Makine öğrenimini artırmaya basit bir giriş
Denetimli makine öğrenimi algoritmalarının çoğu, doğrusal regresyon ,lojistik regresyon , sırt regresyonu vb. gibi tek bir tahmin modelinin kullanılmasına dayanır.
Bununla birlikte, torbalama ve rastgele ormanlar gibi yöntemler, orijinal veri kümesinin tekrarlanan önyüklemeli örneklerine dayalı olarak birçok farklı model oluşturur. Yeni verilere ilişkin tahminler, bireysel modellerin yaptığı tahminlerin ortalaması alınarak yapılır.
Bu yöntemler, aşağıdaki süreci kullandıkları için yalnızca tek bir tahmin modeli kullanan yöntemlere göre tahmin doğruluğunda bir gelişme sunma eğilimindedir:
- İlk olarak, yüksek varyansa ve düşük önyargıya sahip bireysel modeller oluşturun (örneğin, derinden gelişmiş karar ağaçları ).
- Daha sonra, varyansı azaltmak için bireysel modellerin yaptığı tahminlerin ortalamasını alın.
Tahmin doğruluğunda daha da büyük bir gelişme sunma eğiliminde olan başka bir yöntem, artırma olarak bilinir.
Artırma Nedir?
Boosting her türlü modelle kullanılabilen bir yöntemdir ancak en çok karar ağaçlarıyla kullanılır.
Güçlendirmenin ardındaki fikir basittir:
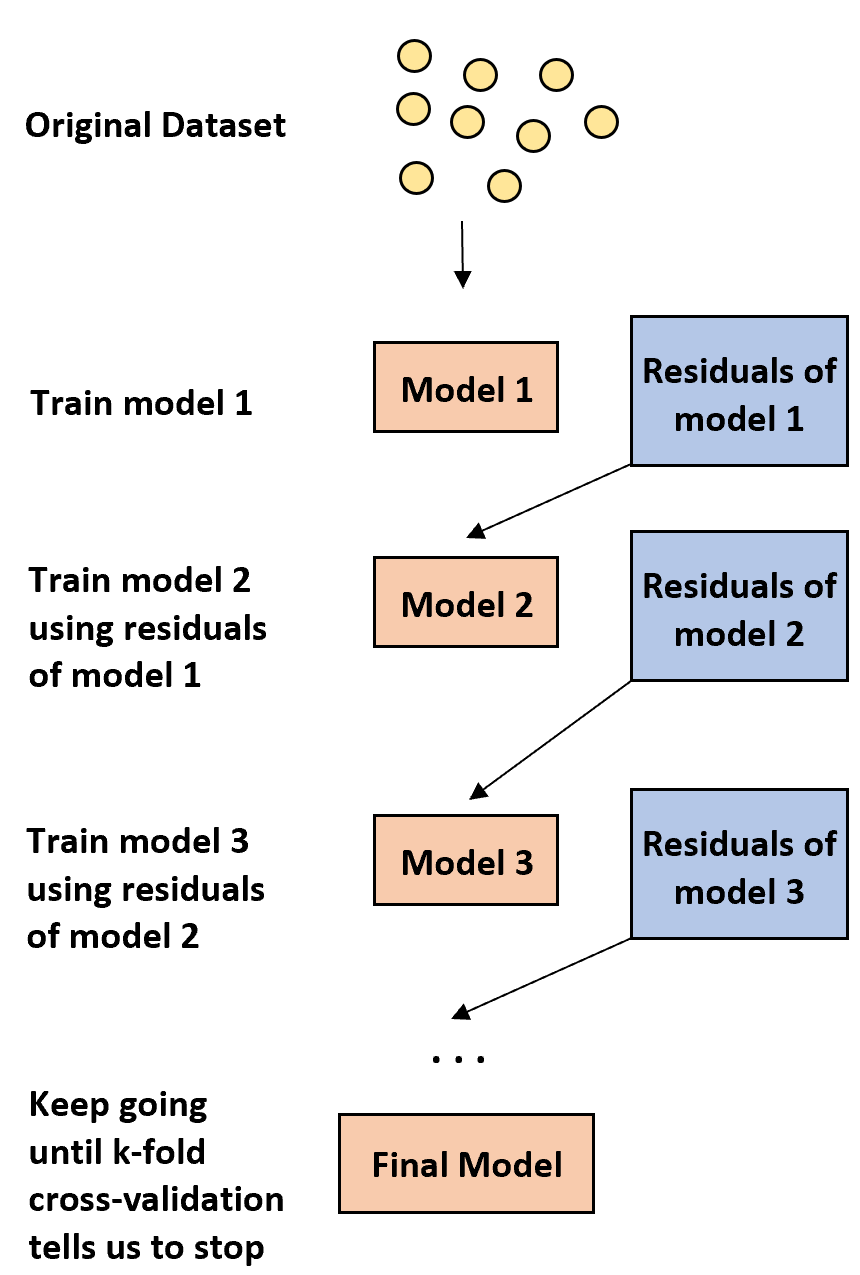
1. Öncelikle zayıf bir model oluşturun.
- “Zayıf” bir model, hata oranı rastgele bir tahminden yalnızca biraz daha iyi olan modeldir.
- Uygulamada bu genellikle yalnızca bir veya iki bölümden oluşan bir karar ağacıdır.
2. Daha sonra, önceki modelin artıklarına dayanarak başka bir zayıf model oluşturun.
- Uygulamada, genel hata oranını biraz iyileştiren yeni bir modele uymak için önceki modelden kalanları (yani tahminlerimizdeki hataları) kullanırız.
3. K-katlı çapraz doğrulama bize durmamızı söyleyene kadar bu işleme devam edin.
- Uygulamada, güçlendirilmiş modeli geliştirmeyi ne zaman durdurmamız gerektiğini belirlemek için k-katlı çapraz doğrulamayı kullanırız.
Bu yöntemi kullanarak, zayıf bir modelle başlayabilir ve yüksek tahmin doğruluğuna sahip son bir model elde edene kadar önceki ağacın performansını artıran yeni ağaçları sırayla oluşturarak performansını “iyileştirmeye” devam edebiliriz.
Yükseltme neden işe yarıyor?
Güçlendirmenin tüm makine öğrenimindeki en güçlü modellerden bazılarını üretme kapasitesine sahip olduğu ortaya çıktı.
Pek çok sektörde güçlendirilmiş modeller, diğer tüm modellerden daha iyi performans gösterme eğiliminde oldukları için üretimde referans modeller olarak kullanılıyor.
Geliştirilmiş şablonların bu kadar iyi çalışmasının nedeni basit bir fikri anlamaktan geçiyor:
1. İlk olarak, geliştirilmiş modeller, tahmin doğruluğu düşük, zayıf bir karar ağacı oluşturur. Bu karar ağacının düşük varyansa ve yüksek önyargıya sahip olduğu söylenir.
2. Geliştirilen modeller, önceki karar ağaçlarının sıralı iyileştirme sürecini takip ettiğinden, genel model, varyansı önemli ölçüde artırmadan her adımda önyargıyı yavaşça azaltabilir.
3. Nihai takılan model, yeterince düşük yanlılığa ve varyansa sahip olma eğilimindedir; bu da yeni veriler üzerinde düşük test hatası oranları üretebilen bir modele yol açar.
Yükseltmenin avantajları ve dezavantajları
Boosting’in bariz avantajı, hemen hemen tüm diğer model türleriyle karşılaştırıldığında yüksek tahmin doğruluğuna sahip modeller üretebilmesidir.
Potansiyel bir dezavantaj, uygun şekilde geliştirilmiş bir modelin yorumlanmasının çok zor olmasıdır. Her ne kadar yeni verilerin yanıt değerlerini tahmin etme konusunda muazzam bir yetenek sunsa da bunu başarmak için kullandığı süreci tam olarak açıklamak zordur.
Uygulamada çoğu veri bilimci ve makine öğrenimi uygulayıcısı, yeni verilerin yanıt değerlerini doğru bir şekilde tahmin edebilmek istedikleri için gelişmiş modeller oluşturur. Bu nedenle geliştirilmiş modellerin yorumlanmasının zor olması genellikle bir sorun değildir.
Pratikte güçlendirici
Uygulamada, güçlendirme için kullanılan birçok algoritma türü vardır:
Veri setinizin büyüklüğüne ve makinenizin işlem gücüne bağlı olarak bu yöntemlerden biri diğerine tercih edilebilir.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil