Python'da k-means kümelemesi: adım adım örnek
Makine öğreniminde en yaygın kümeleme algoritmalarından biri k-ortalama kümeleme olarak bilinir.
K-ortalama kümelemesi, bir veri kümesindeki her gözlemi K kümesinden birine yerleştirdiğimiz bir tekniktir.
Nihai amaç, her küme içindeki gözlemlerin birbirine oldukça benzer olduğu, farklı kümelerdeki gözlemlerin ise birbirinden oldukça farklı olduğu K kümeye sahip olmaktır.
Uygulamada, K-aracı kümelemesini gerçekleştirmek için aşağıdaki adımları kullanırız:
1. K için bir değer seçin.
- Öncelikle veride kaç tane küme tanımlamak istediğimize karar vermemiz gerekiyor. Çoğunlukla K için birkaç farklı değeri test etmemiz ve belirli bir problem için hangi sayıda kümenin en anlamlı göründüğünü görmek için sonuçları analiz etmemiz gerekir.
2. Her gözlemi rastgele olarak 1’den K’ye kadar bir başlangıç kümesine atayın.
3. Küme atamalarının değişmesi durana kadar aşağıdaki prosedürü uygulayın.
- Her K kümesi için kümenin ağırlık merkezini hesaplayın. Bu basitçe k’inci kümenin gözlemleri için p- ortalama özelliklerinin vektörüdür.
- Her gözlemi en yakın merkeze sahip kümeye atayın. Burada en yakın , Öklid mesafesi kullanılarak tanımlanır.
Aşağıdaki adım adım örnek, sklearn modülündeki KMeans işlevini kullanarak Python’da k-means kümelemesinin nasıl gerçekleştirileceğini gösterir.
Adım 1: Gerekli modülleri içe aktarın
Öncelikle k-means kümelemesini gerçekleştirmek için ihtiyaç duyacağımız tüm modülleri içe aktaracağız:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
Adım 2: DataFrame’i oluşturun
Daha sonra 20 farklı basketbol oyuncusu için aşağıdaki üç değişkeni içeren bir DataFrame oluşturacağız:
- puan
- yardım
- sıçramalar
Aşağıdaki kod, bu pandaların DataFrame’inin nasıl oluşturulacağını gösterir:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#view first five rows of DataFrame
print ( df.head ())
points assists rebounds
0 18.0 3.0 15
1 NaN 3.0 14
2 19.0 4.0 14
3 14.0 5.0 10
4 14.0 4.0 8
Benzer aktörleri bu üç ölçüme göre gruplandırmak için k-means kümelemesini kullanacağız.
3. Adım: DataFrame’i temizleyin ve hazırlayın
Daha sonra aşağıdaki adımları gerçekleştireceğiz:
- Herhangi bir sütunda NaN değerlerine sahip satırları bırakmak için dropna() işlevini kullanın
- Her değişkeni ortalama 0 ve standart sapma 1 olacak şekilde ölçeklendirmek için StandardScaler() öğesini kullanın.
Aşağıdaki kod bunun nasıl yapılacağını gösterir:
#drop rows with NA values in any columns df = df. dropna () #create scaled DataFrame where each variable has mean of 0 and standard dev of 1 scaled_df = StandardScaler(). fit_transform (df) #view first five rows of scaled DataFrame print (scaled_df[:5]) [[-0.86660275 -1.22683918 1.72722524] [-0.72081911 -0.96077767 1.45687694] [-1.44973731 -0.69471616 0.37548375] [-1.44973731 -0.96077767 -0.16521285] [-1.88708823 -0.16259314 1.45687694]]
Not : k-means algoritmasını ayarlarken her değişkenin aynı öneme sahip olması için ölçeklendirme kullanıyoruz. Aksi takdirde en geniş aralıklara sahip değişkenlerin etkisi çok fazla olacaktır.
Adım 4: Optimum Küme Sayısını Bulun
Python’da k-means kümelemesini gerçekleştirmek için sklearn modülünden KMeans fonksiyonunu kullanabiliriz.
Bu işlev aşağıdaki temel sözdizimini kullanır:
KMeans(init=’rastgele’, n_clusters=8, n_init=10, random_state=Yok)
Altın:
- init : Başlatma tekniğini kontrol eder.
- n_clusters : gözlemlerin yerleştirileceği kümelerin sayısı.
- n_init : Gerçekleştirilecek başlatma sayısı. Varsayılan, k-means algoritmasını 10 kez çalıştırmak ve en düşük SSE’ye sahip olanı döndürmektir.
- random_state : Algoritma sonuçlarının tekrarlanabilir olmasını sağlamak için seçebileceğiniz bir tamsayı değeri.
Bu işlevin en önemli argümanı, gözlemlerin kaç kümeye yerleştirileceğini belirten n_clusters’tır.
Ancak, kaç kümenin optimal olduğunu önceden bilmiyoruz, bu nedenle küme sayısını ve modelin SSE’sini (hataların karelerinin toplamı) gösteren bir grafik oluşturmamız gerekiyor.
Tipik olarak, bu tür bir çizim oluşturduğumuzda, karelerin toplamının “bükülmeye” veya düzleşmeye başladığı bir “diz” ararız. Bu genellikle optimum küme sayısıdır.
Aşağıdaki kod, x ekseninde küme sayısını ve y ekseninde SSE’yi görüntüleyen bu tür grafiğin nasıl oluşturulacağını gösterir:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
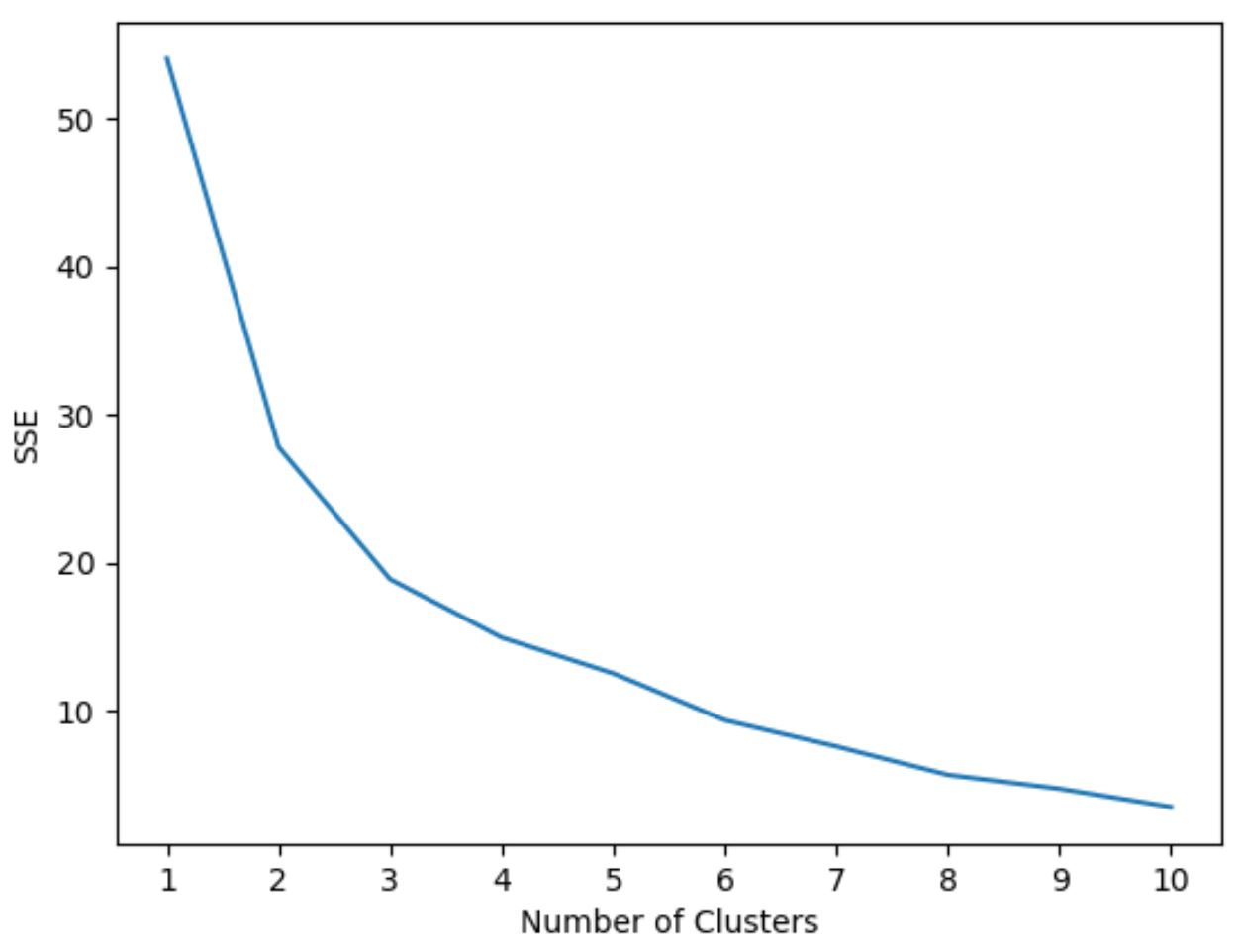
Bu grafikte k = 3 kümede bükülme veya “diz” olduğu görülmektedir.
Dolayısıyla bir sonraki adımda k-ortalama kümeleme modelimizi yerleştirirken 3 küme kullanacağız.
Not : Gerçek dünyada, kullanılacak küme sayısını seçmek için bu plan ve etki alanı uzmanlığının bir kombinasyonunun kullanılması önerilir.
Adım 5: Optimal K ile K-Means Kümelemesini Gerçekleştirin
Aşağıdaki kod, k /3 için en uygun değeri kullanarak veri kümesinde k-ortalamalı kümelemenin nasıl gerçekleştirileceğini gösterir:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Ortaya çıkan tablo, DataFrame’deki her gözlem için küme atamalarını gösterir.
Bu sonuçların yorumlanmasını kolaylaştırmak için DataFrame’e her oyuncunun küme atamasını gösteren bir sütun ekleyebiliriz:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
Küme sütunu, her oyuncunun atandığı küme numarasını (0, 1 veya 2) içerir.
Aynı kümeye ait oyuncular sayı , asist ve ribaund sütunlarında yaklaşık olarak benzer değerlere sahiptir.
Not : Sklearn’in KMeans işlevine ilişkin tüm belgeleri burada bulabilirsiniz.
Ek kaynaklar
Aşağıdaki eğitimlerde Python’da diğer genel görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
Python’da doğrusal regresyon nasıl gerçekleştirilir
Python’da Lojistik Regresyon Nasıl Gerçekleştirilir
Python’da K-Fold çapraz doğrulama nasıl gerçekleştirilir
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil