R'de k-ortalama kümeleme: adım adım örnek
Kümeleme, bir veri seti içindeki gözlem gruplarını bulmaya çalışan bir makine öğrenme tekniğidir.
Amaç, her küme içindeki gözlemlerin birbirine oldukça benzer olduğu, farklı kümelerdeki gözlemlerin ise birbirinden oldukça farklı olduğu kümeleri bulmaktır.
Kümeleme bir denetimsiz öğrenme biçimidir çünkü biz bir yanıt değişkeninin değerini tahmin etmek yerine yalnızca bir veri kümesi içindeki yapıyı bulmaya çalışıyoruz.
Kümeleme genellikle işletmelerin aşağıdaki gibi bilgilere erişimi olduğunda pazarlamada kullanılır:
- Hane geliri
- Ev büyüklüğü
- Hane Reisi Mesleği
- En yakın kentsel alana uzaklık
Bu bilgi mevcut olduğunda kümeleme, benzer olan ve belirli ürünleri satın alma veya belirli bir reklam türüne daha iyi yanıt verme olasılığı daha yüksek olan haneleri belirlemek için kullanılabilir.
Kümelemenin en yaygın biçimlerinden biri k-ortalama kümelemesi olarak bilinir.
K-Means Kümelemesi nedir?
K-ortalama kümelemesi, bir veri kümesindeki her gözlemi K kümesinden birine yerleştirdiğimiz bir tekniktir.
Nihai amaç, her küme içindeki gözlemlerin birbirine oldukça benzer olduğu, farklı kümelerdeki gözlemlerin ise birbirinden oldukça farklı olduğu K kümeye sahip olmaktır.
Uygulamada, K-aracı kümelemesini gerçekleştirmek için aşağıdaki adımları kullanırız:
1. K için bir değer seçin.
- Öncelikle veride kaç tane küme tanımlamak istediğimize karar vermemiz gerekiyor. Çoğunlukla K için birkaç farklı değeri test etmemiz ve belirli bir problem için hangi sayıda kümenin en anlamlı göründüğünü görmek için sonuçları analiz etmemiz gerekir.
2. Her gözlemi rastgele olarak 1’den K’ye kadar bir başlangıç kümesine atayın.
3. Küme atamalarının değişmesi durana kadar aşağıdaki prosedürü uygulayın.
- Her K kümesi için kümenin ağırlık merkezini hesaplayın. Bu basitçe k’inci kümenin gözlemleri için p- ortalama özelliklerinin vektörüdür.
- Her gözlemi en yakın merkeze sahip kümeye atayın. Burada en yakın , Öklid mesafesi kullanılarak tanımlanır.
K-R’de Kümeleme Anlamına Gelir
Aşağıdaki eğitimde, R’de k-aracı kümelemenin nasıl gerçekleştirileceğine ilişkin adım adım bir örnek sağlanmaktadır.
Adım 1: Gerekli paketleri yükleyin
İlk olarak, R’de k-means kümelemesi için çeşitli yararlı işlevler içeren iki paket yükleyeceğiz.
library (factoextra) library (cluster)
2. Adım: Verileri Yükleyin ve Hazırlayın
Bu örnek için, 1973’te her ABD eyaletinde 100.000 kişi başına cinayet , saldırı ve tecavüz nedeniyle tutuklananların sayısını ve ayrıca her eyaletin kentsel bölgelerde yaşayan nüfusunun yüzdesini içeren R’de yerleşik USArrests veri kümesini kullanacağız. alanlar. , UrbanPop .
Aşağıdaki kod aşağıdakilerin nasıl yapılacağını gösterir:
- USArrests veri kümesini yükle
- Eksik değerleri olan tüm satırları kaldırın
- Veri kümesindeki her değişkeni ortalama 0 ve standart sapma 1 olacak şekilde ölçeklendirin
#load data df <-USArrests #remove rows with missing values df <- na. omitted (df) #scale each variable to have a mean of 0 and sd of 1 df <- scale(df) #view first six rows of dataset head(df) Murder Assault UrbanPop Rape Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473 Alaska 0.50786248 1.1068225 -1.2117642 2.484202941 Arizona 0.07163341 1.4788032 0.9989801 1.042878388 Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602 California 0.27826823 1.2628144 1.7589234 2.067820292 Colorado 0.02571456 0.3988593 0.8608085 1.864967207
Adım 3: En uygun küme sayısını bulun
R’de k-means kümelemesini gerçekleştirmek için aşağıdaki sözdizimini kullanan yerleşik kmeans() işlevini kullanabiliriz:
kmeans (veriler, merkezler, nstart)
Altın:
- veri: Veri kümesinin adı.
- merkezler: k ile gösterilen küme sayısı.
- nstart: başlangıç konfigürasyonlarının sayısı. Farklı başlangıç kümelerinin farklı sonuçlara yol açması mümkün olduğundan, birkaç farklı başlangıç konfigürasyonunun kullanılması tavsiye edilir. K-means algoritması, küme içindeki en küçük varyasyona yol açan başlangıç konfigürasyonlarını bulacaktır.
Kaç kümenin optimal olduğunu önceden bilmediğimizden, karar vermemize yardımcı olabilecek iki farklı grafik oluşturacağız:
1. Kareler toplamına göre küme sayısı
İlk olarak, küme sayısı ile kareler toplamı toplamının grafiğini oluşturmak için fviz_nbclust() işlevini kullanacağız:
fviz_nbclust(df, kmeans, method = “ wss ”)

Tipik olarak, bu tür bir çizim oluşturduğumuzda, karelerin toplamının “bükülmeye” veya düzleşmeye başladığı bir “diz” ararız. Bu genellikle optimum küme sayısıdır.
Bu grafik için k = 4 kümede küçük bir bükülme veya “bükülme” olduğu görülmektedir.
2. Küme sayısı ve boşluk istatistikleri
Optimum küme sayısını belirlemenin bir başka yolu , sapma istatistiği adı verilen ve farklı k değerleri için toplam küme içi varyasyonu, kümelenme olmayan bir dağılım için beklenen değerleriyle karşılaştıran bir ölçüm kullanmaktır.
Küme paketindeki clusGap() işlevini kullanarak her küme sayısı için boşluk istatistiğini hesaplayabilir, ayrıca fviz_gap_stat() işlevini kullanarak kümeleri boşluk istatistiklerine göre çizebiliriz:
#calculate gap statistic based on number of clusters gap_stat <- clusGap(df, FUN = kmeans, nstart = 25, K.max = 10, B = 50) #plot number of clusters vs. gap statistic fviz_gap_stat(gap_stat)
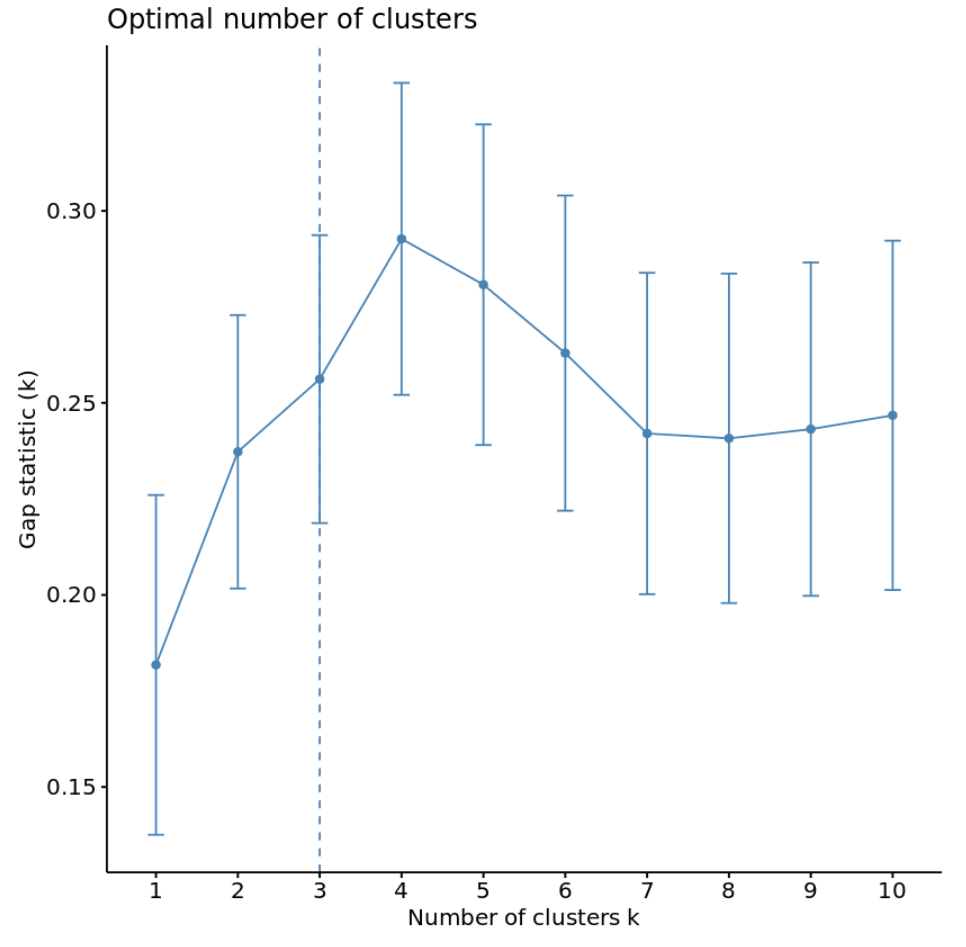
Grafikten boşluk istatistiğinin k = 4 kümede en yüksek olduğunu görebiliriz, bu da daha önce kullandığımız dirsek yöntemine karşılık gelir.
Adım 4: Optimal K ile K-Means Kümelemesini Gerçekleştirin
Son olarak, k 4’ün optimal değerini kullanarak veri kümesi üzerinde k-ortalama kümelemesini gerçekleştirebiliriz:
#make this example reproducible set.seed(1) #perform k-means clustering with k = 4 clusters km <- kmeans(df, centers = 4, nstart = 25) #view results km K-means clustering with 4 clusters of sizes 16, 13, 13, 8 Cluster means: Murder Assault UrbanPop Rape 1 -0.4894375 -0.3826001 0.5758298 -0.26165379 2 -0.9615407 -1.1066010 -0.9301069 -0.96676331 3 0.6950701 1.0394414 0.7226370 1.27693964 4 1.4118898 0.8743346 -0.8145211 0.01927104 Vector clustering: Alabama Alaska Arizona Arkansas California Colorado 4 3 3 4 3 3 Connecticut Delaware Florida Georgia Hawaii Idaho 1 1 3 4 1 2 Illinois Indiana Iowa Kansas Kentucky Louisiana 3 1 2 1 2 4 Maine Maryland Massachusetts Michigan Minnesota Mississippi 2 3 1 3 2 4 Missouri Montana Nebraska Nevada New Hampshire New Jersey 3 2 2 3 2 1 New Mexico New York North Carolina North Dakota Ohio Oklahoma 3 3 4 2 1 1 Oregon Pennsylvania Rhode Island South Carolina South Dakota Tennessee 1 1 1 4 2 4 Texas Utah Vermont Virginia Washington West Virginia 3 1 2 1 1 2 Wisconsin Wyoming 2 1 Within cluster sum of squares by cluster: [1] 16.212213 11.952463 19.922437 8.316061 (between_SS / total_SS = 71.2%) Available components: [1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" [7] "size" "iter" "ifault"
Sonuçlardan şunu görebiliriz:
- İlk kümeye 16 eyalet atandı
- İkinci kümeye 13 eyalet atandı
- Üçüncü kümeye 13 eyalet atandı
- Dördüncü kümeye 8 eyalet atandı
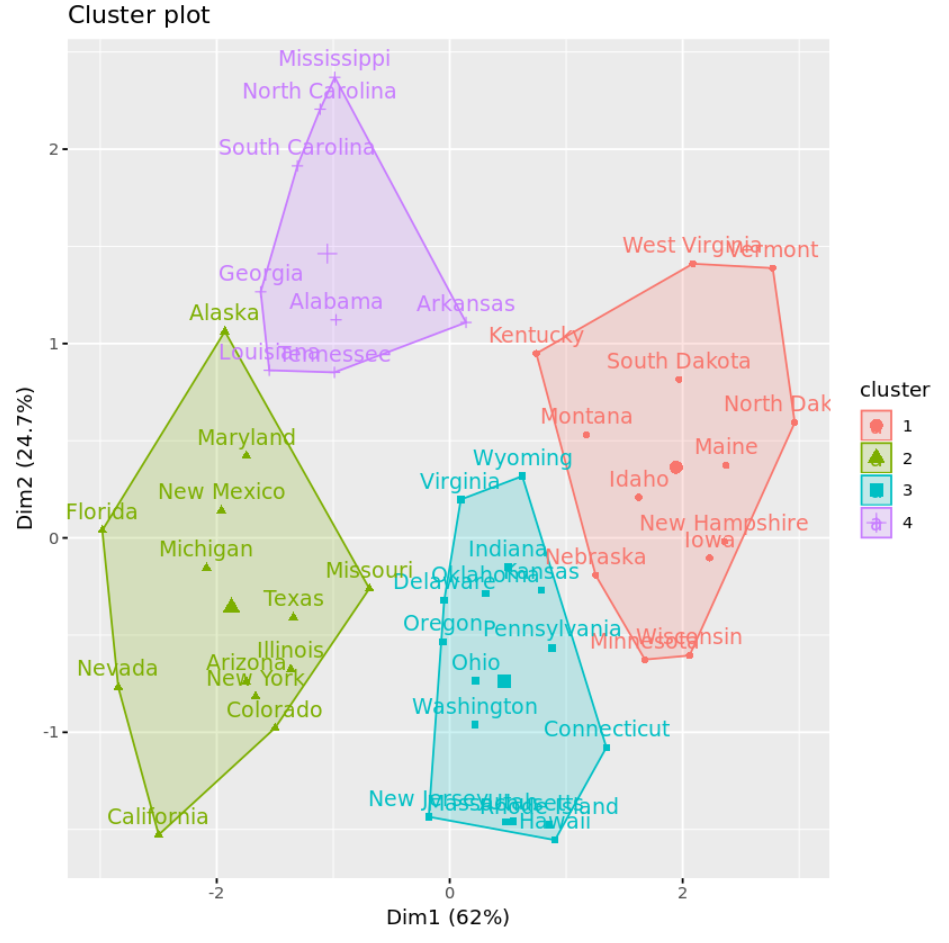
fivz_cluster() işlevini kullanarak eksenlerdeki ilk iki ana bileşeni görüntüleyen bir dağılım grafiğinde kümeleri görselleştirebiliriz:
#plot results of final k-means model
fviz_cluster(km, data = df)
Her kümedeki değişkenlerin ortalamasını bulmak için Aggregate() işlevini de kullanabiliriz:
#find means of each cluster
aggregate(USArrests, by= list (cluster=km$cluster), mean)
cluster Murder Assault UrbanPop Rape
1 3.60000 78.53846 52.07692 12.17692
2 10.81538 257.38462 76.00000 33.19231
3 5.65625 138.87500 73.87500 18.78125
4 13.93750 243.62500 53.75000 21.41250
Bu çıktıyı şu şekilde yorumluyoruz:
- Grup 1 eyaletlerinde 100.000 vatandaş başına düşen ortalama cinayet sayısı 3,6’dır .
- Grup 1 eyaletlerinde 100.000 vatandaş başına ortalama saldırı sayısı 78,5’tir .
- Grup 1 eyaletlerinde kentsel alanda yaşayanların ortalama yüzdesi %52,1’dir .
- Grup 1 eyaletlerinde 100.000 vatandaş başına ortalama tecavüz sayısı 12,2’dir .
Ve benzeri.
Ayrıca her bir durumun küme atamalarını orijinal veri kümesine ekleyebiliriz:
#add cluster assignment to original data
final_data <- cbind(USArrests, cluster = km$cluster)
#view final data
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 4
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 4
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
K-Means Kümelemesinin Avantajları ve Dezavantajları
K-means kümelemesi aşağıdaki avantajları sunar:
- Hızlı bir algoritmadır.
- Büyük veri kümelerini iyi bir şekilde işleyebilir.
Ancak aşağıdaki potansiyel dezavantajlara sahiptir:
- Bu, algoritmayı çalıştırmadan önce küme sayısını belirtmemizi gerektirir.
- Aykırı değerlere karşı duyarlıdır.
K-ortalama kümelemenin iki alternatifi, k-ortalama kümeleme ve hiyerarşik kümelemedir.
Bu örnekte kullanılan R kodunun tamamını burada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil