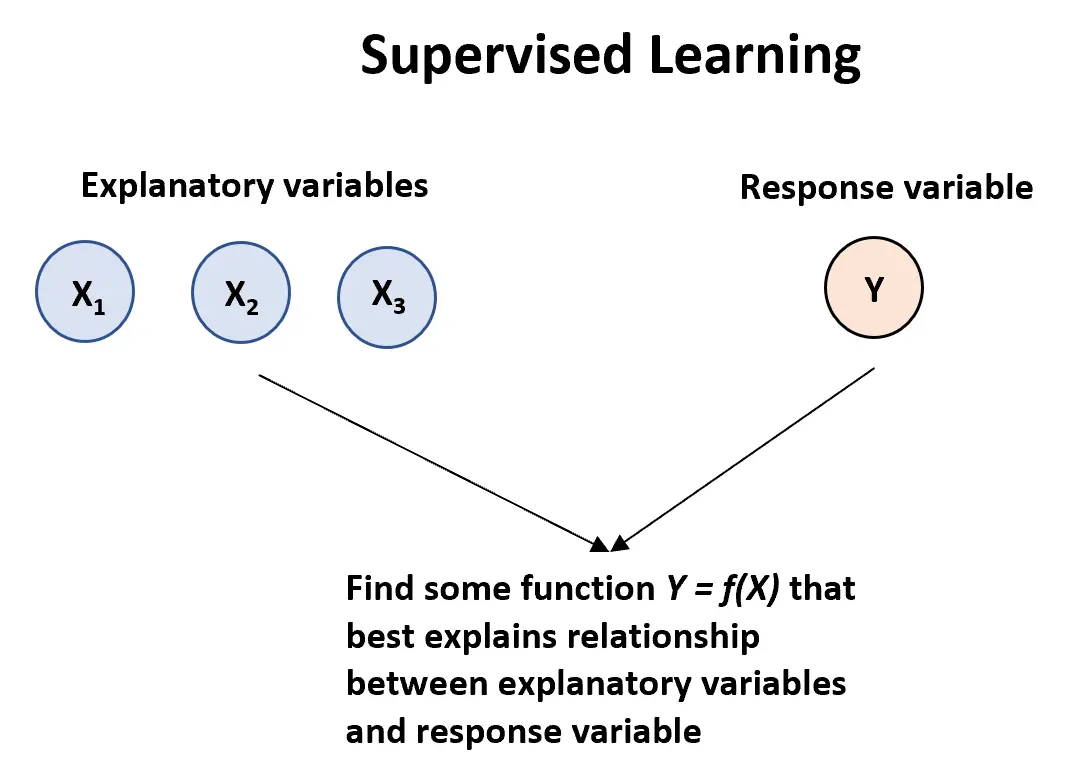
Denetimli öğrenme algoritmalarının iki ana türü vardır:
1. Regresyon: Çıkış değişkeni süreklidir (örneğin ağırlık, boy, zaman vb.)
2. Sınıflandırma: Çıktı değişkeni kategoriktir (örneğin erkek veya kadın, başarı veya başarısızlık, iyi huylu veya kötü huylu, vb.)
Denetimli öğrenme algoritmalarını kullanmamızın iki ana nedeni vardır:
1. Tahmin: Bir yanıt değişkeninin değerini tahmin etmek için sıklıkla bir dizi açıklayıcı değişken kullanırız (örneğin, bir evin fiyatını tahmin etmek için metrekare ve yatak odası sayısını kullanmak).
2. Çıkarım: Açıklayıcı değişkenlerin değeri değiştiğinde bir yanıt değişkeninin nasıl etkilendiğini anlamak ilgimizi çekebilir (örneğin, oda sayısı bir arttığında gayrimenkul fiyatı ortalama ne kadar artar?)
Amacımızın çıkarım mı yoksa tahmin mi (ya da her ikisinin karışımı) olduğuna bağlı olarak f fonksiyonunu tahmin etmek için farklı yöntemler kullanabiliriz. Örneğin, doğrusal modeller daha kolay yorumlama sağlar, ancak yorumlanması zor olan doğrusal olmayan modeller daha doğru tahminler sunabilir.
En sık kullanılan denetimli öğrenme algoritmalarının bir listesi:
- Doğrusal regresyon
- Lojistik regresyon
- Doğrusal diskriminant analizi
- İkinci dereceden diskriminant analizi
- Karar ağaçları
- Naif bayanlar
- Vektör makineleri desteklemek
- Nöral ağlar
Denetimsiz öğrenme algoritmaları
Bir değişken listesine ( X 1 , veri) sahip olduğumuzda denetimsiz bir öğrenme algoritması kullanılabilir.
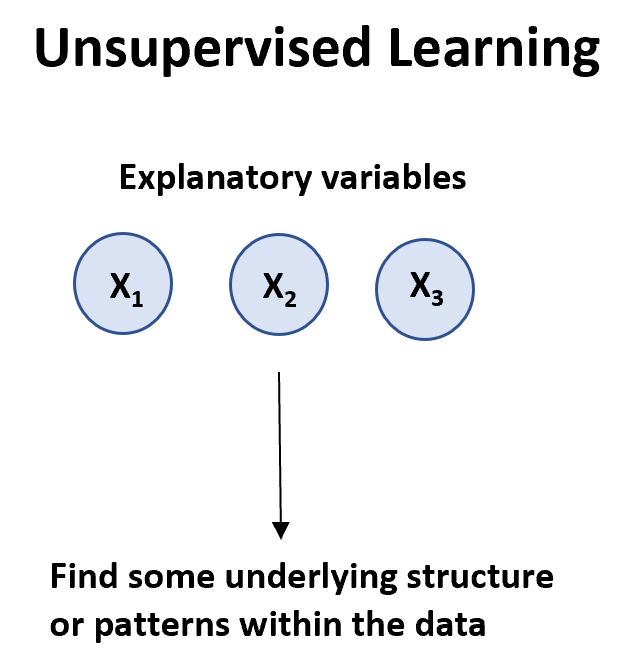
Denetimsiz öğrenme algoritmalarının iki ana türü vardır:
1. Kümeleme: Bu tür algoritmaları kullanarak, bir veri kümesindeki birbirine benzer gözlem “kümelerini” bulmaya çalışırız. Bu genellikle perakende sektöründe, bir işletmenin benzer satın alma alışkanlıklarına sahip müşteri gruplarını belirlemek ve böylece belirli müşteri gruplarını hedef alan spesifik pazarlama stratejileri oluşturmak istediği durumlarda kullanılır.
2. İlişkilendirme: Bu tür algoritmaları kullanarak ilişkilendirmeler kurmak için kullanılabilecek “kurallar” bulmaya çalışıyoruz. Örneğin perakendeciler, “bir müşteri X ürününü satın alırsa Y ürününü de satın alma olasılığının çok yüksek olduğunu” belirten bir ilişkilendirme algoritması geliştirebilir.
En sık kullanılan denetimsiz öğrenme algoritmalarının bir listesi:
- Temel bileşenler Analizi
- K-kümeleme anlamına gelir
- K-medoidlerin gruplandırılması
- Hiyerarşik sınıflandırma
- Öncelikli bir algoritma
Özet: Denetimli veya denetimsiz öğrenme
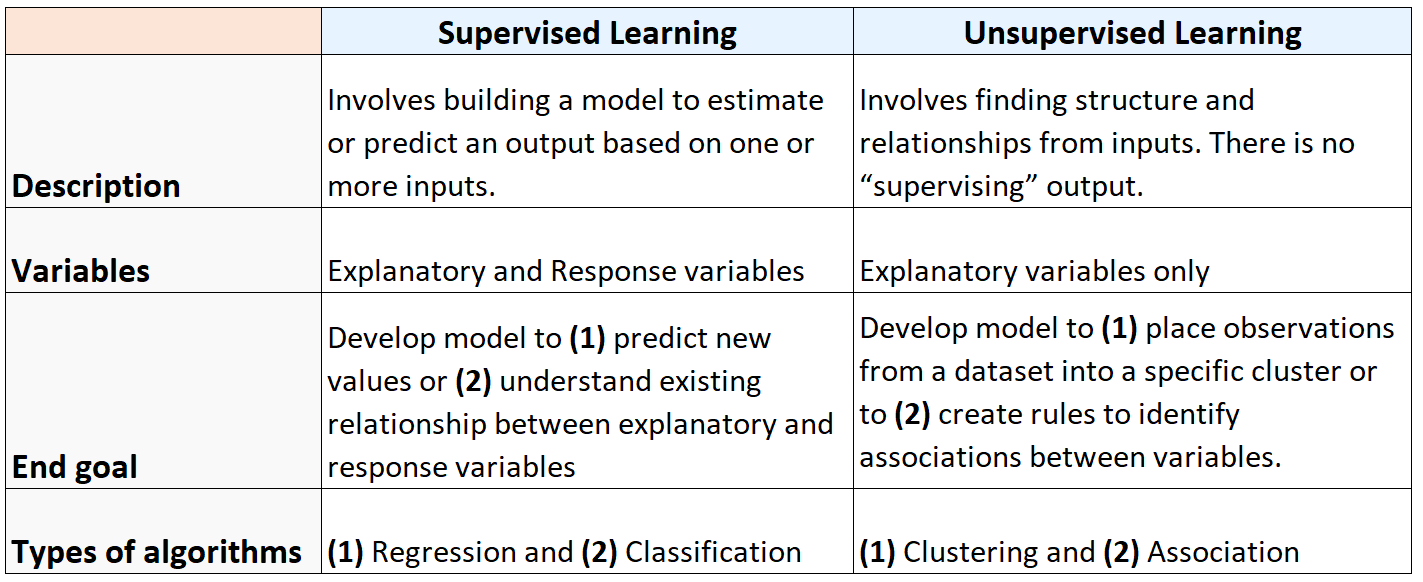
Aşağıdaki tabloda denetimli ve denetimsiz öğrenme algoritmaları arasındaki farklar özetlenmektedir:
Aşağıdaki şemada makine öğrenimi algoritmalarının türleri özetlenmektedir:

yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil