Pandalarda hareketli ortalama nasıl hesaplanır?
Hareketli ortalama, bir zaman serisindeki önceki dönemlerin ortalamasıdır.
Bir pandas DataFrame’deki bir veya daha fazla sütunun hareketli ortalamasını hesaplamak için aşağıdaki sözdizimini kullanabiliriz:
df[' column_name ']. rolling ( rolling_window ). mean ()
Bu eğitimde bu işlevin pratik kullanımına ilişkin çeşitli örnekler verilmektedir.
Örnek: pandalarda hareketli ortalamanın hesaplanması
Aşağıdaki pandalara sahip olduğumuzu varsayalım DataFrame:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
Önceki 5 dönem için “satışların” hareketli ortalamasını içeren yeni bir sütun oluşturmak için aşağıdaki sözdizimini kullanabiliriz:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
5. dönem için görüntülenen hareketli satış ortalamasının önceki 5 dönemin ortalaması olduğunu manuel olarak doğrulayabiliriz:
5. dönemdeki hareketli ortalama: (61.417+64.900+66.698+64.927+73.720)/5 = 66.33
Birden çok sütunun hareketli ortalamasını hesaplamak için benzer söz dizimini kullanabiliriz:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
Brüt satışları hareketli satış ortalamasına göre görselleştirmek için Matplotlib’i kullanarak hızlı bir çizgi grafiği de oluşturabiliriz:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
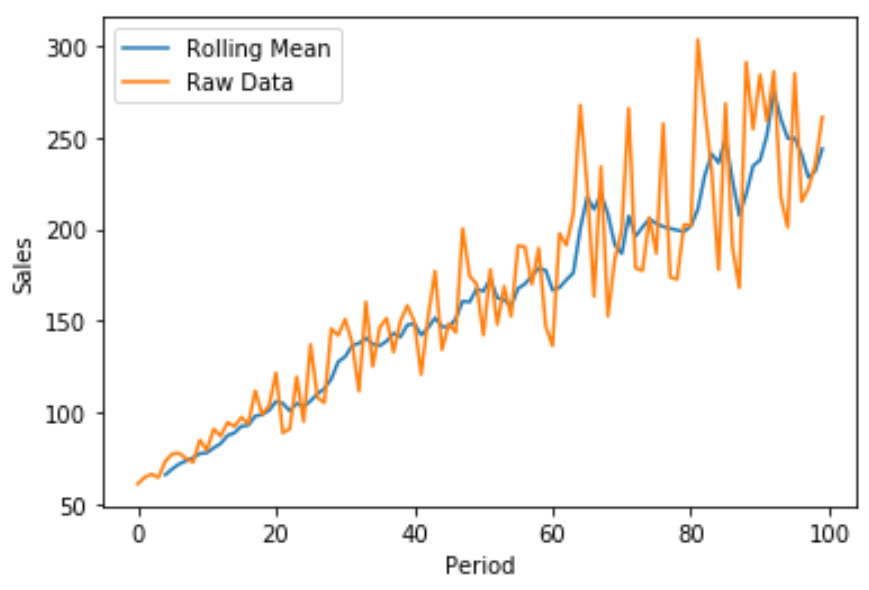
Mavi çizgi satışların 5 dönemlik hareketli ortalamasını, turuncu çizgi ise ham satış verilerini gösteriyor.
Ek kaynaklar
Aşağıdaki eğitimlerde pandalarda diğer ortak görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
Pandalarda kayan korelasyon nasıl hesaplanır
Pandalar’daki sütunların ortalaması nasıl hesaplanır?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil