Oranlardaki farkın örnekleme dağılımı
Bu makalede orantısal örnekleme dağılımındaki farkın ne olduğu ve istatistikte ne için kullanıldığı açıklanmaktadır. Oranlardaki fark örnekleme dağılım formülü ve adım adım çözülmüş bir alıştırma da sunulmaktadır.
Oranlardaki farkın örneklem dağılımı nedir?
Orantısal örnekleme dağılımındaki fark , iki farklı popülasyondan olası tüm örneklerin örnekleme oranları arasındaki farkların hesaplanmasından kaynaklanan dağılımdır.
Yani, oranlardaki farkın örnekleme dağılımını elde etme süreci, ilk olarak iki farklı popülasyondan olası tüm örneklerin çıkarılması, ikinci olarak çıkarılan her örneğin oranının belirlenmesi ve son olarak tüm popülasyonlar arasındaki farkın belirlenmesidir. oranlar farkının oranları. iki popülasyon. Böylece bu işlemler yapıldıktan sonra elde edilen sonuçlar kümesi, orantısal farkın örnekleme dağılımını oluşturur.

İstatistikte, orantısal örnekleme dağılımındaki fark, rastgele seçilen iki örneğin örneklem oranları arasındaki farkın popülasyon oranlarındaki farka yakın olma olasılığını hesaplamak için kullanılır.
Oran Farkının Örnekleme Dağılımı Formülü
Orantı örnekleme dağılımındaki fark için seçilen örnekler binom dağılımlarıyla tanımlanır, çünkü pratik amaçlar için oran, başarılı vakaların toplam gözlem sayısına oranıdır.
Bununla birlikte, merkezi limit teoremi nedeniyle binom dağılımları normal olasılık dağılımlarına yaklaştırılabilir. Bu nedenle oranlardaki farkın örnekleme dağılımı, aşağıdaki özelliklerle normal bir dağılıma yaklaştırılabilir:
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
Not: Oranlardaki farkın örnekleme dağılımı ancak aşağıdaki durumlarda normal dağılıma yaklaşabilir:

,

,

,

,

Ve

.
Dolayısıyla oranlardaki farkın örnekleme dağılımı normal bir dağılıma yakınlaştırılabileceğinden, oranlardaki farkın örnekleme dağılımının istatistiğini hesaplama formülü aşağıdaki gibidir:

Altın:
-

örnek oranı i’dir.
-

i nüfus oranıdır.
-

i popülasyonunun başarısızlık olasılığıdır,

.
-

örneklem büyüklüğü i’dir.
-

standart normal dağılım N(0,1) tarafından tanımlanan bir değişkendir.
Bu formül, oranlar arasındaki fark için hipotez testi formülüne benzer.
Oranlar farkının örnekleme dağılımının somut örneği
Oranlar Farkı Örnekleme Dağılımı’nın tanımını ve formülünün ne olduğunu gördükten sonra, kavramı anlamayı tamamlamak için adım adım çözülmüş bir örneği aşağıda görebilirsiniz.
- İki üretim tesisinin doğruluğunu analiz etmek istiyorsunuz; bir fabrika, üretilen parçaların yalnızca %5’inde kusur olacak şekilde üretim yaparken, başka bir fabrikanın hatalı parça yüzdesi %8 olacak şekilde üretim yapıyor. Birinci fabrikadan 200 parçalık bir numune ve ikinci fabrikadan da 280 parçalık bir numune alırsak, ilk üretim tesisindeki kusur yüzdesinin ikinci fabrikadaki kusur yüzdesinden daha büyük olma olasılığı nedir? üretme?
Sorunun tüm verilerini bilmeyi tamamlamak için öncelikle her fabrikanın iyi üretilen parçalarının oranını hesaplayacağız:
![\begin{array}{c}q_1=1-p_1=1-0,05=0,95\\[2ex]q_2=1-p_2=1-0,08=0,92\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7c02732cc5fb319bfa5bf7b8ed8d03db_l3.png "Rendered by QuickLaTeX.com")
Eğer birinci fabrikadaki kusur oranı ikinci fabrikadaki kusur oranından büyükse bu, aşağıdaki denklemin doğru olacağı anlamına gelir:
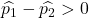

Dolayısıyla, birinci fabrikanın kusur oranının ikinci fabrikanın kusur oranından büyük olma olasılığı, Z değişkeninin 1,34’ten büyük olma olasılığına eşdeğerdir:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]” title=”Rendered by QuickLaTeX.com” height=”19″ width=”242″ style=”vertical-align: -5px;”></p>
</p>
<p> Son olarak, <a href=](https://statorials.org/wp-content/ql-cache/quicklatex.com-41dd897cdff473ff488cde0e3cc140b0_l3.png) normal dağılım tablosunda karşılık gelen olasılığı aramamız yeterli; sorunu zaten çözmüş olacağız:
normal dağılım tablosunda karşılık gelen olasılığı aramamız yeterli; sorunu zaten çözmüş olacağız:
![P[(\widehat{p_1}-\widehat{p_2})>0]=P[Z>1,34]=0,0901″ title=”Rendered by QuickLaTeX.com” height=”19″ width=”319″ style=”vertical-align: -5px;”></p>
</p>
<p> Kısaca birinci fabrikadaki kusur oranının ikinci fabrikadaki kusur oranından büyük olma olasılığı %9,01’dir. </p>
<div style=](https://statorials.org/wp-content/ql-cache/quicklatex.com-8d6e503a2089d30be8fd68bbc722bb44_l3.png) ➤ Bakınız: Ortalamalardaki farkın örnekleme dağılımı
➤ Bakınız: Ortalamalardaki farkın örnekleme dağılımı
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil