Ggplot2'deki özelliklerin sırası nasıl değiştirilir (örnekle)
ggplot2’deki özelliklerin sırasını belirtmek için aşağıdaki temel sözdizimini kullanabilirsiniz:
p+
facet_grid(~factor(my_variable, levels=c(' val1 ', ' val2 ', ' val3 ', ...)))
Aşağıdaki örnek, bu sözdiziminin pratikte nasıl kullanılacağını gösterir.
Örnek: ggplot2’deki özelliklerin sırasını değiştirme
R’de aşağıdaki veri çerçevesine sahip olduğumuzu varsayalım:
#create data frame
df <- data. frame (team=c('A', 'A', 'B', 'B', 'C', 'C', 'D', 'D'),
points=c(8, 14, 20, 22, 25, 29, 30, 31),
assists=c(10, 5, 5, 3, 8, 6, 9, 12))
#view data frame
df
team points assists
1 to 8 10
2 to 14 5
3 B 20 5
4 B 22 3
5 C 25 8
6 C 29 6
7 D 30 9
8 D 31 12
Aşağıdaki kod, her takım için asistlerin ve puanların dağılım grafiğini görüntüleyen bir tablo oluşturmak için facet_grid() işlevinin nasıl kullanılacağını gösterir:
library (ggplot2)
#create multiple scatter plots using facet_grid
ggplot(df, aes (assists, points)) +
geom_point() +
facet_grid(.~team)
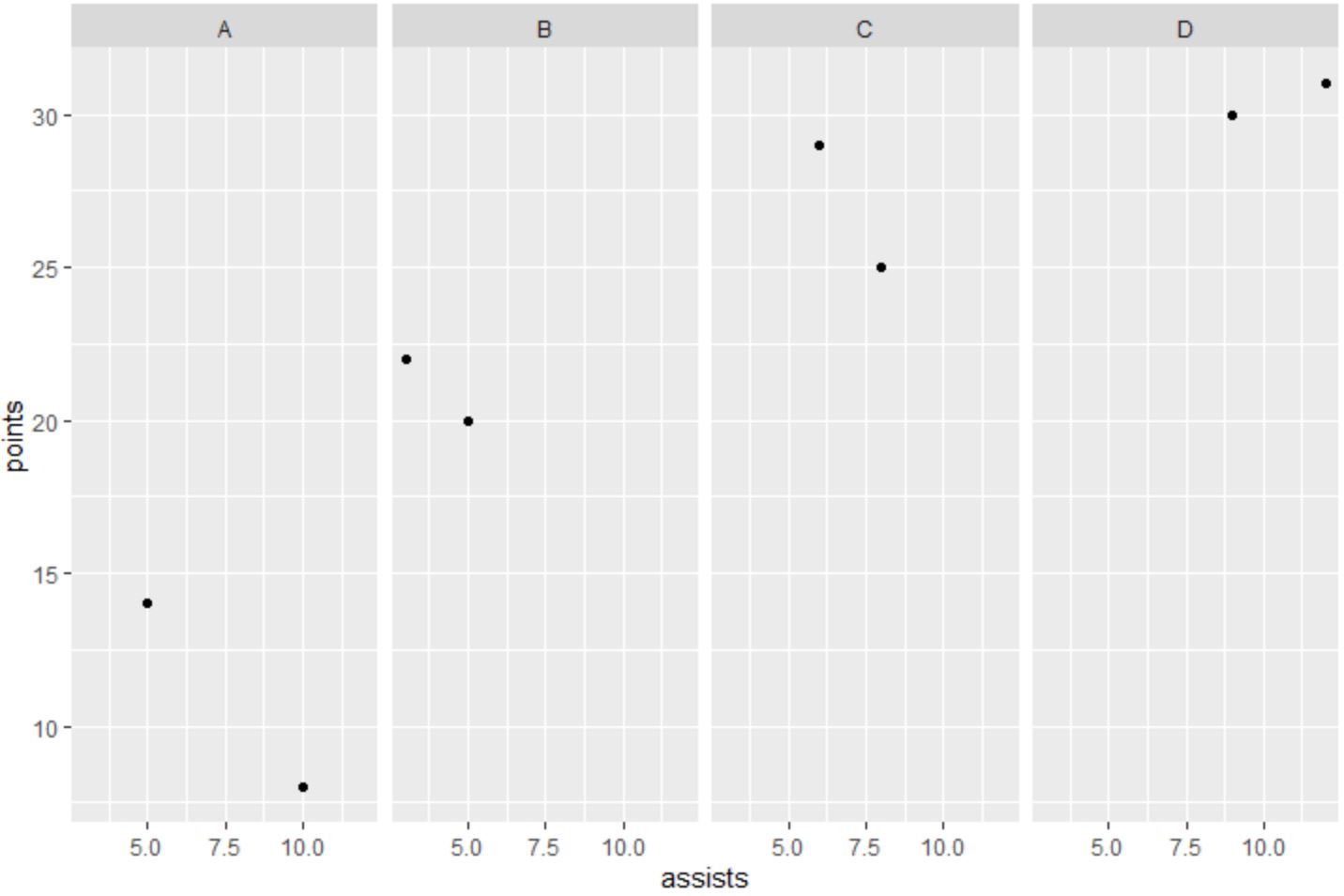
Varsayılan olarak ggplot2, dağılım grafiklerini veri çerçevesinin takım değişkeninde ilk önce görünen değerlere göre sıralar.
Bununla birlikte, takımı bir faktör değişkenine dönüştürebilir ve ekiplerin olay örgüsüne yerleştirilmesi gereken sırayı belirtmek için düzeyler argümanını kullanabiliriz:
library (ggplot2)
#create multiple scatter plots using facet_grid with specific order
ggplot(df, aes (assists, points)) +
geom_point() +
facet_grid(~factor(team, levels=c(' C ', ' D ', ' A ', ' B ')))
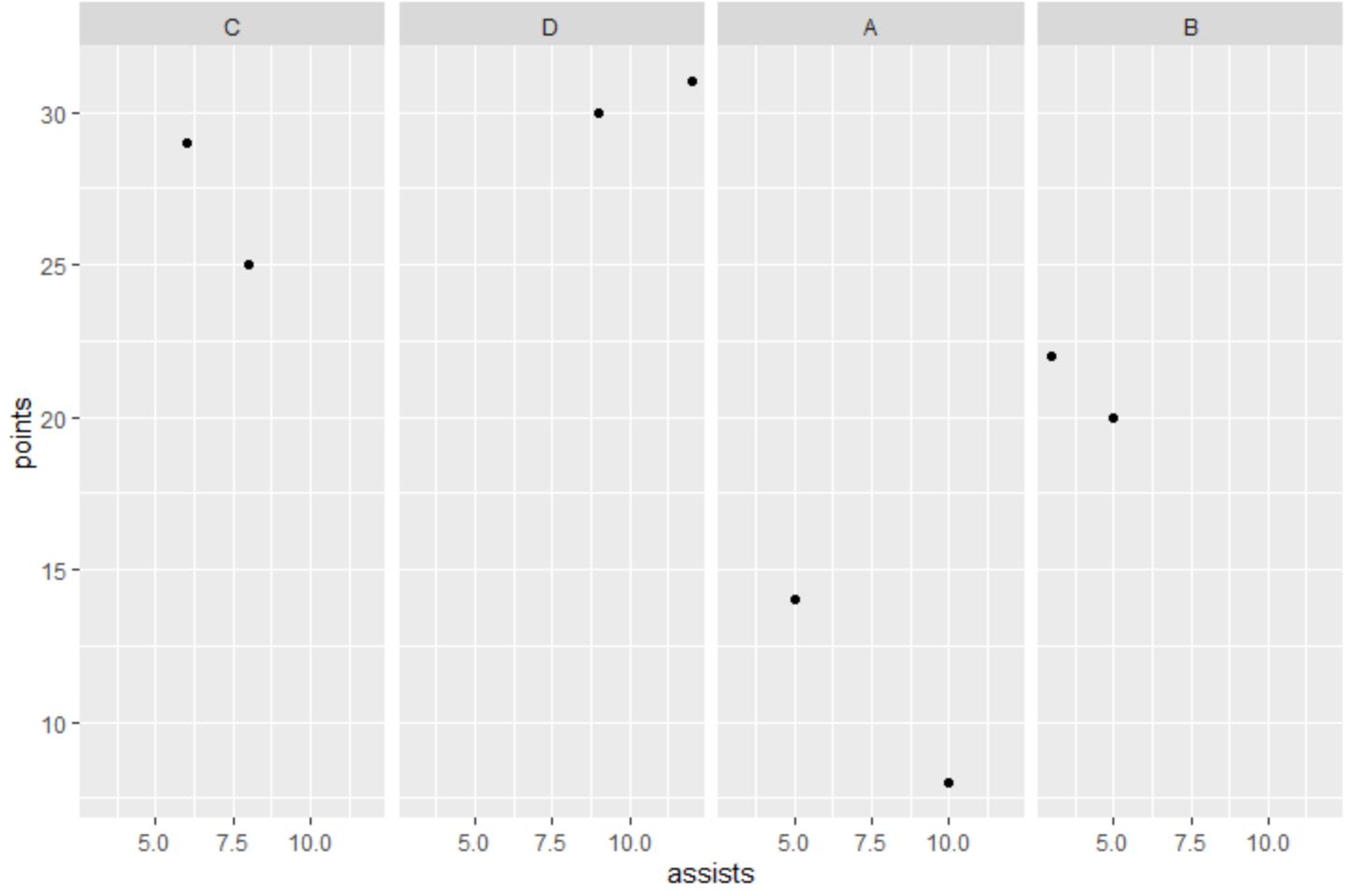
Nokta bulutlarının artık seviyeler argümanında belirttiğimiz sıraya göre sıralandığına dikkat edin: C, D, A, B.
Bu yaklaşımı kullanmanın avantajı, aslında temel verileri değiştirmememizdir.
Bunun yerine sadece facet_grid() fonksiyonundaki seviyeleri değiştiriyoruz.
Ek kaynaklar
Aşağıdaki eğitimler ggplot2’de diğer genel görevlerin nasıl gerçekleştirileceğini açıklamaktadır:
Ggplot2’de yazı tipi boyutu nasıl değiştirilir?
Ggplot2’de bir efsane nasıl kaldırılır
Ggplot2’de eksen etiketleri nasıl döndürülür
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil