Python'da cook'un mesafesi nasıl hesaplanır?
Cook mesafesi, bir regresyon modelinde etkili gözlemleri tanımlamak için kullanılır.
Cook mesafesinin formülü:
d ben = (r i 2 / p*MSE) * (h ii / (1-h ii ) 2 )
Altın:
- r i i’inci kalıntıdır
- p , regresyon modelindeki katsayıların sayısıdır
- MSE ortalama kare hatasıdır
- h ii i’inci kaldıraç değeridir
Cook mesafesi esasen i’inci gözlem kaldırıldığında modelin tüm uyum değerlerinin ne kadar değiştiğini ölçer.
Cook mesafesinin değeri ne kadar büyük olursa, belirli bir gözlem o kadar etkili olur.
Genel bir kural olarak, Cook mesafesi 4/n’den büyük olan herhangi bir gözlemin (burada n = toplam gözlemler) büyük bir etkiye sahip olduğu kabul edilir.
Bu eğitimde Python’da belirli bir regresyon modeli için Cook mesafesinin nasıl hesaplanacağına dair adım adım bir örnek sunulmaktadır.
1. Adım: Verileri girin
Öncelikle Python’da çalışacağımız küçük bir veri kümesi oluşturacağız:
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Adım 2: Regresyon modelini yerleştirin
Daha sonra basit bir doğrusal regresyon modeli uygulayacağız:
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
Adım 3: Pişirme Mesafesini Hesaplayın
Daha sonra modeldeki her gözlem için Cook mesafesini hesaplayacağız:
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Varsayılan olarak, Cooks_distance() işlevi, her gözlem için Cook’un mesafesine ilişkin bir dizi değer ve ardından karşılık gelen p değerleri dizisini görüntüler.
Örneğin:
- Cook’un gözlem #1 mesafesi: 0,368 (p değeri: 0,701)
- Gözlem #2 için Cook mesafesi: 0,061 (p değeri: 0,941)
- Cook’un gözlem #3 mesafesi: 0,001 (p değeri: 0,999)
Ve benzeri.
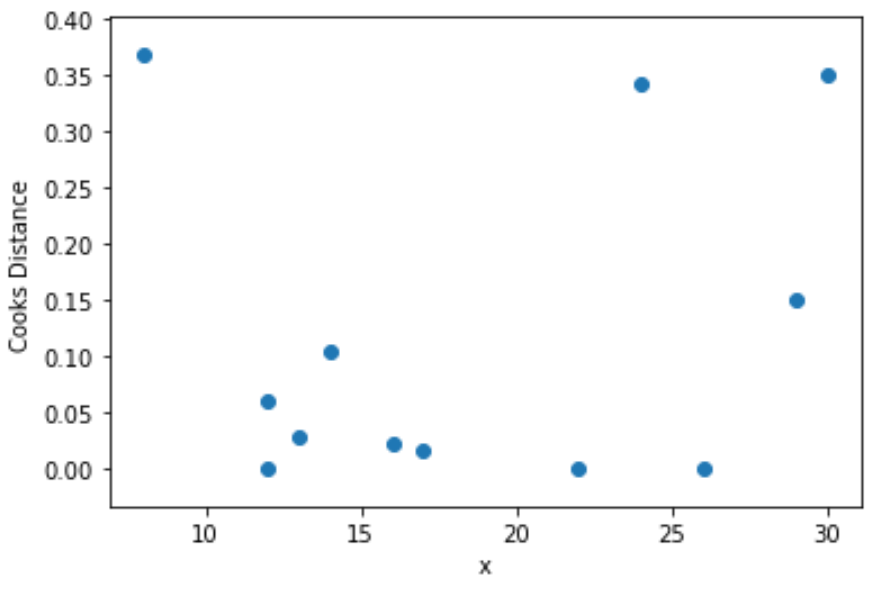
Adım 4: Aşçının mesafelerini görselleştirin
Son olarak, tahmin değişkeninin değerlerini her gözlem için Cook mesafesinin bir fonksiyonu olarak görselleştirmek için bir dağılım grafiği oluşturabiliriz:
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
Son düşünceler
Potansiyel olarak etkili gözlemleri tanımlamak için Cook mesafesinin kullanılması gerektiğine dikkat etmek önemlidir. Bir gözlemin etkili olması onun veri kümesinden çıkarılması gerektiği anlamına gelmez.
Öncelikle gözlemin bir veri girişi hatasının veya başka bir garip olayın sonucu olmadığını doğrulamanız gerekir. Meşru bir değer olduğu ortaya çıkarsa, onu kaldırmanın, olduğu gibi bırakmanın veya sadece medyan gibi alternatif bir değerle değiştirmenin uygun olup olmadığına karar verebilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil