Python'da çok boyutlu ölçeklendirme nasıl gerçekleştirilir?
İstatistikte, çok boyutlu ölçeklendirme , soyut bir Kartezyen uzayda (genellikle 2B uzay) bir veri kümesindeki gözlemlerin benzerliğini görselleştirmenin bir yoludur.
Python’da çok boyutlu ölçeklendirmeyi gerçekleştirmenin en kolay yolu, sklearn.manifold alt modülünün MDS() işlevini kullanmaktır.
Aşağıdaki örnekte bu fonksiyonun pratikte nasıl kullanılacağı gösterilmektedir.
Örnek: Python’da Çok Boyutlu Ölçekleme
Çeşitli basketbol oyuncuları hakkında bilgi içeren aşağıdaki pandalar DataFrame’e sahip olduğumuzu varsayalım:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Sklearn.manifold modülünün MDS() fonksiyonu ile çok boyutlu ölçeklendirme gerçekleştirmek için aşağıdaki kodu kullanabiliriz:
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Orijinal DataFrame’in her satırı bir (x, y) koordinatına indirgenmiştir.
Bu koordinatları 2 boyutlu alanda görselleştirmek için aşağıdaki kodu kullanabiliriz:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
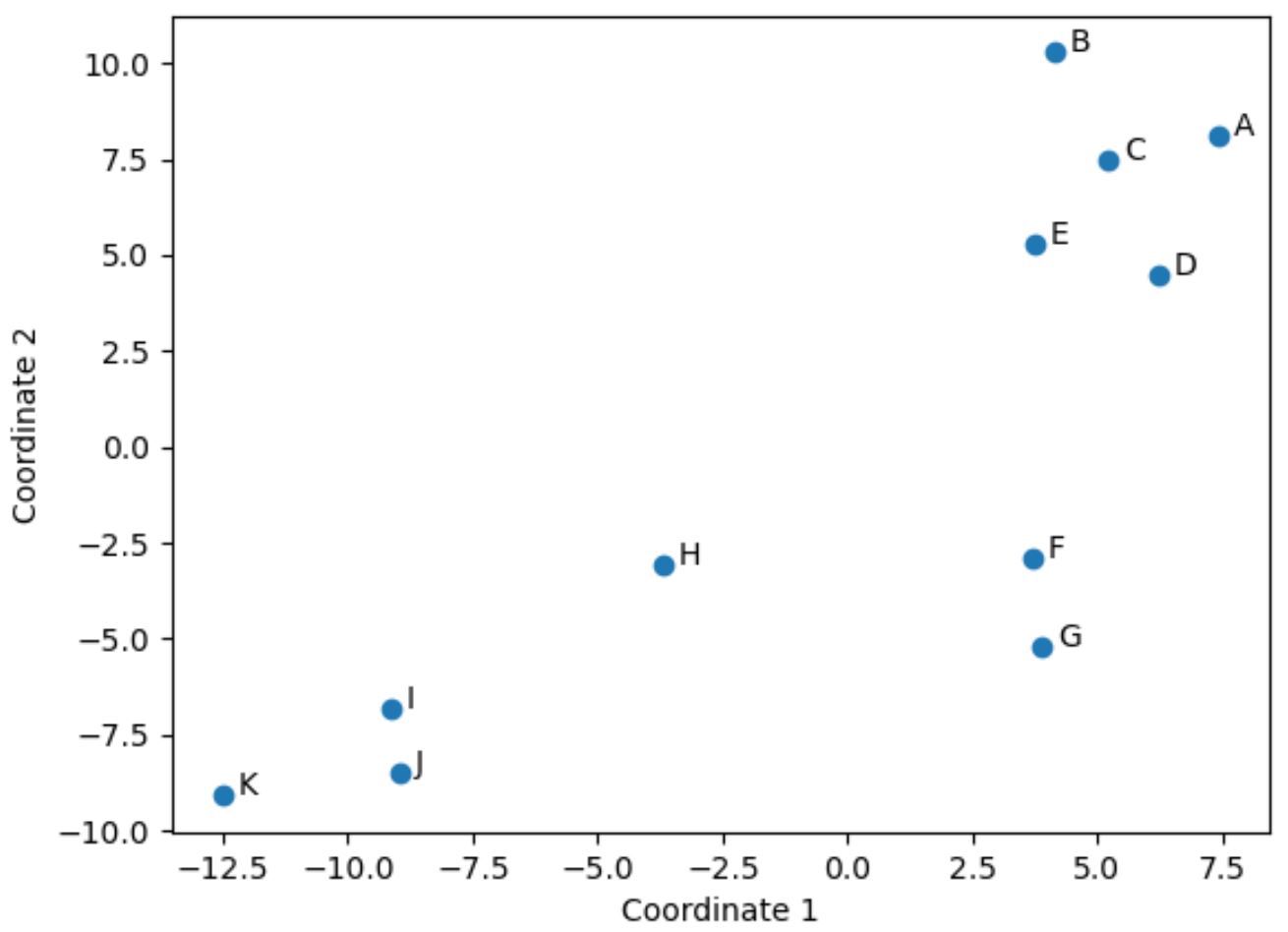
Orijinal DataFrame’de, orijinal dört sütunda (sayılar, asistler, bloklar ve ribaundlar) benzer değerlere sahip olan oyuncular, olay örgüsünde birbirine yakındır.
Örneğin F ve G oyuncuları birbirine kapalıdır. İşte orijinal DataFrame’deki değerleri:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
Sayı, asist, blok ve ribaund değerleri oldukça benzer, bu da 2 boyutlu senaryoda neden birbirlerine bu kadar yakın olduklarını açıklıyor.
Bunun tersine, olay örgüsünde birbirlerinden çok uzakta olan B ve K oyuncularını düşünün.
Orijinal DataFrame’deki değerlerine bakarsak oldukça farklı olduklarını görebiliriz:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Dolayısıyla 2 boyutlu çizim, her oyuncunun DataFframe’deki tüm değişkenler arasında ne kadar benzer olduğunu görselleştirmenin iyi bir yoludur.
Benzer istatistiklere sahip oyuncular birbirine yakın gruplandırılırken, çok farklı istatistiklere sahip oyuncular olay örgüsünde birbirlerinden daha uzakta bulunur.
Ek kaynaklar
Aşağıdaki eğitimlerde Python’da diğer genel görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
Python’da veriler nasıl normalleştirilir?
Python’da Aykırı Değerler Nasıl Kaldırılır
Python’da normallik nasıl test edilir
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil