Optimum kümeleri bulmak i̇çin python'da dirsek yöntemi nasıl kullanılır?
Makine öğreniminde en yaygın kümeleme algoritmalarından biri k-ortalama kümeleme olarak bilinir.
K-ortalama kümelemesi, bir veri kümesindeki her gözlemi K kümesinden birine yerleştirdiğimiz bir tekniktir.
Nihai amaç, her küme içindeki gözlemlerin birbirine oldukça benzer olduğu, farklı kümelerdeki gözlemlerin ise birbirinden oldukça farklı olduğu K kümeye sahip olmaktır.
K-ortalamalı kümeleme yaparken ilk adım, gözlemleri yerleştirmek istediğimiz kümelerin sayısı olan K için bir değer seçmektir.
K için bir değer seçmenin en yaygın yollarından biri, x ekseninde küme sayısı ve y ekseninde karelerin toplamından oluşan bir grafik oluşturmayı ve ardından K değerini belirlemeyi içeren dirsek yöntemi olarak bilinir. olay örgüsünde bir “diz” veya dönüşün göründüğü yer.
X ekseninde “dizin” oluştuğu nokta bize k-ortalamalı kümeleme algoritmasında kullanılacak en uygun küme sayısını söyler.
Aşağıdaki örnek Python’da dirsek yönteminin nasıl kullanılacağını gösterir.
Adım 1: Gerekli modülleri içe aktarın
Öncelikle k-means kümelemesini gerçekleştirmek için ihtiyaç duyacağımız tüm modülleri içe aktaracağız:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
Adım 2: DataFrame’i oluşturun
Daha sonra 20 farklı basketbol oyuncusu için üç değişken içeren bir DataFrame oluşturacağız:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#drop rows with NA values in any columns
df = df. dropna ()
#create scaled DataFrame where each variable has mean of 0 and standard dev of 1
scaled_df = StandardScaler(). fit_transform (df)
Adım 3: Optimum Küme Sayısını Bulmak için Dirsek Yöntemini Kullanın
Diyelim ki bu üç ölçüme dayalı olarak benzer aktörleri bir arada gruplamak için k-means kümelemesini kullanmak istiyoruz.
Python’da k-means kümelemesini gerçekleştirmek için sklearn modülünden KMeans fonksiyonunu kullanabiliriz.
Bu işlevin en önemli argümanı, gözlemlerin kaç kümeye yerleştirileceğini belirten n_clusters’tır .
Optimum küme sayısını belirlemek için, küme sayısını ve modelin SSE’sini (hataların karelerinin toplamı) gösteren bir grafik oluşturacağız.
Daha sonra karelerin toplamının “bükülmeye” veya sabitlenmeye başladığı bir “diz” arayacağız. Bu nokta optimum küme sayısını temsil eder.
Aşağıdaki kod, x ekseninde küme sayısını ve y ekseninde SSE’yi görüntüleyen bu tür grafiğin nasıl oluşturulacağını gösterir:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
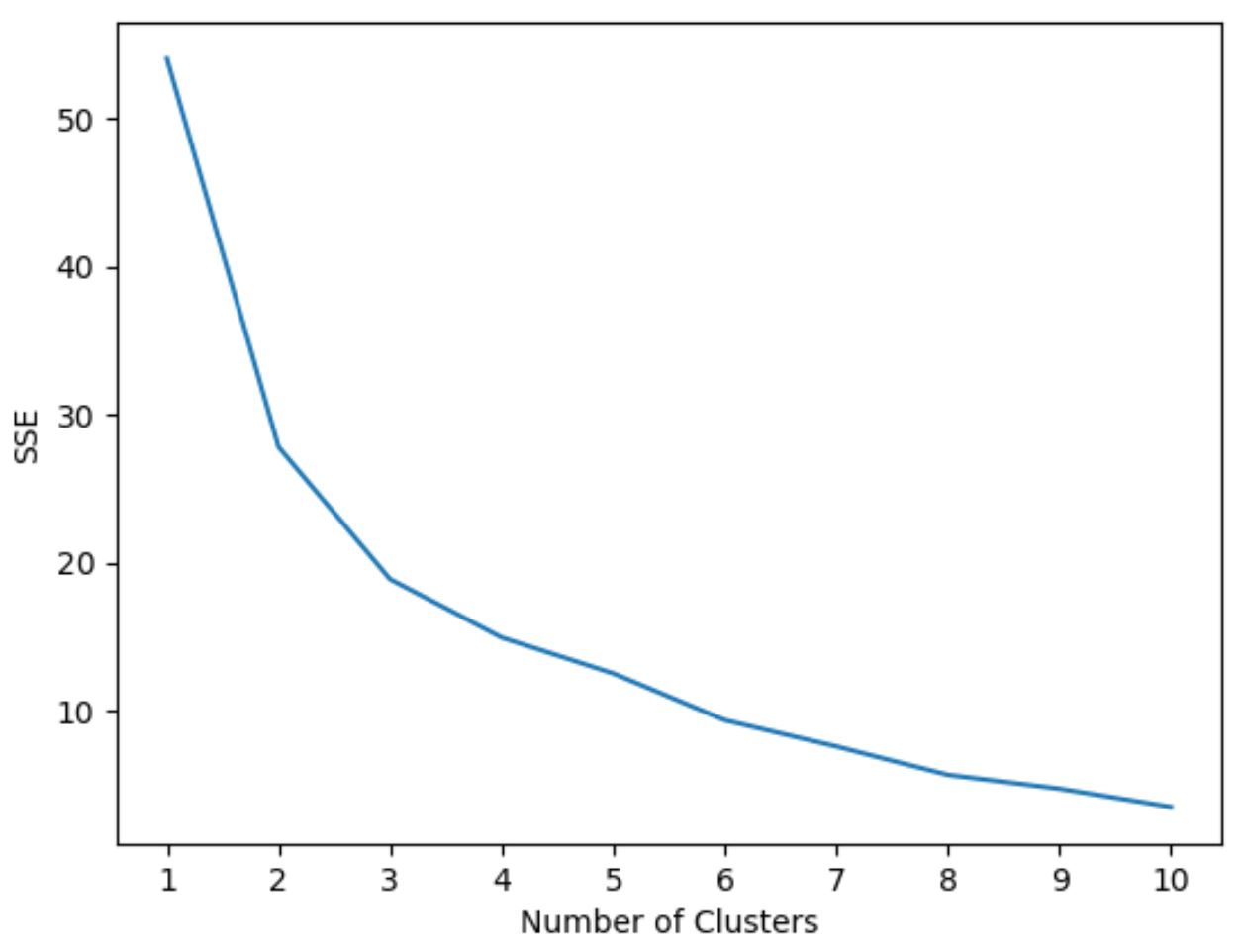
Bu grafikte k = 3 kümede bükülme veya “diz” olduğu görülmektedir.
Dolayısıyla bir sonraki adımda k-ortalama kümeleme modelimizi yerleştirirken 3 küme kullanacağız.
Adım 4: Optimal K ile K-Means Kümelemesini Gerçekleştirin
Aşağıdaki kod, k /3 için en uygun değeri kullanarak veri kümesinde k-ortalamalı kümelemenin nasıl gerçekleştirileceğini gösterir:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Ortaya çıkan tablo, DataFrame’deki her gözlem için küme atamalarını gösterir.
Bu sonuçların yorumlanmasını kolaylaştırmak için DataFrame’e her oyuncunun küme atamasını gösteren bir sütun ekleyebiliriz:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
Küme sütunu, her oyuncunun atandığı küme numarasını (0, 1 veya 2) içerir.
Aynı kümeye ait oyuncular sayı , asist ve ribaund sütunlarında yaklaşık olarak benzer değerlere sahiptir.
Not : Sklearn’in KMeans işlevine ilişkin tüm belgeleri burada bulabilirsiniz.
Ek kaynaklar
Aşağıdaki eğitimlerde Python’da diğer genel görevlerin nasıl gerçekleştirileceği açıklanmaktadır:
Python’da doğrusal regresyon nasıl gerçekleştirilir
Python’da Lojistik Regresyon Nasıl Gerçekleştirilir
Python’da K-Fold çapraz doğrulama nasıl gerçekleştirilir?
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil