Kement regresyonuna giriş
Sıradan çoklu doğrusal regresyonda , formun bir modeline uyacak şekilde bir dizi p tahmin değişkeni ve bir yanıt değişkeni kullanırız:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Altın:
- Y : Yanıt değişkeni
- X j : j’inci tahmin değişkeni
- βj : Diğer tüm belirleyicileri sabit tutarak, Xj’deki bir birimlik artışın Y üzerindeki ortalama etkisi
- ε : Hata terimi
β 0 , β 1 , B 2 , …, β p değerleri, artıkların karelerinin toplamını (RSS) en aza indiren en küçük kareler yöntemi kullanılarak seçilir:
RSS = Σ(y ben – ŷ ben ) 2
Altın:
- Σ : Toplam anlamına gelen bir Yunan sembolü
- y i : i’inci gözlem için gerçek yanıt değeri
- ŷ i : Çoklu doğrusal regresyon modeline dayalı olarak tahmin edilen yanıt değeri
Ancak yordayıcı değişkenler yüksek düzeyde korelasyona sahip olduğunda çoklu doğrusallık bir sorun haline gelebilir. Bu, model katsayı tahminlerini güvenilmez hale getirebilir ve yüksek varyans sergileyebilir. Yani model daha önce hiç görmediği yeni bir veri setine uygulandığında muhtemelen düşük performans gösterecektir.
Bu sorunu aşmanın bir yolu, kement regresyonu olarak bilinen ve bunun yerine aşağıdakileri en aza indirmeyi amaçlayan bir yöntem kullanmaktır:
RSS + λΣ|β j |
burada j 1’den p’ye gider ve λ ≥ 0’dır.
Denklemdeki bu ikinci terim çekilme cezası olarak bilinir.
λ = 0 olduğunda, bu ceza teriminin hiçbir etkisi yoktur ve kement regresyonu, en küçük kareler ile aynı katsayı tahminlerini üretir.
Ancak λ sonsuza yaklaştıkça çıkarma cezası daha etkili hale gelir ve modele aktarılamayan tahmin değişkenleri sıfıra indirilir ve hatta bazıları modelden çıkarılır.
Neden Lasso regresyonunu kullanmalıyım?
Kement regresyonunun en küçük kareler regresyonuna göre avantajı önyargı varyansı değiş tokuşudur .
Ortalama Karesel Hatanın (MSE) belirli bir modelin doğruluğunu ölçmek için kullanabileceğimiz bir ölçüm olduğunu ve şu şekilde hesaplandığını hatırlayın:
MSE = Var( f̂( x 0 )) + [Önyargı( f̂( x 0 ))] 2 + Var(ε)
MSE = Varyans + Önyargı 2 + İndirgenemez hata
Kement regresyonunun temel fikri, varyansın önemli ölçüde azaltılabilmesi için küçük bir önyargı eklemek ve böylece daha düşük bir genel MSE’ye yol açmaktır.
Bunu açıklamak için aşağıdaki grafiği inceleyin:

λ arttıkça sapmadaki çok küçük bir artışla varyansın önemli ölçüde azaldığını unutmayın. Ancak belirli bir noktadan sonra varyans daha yavaş azalır ve katsayılardaki azalma onların önemli ölçüde eksik tahmin edilmesine yol açar, bu da yanlılığın keskin bir şekilde artmasına neden olur.
Grafikten, λ için önyargı ve varyans arasında optimal bir denge sağlayan bir değer seçtiğimizde testin MSE’sinin en düşük olduğunu görebiliriz.
λ = 0 olduğunda, kement regresyonundaki ceza teriminin hiçbir etkisi yoktur ve bu nedenle en küçük kareler ile aynı katsayı tahminlerini üretir. Ancak λ’yı belirli bir noktaya artırarak testin genel MSE’sini azaltabiliriz.
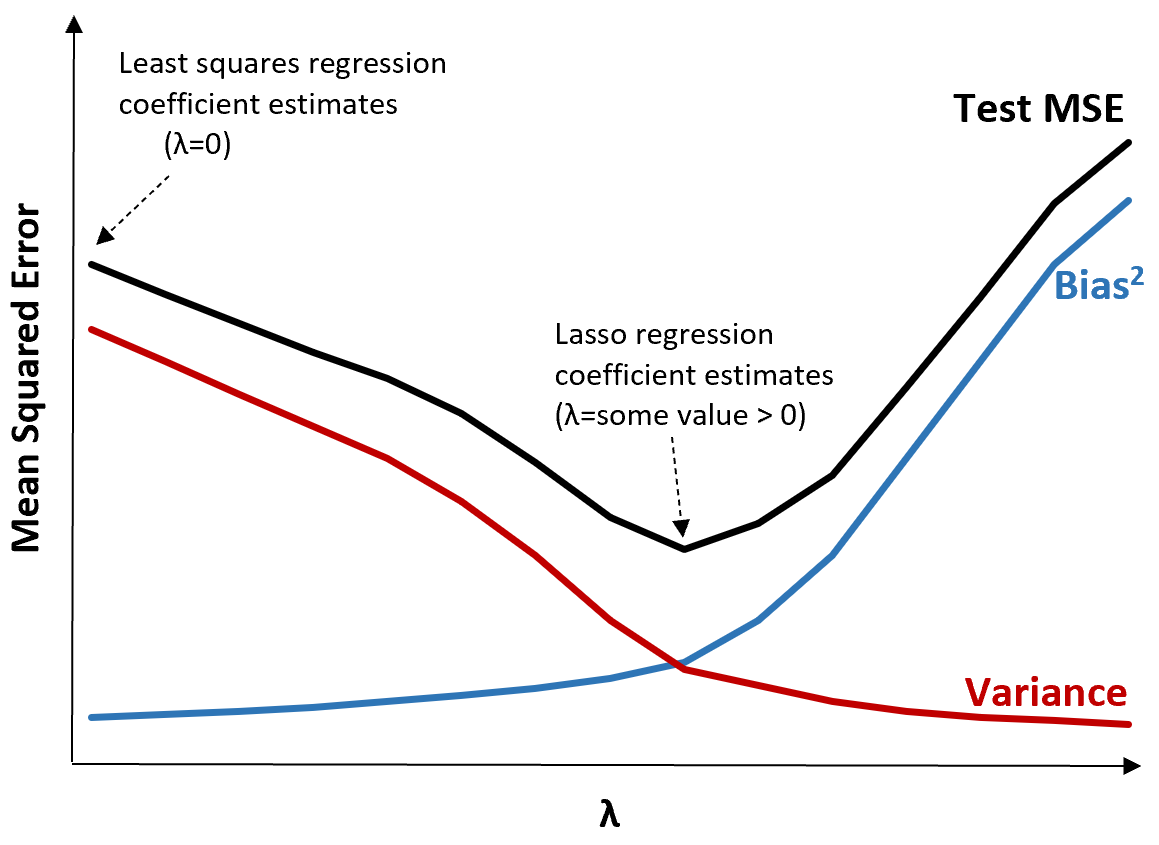
Bu, kement regresyonuyla model uydurmanın, en küçük kareler regresyonuyla model uydurmaya göre daha küçük test hataları üreteceği anlamına gelir.
Kement regresyonu ve Ridge regresyonu
Kement regresyonu ve Ridge regresyonu düzenlileştirme yöntemleri olarak bilinir çünkü her ikisi de artık kareler toplamını (RSS) ve belirli bir ceza süresini en aza indirmeye çalışır.
Başka bir deyişle, model katsayılarının tahminlerini kısıtlar veya düzenlerler .
Ancak kullandıkları ceza terimleri biraz farklıdır:
- Kement regresyonu RSS’yi en aza indirmeye çalışır + λΣ|β j |
- Ridge regresyonu RSS + λΣβ j 2’yi en aza indirmeye çalışır
Ridge regresyonunu kullandığımızda her bir yordayıcının katsayıları sıfıra indirgenir ancak hiçbiri tamamen sıfıra inemez.
Tersine, kement regresyonunu kullandığımızda, λ yeterince büyük olduğunda bazı katsayıların tamamen sıfır olması mümkündür.
Teknik açıdan, kement regresyonu “seyrek” modeller, yani yalnızca tahmin edici değişkenlerin bir alt kümesini içeren modeller üretme kapasitesine sahiptir.
Bu şu soruyu akla getiriyor: Sırt regresyonu mu yoksa kement regresyonu mu daha iyi?
Cevap: duruma göre değişir!
Yalnızca az sayıda öngörücü değişkenin anlamlı olduğu durumlarda, kement regresyonu daha iyi çalışma eğilimindedir çünkü önemsiz değişkenleri tamamen sıfıra indirebilir ve bunları modelden çıkarabilir.
Bununla birlikte, birçok yordayıcı değişken modelde anlamlı olduğunda ve katsayıları yaklaşık olarak eşit olduğunda, ridge regresyonu daha iyi çalışma eğilimindedir çünkü tüm yordayıcıları modelde tutar.
Hangi modelin tahmin yapmada en etkili olduğunu belirlemek için k-katlı çapraz doğrulama yapıyoruz. Hangi model en düşük ortalama kare hatasını (MSE) üretirse kullanılacak en iyi modeldir.
Uygulamada kement regresyonu gerçekleştirme adımları
Kement regresyonu gerçekleştirmek için aşağıdaki adımlar kullanılabilir:
Adım 1: Yordayıcı değişkenler için korelasyon matrisini ve VIF değerlerini hesaplayın.
Öncelikle bir korelasyon matrisi üretip her bir yordayıcı değişken için VIF (varyans enflasyon faktörü) değerlerini hesaplamamız gerekiyor.
Tahmin edici değişkenler ile yüksek VIF değerleri arasında güçlü bir korelasyon tespit edersek (bazı metinler “yüksek” VIF değerini 5 olarak tanımlarken diğerleri 10 kullanır), o zaman kement regresyonu muhtemelen uygundur.
Ancak verilerde çoklu bağlantı yoksa ilk etapta kement regresyonu yapılmasına gerek kalmayabilir. Bunun yerine sıradan en küçük kareler regresyonunu gerçekleştirebiliriz.
Adım 2: Kement regresyon modelini yerleştirin ve λ için bir değer seçin.
Kement regresyonunun uygun olduğunu belirledikten sonra, λ için en uygun değeri kullanarak modeli (R veya Python gibi popüler programlama dillerini kullanarak) sığdırabiliriz.
λ için en uygun değeri belirlemek amacıyla λ için farklı değerler kullanan birden fazla model yerleştirebilir ve λ’yı en düşük MSE testini üreten değer olarak seçebiliriz.
Adım 3: Kement regresyonunu sırt regresyonu ve sıradan en küçük kareler regresyonuyla karşılaştırın.
Son olarak, k-katlı çapraz doğrulamayı kullanarak hangi modelin en düşük MSE testini ürettiğini belirlemek için kement regresyon modelimizi bir ridge regresyon modeli ve en küçük kareler regresyon modeliyle karşılaştırabiliriz.
Yordayıcı değişkenler ile yanıt değişkeni arasındaki ilişkiye bağlı olarak, bu üç modelden birinin farklı senaryolarda diğerlerinden daha iyi performans göstermesi tamamen mümkündür.
R ve Python’da Kement Regresyon
Aşağıdaki eğitimlerde R ve Python’da kement regresyonunun nasıl gerçekleştirileceği açıklanmaktadır:
R’de Kement Regresyon (adım adım)
Python’da Kement Regresyon (Adım Adım)
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil