R'de polinom regresyon (adım adım)
Polinom regresyon, yordayıcı değişken ile yanıt değişkeni arasındaki ilişkinin doğrusal olmadığı durumlarda kullanabileceğimiz bir tekniktir.
Bu tür bir regresyon şu şekli alır:
Y = β 0 + β 1 X + β 2 X 2 + … + β h
burada h polinomun “derecesidir”.
Bu eğitimde R’de polinom regresyonunun nasıl gerçekleştirileceğine ilişkin adım adım bir örnek sunulmaktadır.
1. Adım: Verileri oluşturun
Bu örnekte, 50 kişilik bir sınıf için çalışılan saat sayısını ve final sınav notunu içeren bir veri seti oluşturacağız:
#make this example reproducible set.seed(1) #create dataset df <- data.frame(hours = runif (50, 5, 15), score=50) df$score = df$score + df$hours^3/150 + df$hours* runif (50, 1, 2) #view first six rows of data head(data) hours score 1 7.655087 64.30191 2 8.721239 70.65430 3 10.728534 73.66114 4 14.082078 86.14630 5 7.016819 59.81595 6 13.983897 83.60510
2. Adım: Verileri görselleştirin
Verilere bir regresyon modeli yerleştirmeden önce, çalışılan saatlerle sınav puanı arasındaki ilişkiyi görselleştirmek için ilk olarak bir dağılım grafiği oluşturalım:
library (ggplot2) ggplot(df, aes (x=hours, y=score)) + geom_point()
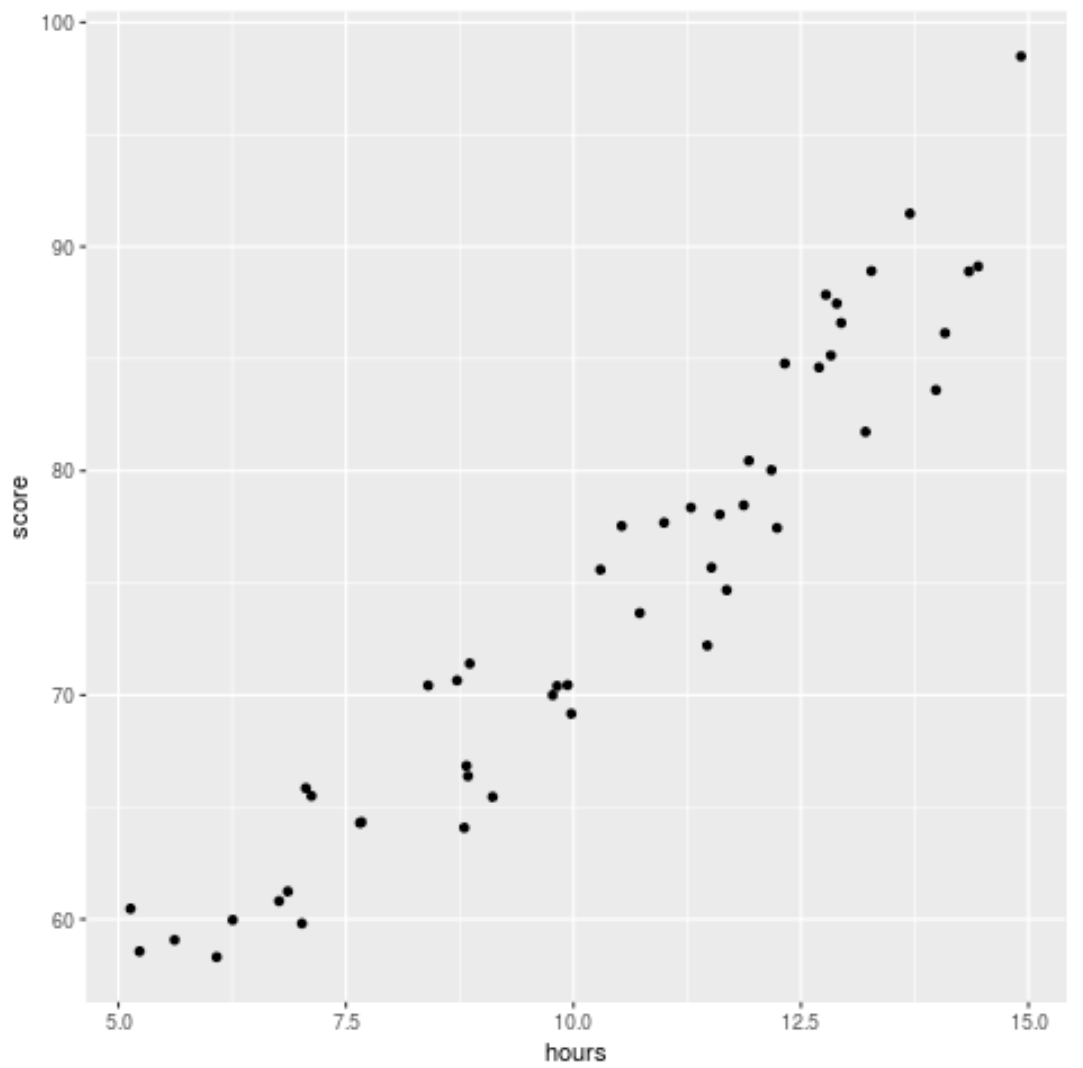
Verilerin hafif ikinci dereceden bir ilişkiye sahip olduğunu görebiliyoruz, bu da polinom regresyonunun verilere basit doğrusal regresyondan daha iyi uyabileceğini gösteriyor.
Adım 3: Polinom regresyon modellerini yerleştirin
Daha sonra, dereceleri h = 1…5 olan beş farklı polinom regresyon modelini yerleştireceğiz ve her model için MSE testini hesaplamak amacıyla k = 10 kez k-katlı çapraz doğrulama kullanacağız:
#randomly shuffle data
df.shuffled <- df[ sample ( nrow (df)),]
#define number of folds to use for k-fold cross-validation
K <- 10
#define degree of polynomials to fit
degree <- 5
#create k equal-sized folds
folds <- cut( seq (1, nrow (df.shuffled)), breaks=K, labels= FALSE )
#create object to hold MSE's of models
mse = matrix(data=NA,nrow=K,ncol=degree)
#Perform K-fold cross validation
for (i in 1:K){
#define training and testing data
testIndexes <- which (folds==i,arr.ind= TRUE )
testData <- df.shuffled[testIndexes, ]
trainData <- df.shuffled[-testIndexes, ]
#use k-fold cv to evaluate models
for (j in 1:degree){
fit.train = lm (score ~ poly (hours,d), data=trainData)
fit.test = predict (fit.train, newdata=testData)
mse[i,j] = mean ((fit.test-testData$score)^2)
}
}
#find MSE for each degree
colMeans(mse)
[1] 9.802397 8.748666 9.601865 10.592569 13.545547
Sonuçtan her model için MSE testini görebiliriz:
- h = 1 derecesi ile MSE testi: 9,80
- h = 2 derecesi ile MSE testi: 8,75
- h = 3 derecesi ile MSE testi: 9,60
- h = 4 dereceli MSE testi: 10,59
- h = 5 dereceli MSE testi: 13,55
En düşük test MSE’sine sahip modelin h = 2 dereceli polinom regresyon modeli olduğu ortaya çıktı.
Bu, orijinal dağılım grafiğindeki sezgimizle eşleşiyor: ikinci dereceden bir regresyon modeli verilere en iyi şekilde uyuyor.
4. Adım: Nihai modeli analiz edin
Son olarak en iyi performans gösteren modelin katsayılarını elde edebiliriz:
#fit best model best = lm (score ~ poly (hours,2, raw= T ), data=df) #view summary of best model summary(best) Call: lm(formula = score ~ poly(hours, 2, raw = T), data = df) Residuals: Min 1Q Median 3Q Max -5.6589 -2.0770 -0.4599 2.5923 4.5122 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 54.00526 5.52855 9.768 6.78e-13 *** poly(hours, 2, raw = T)1 -0.07904 1.15413 -0.068 0.94569 poly(hours, 2, raw = T)2 0.18596 0.05724 3.249 0.00214 ** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Sonuçtan, son takılan modelin şu şekilde olduğunu görebiliriz:
Puan = 54,00526 – 0,07904*(saat) + 0,18596*(saat) 2
Bir öğrencinin çalışılan saat sayısına göre alacağı puanı tahmin etmek için bu denklemi kullanabiliriz.
Örneğin 10 saat ders çalışan bir öğrencinin notunun 71,81 olması gerekir:
Puan = 54,00526 – 0,07904*(10) + 0,18596*(10) 2 = 71,81
Ayrıca ham verilere ne kadar iyi uyduğunu görmek için takılan modeli çizebiliriz:
ggplot(df, aes (x=hours, y=score)) + geom_point() + stat_smooth(method=' lm ', formula = y ~ poly (x,2), size = 1) + xlab(' Hours Studied ') + ylab(' Score ')
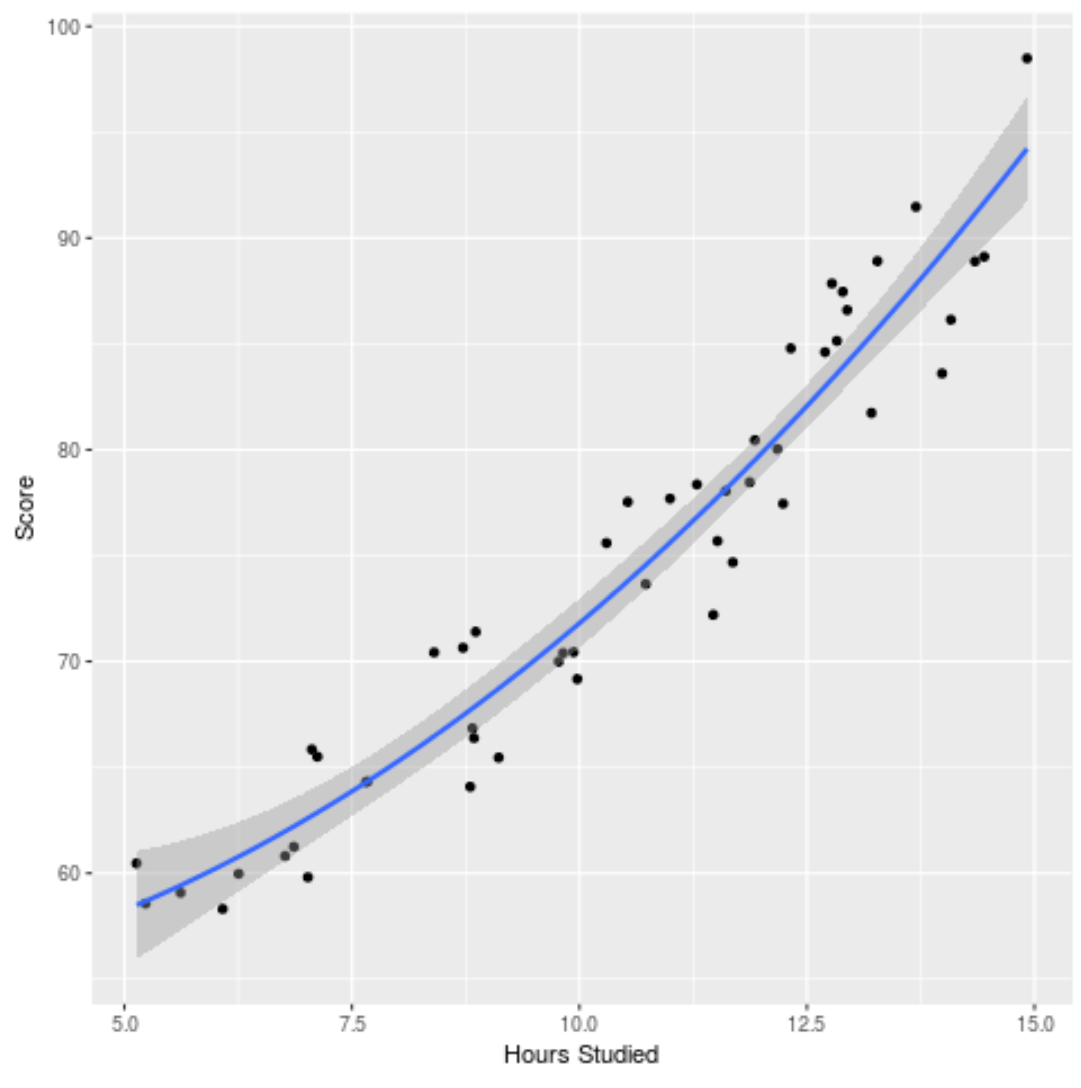
Bu örnekte kullanılan R kodunun tamamını burada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil