Stata'da hiyerarşik regresyon nasıl gerçekleştirilir?
Hiyerarşik regresyon, birkaç farklı doğrusal modeli karşılaştırmak için kullanabileceğimiz bir tekniktir.
Temel fikir, ilk önce tek bir açıklayıcı değişkenle doğrusal bir regresyon modeli uydurmamızdır. Daha sonra ek bir açıklayıcı değişken kullanarak başka bir regresyon modeli uyduruyoruz. İkinci modeldeki R-kare (tepki değişkenindeki açıklayıcı değişkenler tarafından açıklanabilen varyans oranı) önceki modeldeki R-kareden önemli ölçüde yüksekse bu, ikinci modelin daha iyi olduğu anlamına gelir.
Daha sonra ek regresyon modellerini daha açıklayıcı değişkenlerle uydurma sürecini tekrarlıyoruz ve yeni modellerin önceki modellere göre bir gelişme sağlayıp sağlamadığını görüyoruz.
Bu eğitimde Stata’da hiyerarşik regresyonun nasıl gerçekleştirileceğine ilişkin bir örnek sunulmaktadır.
Örnek: Stata’da hiyerarşik regresyon
Stata’da hiyerarşik regresyonun nasıl gerçekleştirileceğini göstermek için auto adı verilen yerleşik bir veri kümesi kullanacağız. Öncelikle komut kutusuna aşağıdakini yazarak veri kümesini yükleyin:
sistemin otomatik kullanımı
Aşağıdaki komutu kullanarak verilerin hızlı bir özetini alabiliriz:
özetlemek
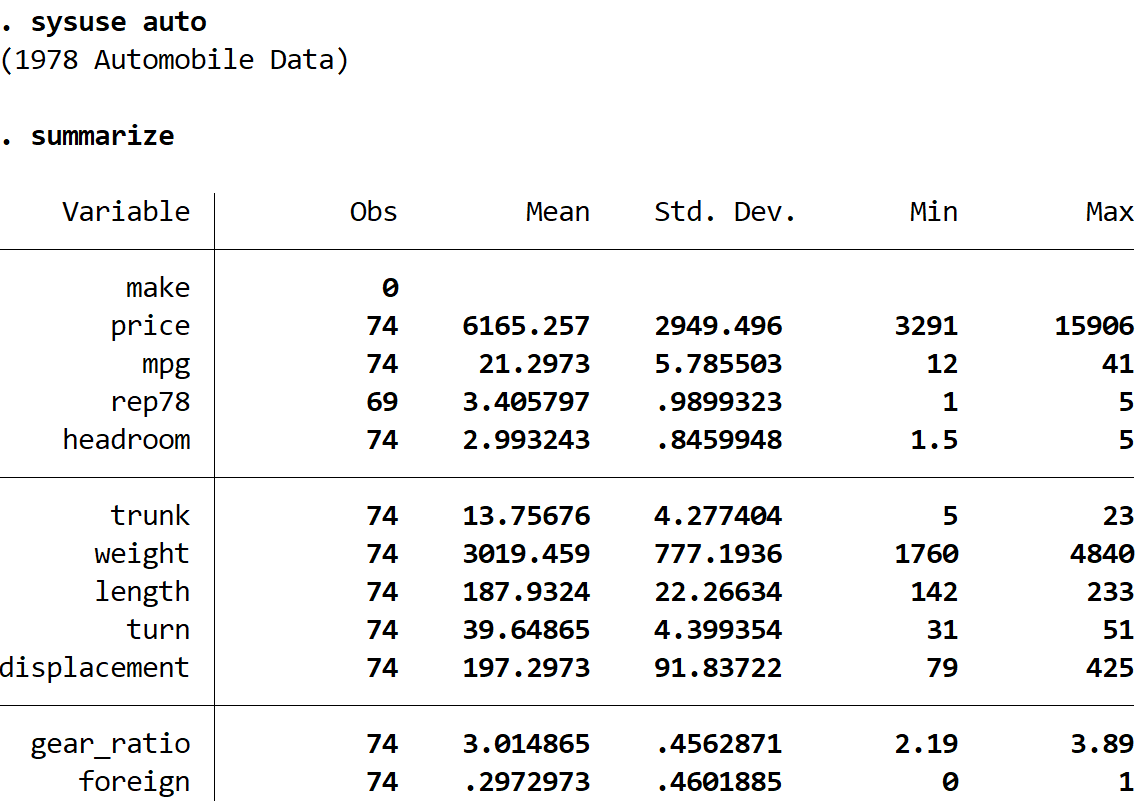
Veri setinin toplamda 74 araba için 12 farklı değişkene ilişkin bilgi içerdiğini görüyoruz.
Aşağıdaki üç doğrusal regresyon modelini yerleştireceğiz ve sonraki her modelin önceki modele göre önemli bir gelişme sağlayıp sağlamadığını görmek için hiyerarşik regresyon kullanacağız:
Model 1: fiyat = kesişim + mpg
Model 2: fiyat = kesişim noktası + mpg + ağırlık
Model 3: fiyat = kesişim noktası + mpg + ağırlık + dişli oranı
Stata’da hiyerarşik regresyon yapabilmek için öncelikle Hireg paketini kurmamız gerekecek. Bunu yapmak için Komut kutusuna aşağıdakini yazın:
Hireg’i bul
Görünen pencerede https://fmwww.bc.edu/RePEc/bocode/h adresinden Hireg’e tıklayın.
Bir sonraki pencerede yüklemek için burayı tıklayın yazan bağlantıya tıklayın.
Paket saniyeler içinde kurulacaktır. Daha sonra hiyerarşik bir regresyon gerçekleştirmek için aşağıdaki komutu kullanacağız:
kiralama fiyatı (mpg) (ağırlık) (gear_ratio)
İşte bunun Stata’dan yapmasını istediği şey:
- Her modelde fiyatı yanıt değişkeni olarak kullanarak hiyerarşik bir regresyon gerçekleştirin.
- İlk model için açıklayıcı değişken olarak mpg’yi kullanın.
- İkinci model için, ek bir açıklayıcı değişken olarak ağırlığı ekleyin.
- Üçüncü model için başka bir açıklayıcı değişken olarak vites_ratio’yu ekleyin.
İşte ilk modelin sonucu:
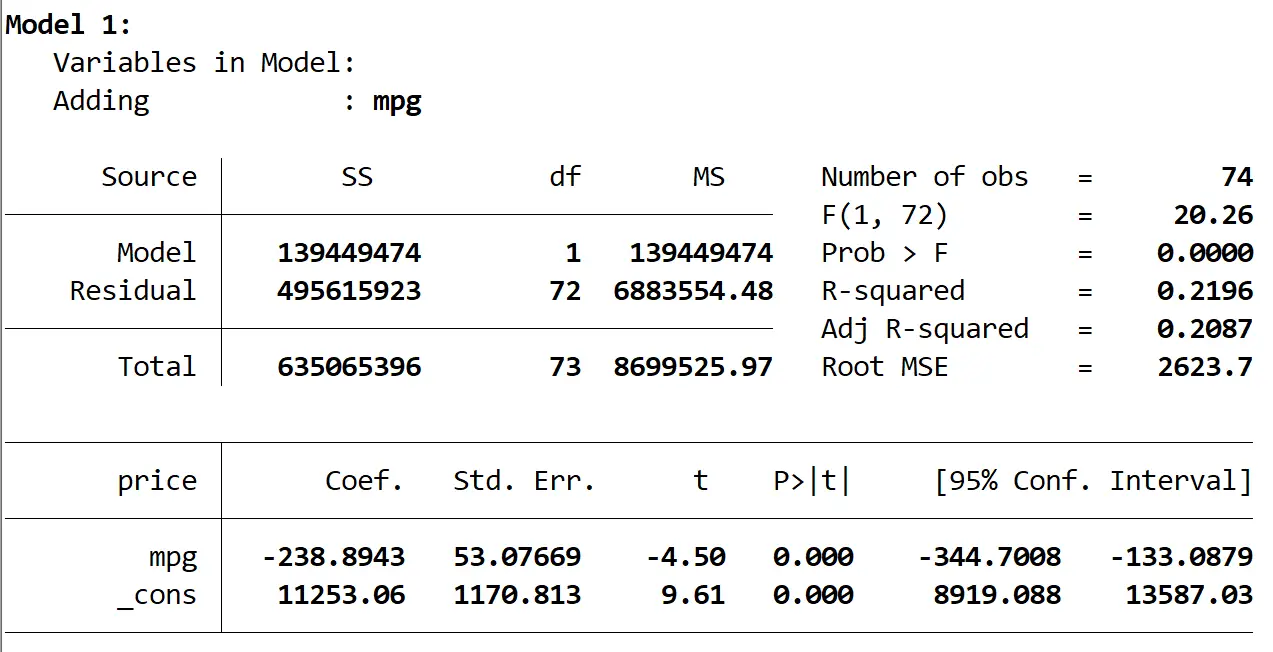
Modelin R-karesinin 0,2196 olduğunu ve modelin genel p-değerinin (Prob > F) 0,0000 olduğunu görüyoruz; bu da α = 0,05’te istatistiksel olarak anlamlıdır.
Daha sonra ikinci modelin sonucunu görüyoruz:
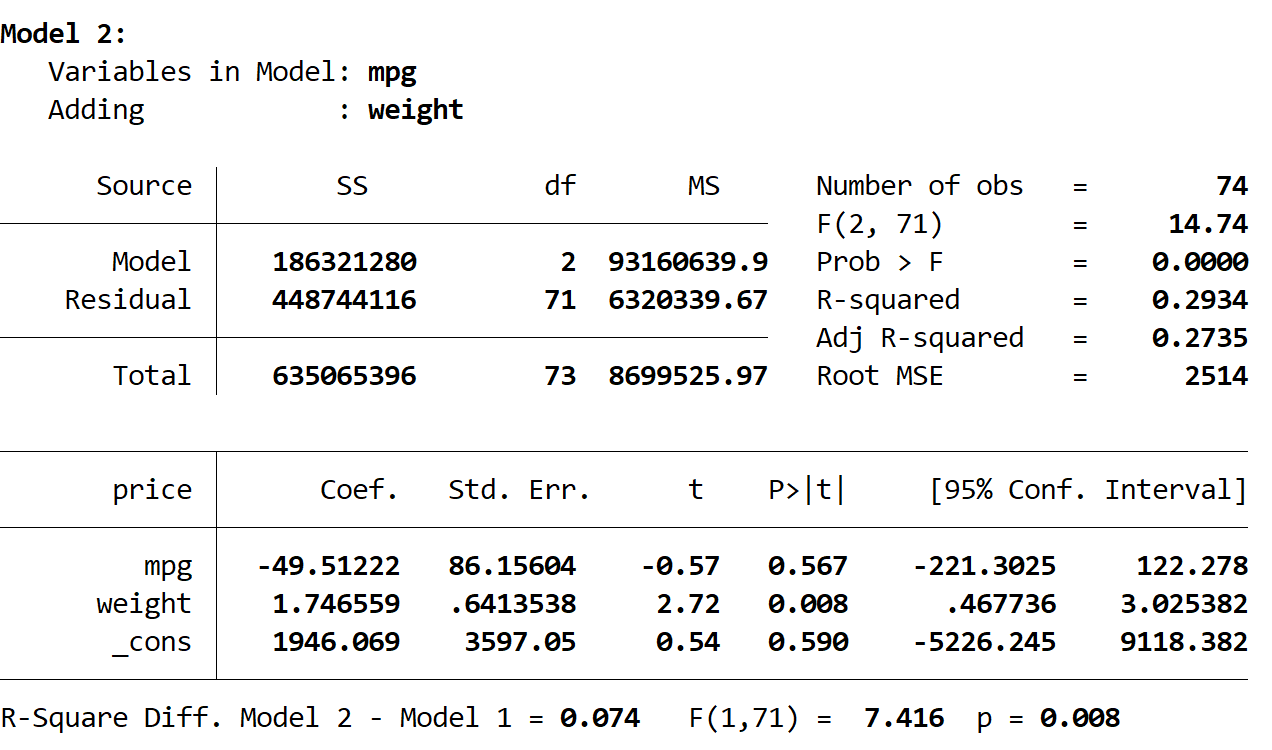
Bu modelin R karesi 0,2934 olup, ilk modelinkinden daha büyüktür. Bu farkın istatistiksel olarak anlamlı olup olmadığını belirlemek için Stata, sonucun altında aşağıdaki sayıları veren bir F testi gerçekleştirdi:
- İki model arasındaki R kare farkı = 0,074
- Fark için F istatistiği = 7,416
- F istatistiğinin karşılık gelen p değeri = 0,008
P değeri 0,05’ten küçük olduğundan ikinci modelde birinci modele göre istatistiksel olarak anlamlı bir iyileşme olduğu sonucuna varıyoruz.
Son olarak üçüncü modelin sonucunu görebiliriz:
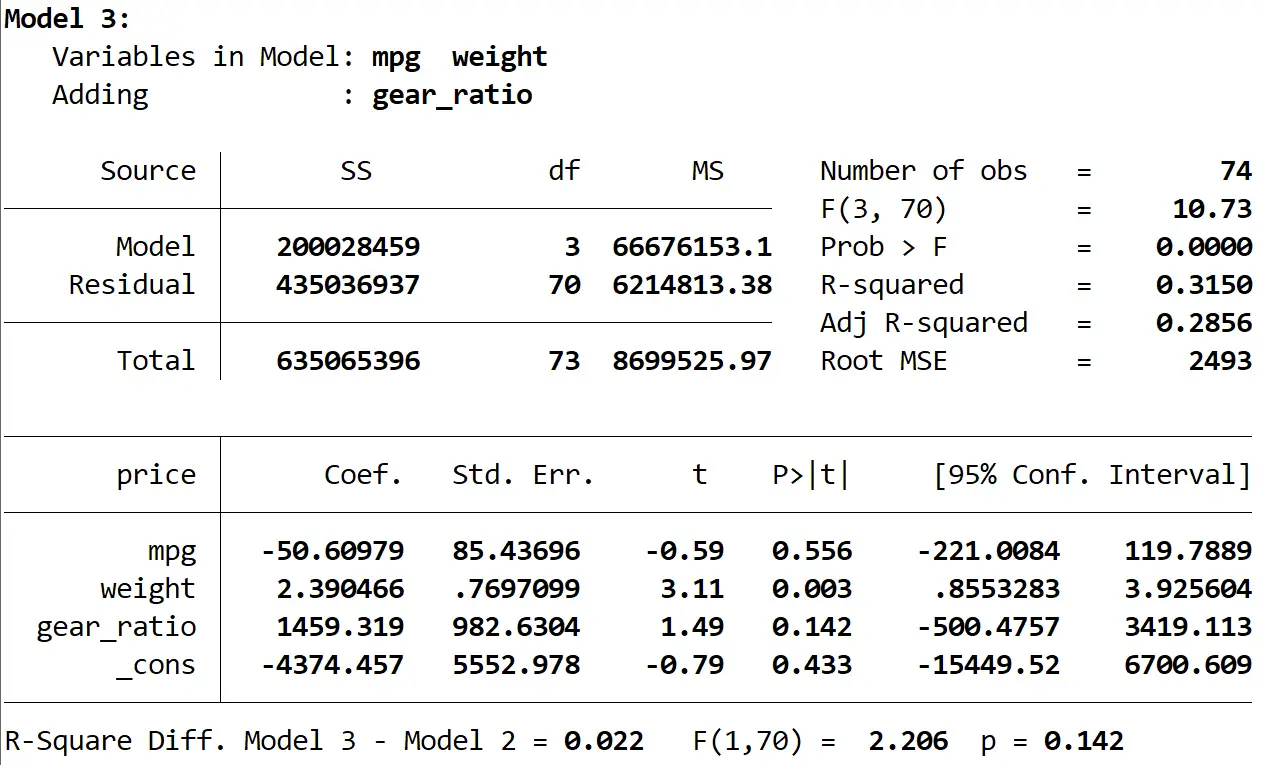
Bu modelin R karesi 0,3150 olup, ikinci modelinkinden daha büyüktür. Bu farkın istatistiksel olarak anlamlı olup olmadığını belirlemek için Stata, sonucun altında aşağıdaki sayıları veren bir F testi gerçekleştirdi:
- İki model arasındaki R kare farkı = 0,022
- Fark için F istatistiği = 2,206
- F istatistiğinin karşılık gelen p değeri = 0,142
P değeri 0,05’ten küçük olmadığı için üçüncü modelin ikinci modele göre bir iyileşme sağladığını söylemek için yeterli kanıta sahip değiliz.
Sonucun en sonunda Stata’nın sonuçların bir özetini sunduğunu görebiliriz:

Bu özel örnekte, Model 2’nin Model 1’e göre önemli bir gelişme sağladığı ancak Model 3’ün Model 2’ye göre önemli bir gelişme sağlamadığı sonucuna varacağız.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil