Python'da doğrusal diskriminant analizi (adım adım)
Doğrusal diskriminant analizi, bir dizi öngörücü değişkeniniz olduğunda ve bir yanıt değişkenini iki veya daha fazla sınıfa sınıflandırmak istediğinizde kullanabileceğiniz bir yöntemdir.
Bu eğitimde Python’da doğrusal diskriminant analizinin nasıl gerçekleştirileceğine ilişkin adım adım bir örnek sunulmaktadır.
Adım 1: Gerekli Kitaplıkları Yükleyin
Öncelikle bu örnek için gereken fonksiyonları ve kütüphaneleri yükleyeceğiz:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
2. Adım: Verileri yükleyin
Bu örnek için sklearn kütüphanesindeki iris veri setini kullanacağız. Aşağıdaki kod, bu veri kümesinin nasıl yükleneceğini ve kullanım kolaylığı için onu bir pandas DataFrame’e nasıl dönüştüreceğinizi gösterir:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Veri setinin toplamda 150 gözlem içerdiğini görebiliriz.
Bu örnekte, belirli bir çiçeğin hangi türe ait olduğunu sınıflandırmak için doğrusal bir diskriminant analiz modeli oluşturacağız.
Modelde aşağıdaki tahmin değişkenlerini kullanacağız:
- Sepal uzunluğu
- Sepal genişliği
- Petal uzunluğu
- Yaprak genişliği
Bunları, aşağıdaki üç potansiyel sınıfı destekleyen Tür yanıt değişkenini tahmin etmek için kullanacağız:
- setosa
- çok renkli
- Virjinya
3. Adım: LDA modelini ayarlayın
Daha sonra, sklearn’in LinearDiscriminantAnalsys fonksiyonunu kullanarak LDA modelini verilerimize uyarlayacağız:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Adım 4: Tahminlerde bulunmak için modeli kullanın
Verilerimizi kullanarak modeli yerleştirdikten sonra, tekrarlanan katmanlı k-katlı çapraz doğrulamayı kullanarak modelin performansını değerlendirebiliriz.
Bu örnek için 10 katlama ve 3 tekrar kullanacağız:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Modelin ortalama %97,78 doğruluk oranına ulaştığını görebiliyoruz.
Modeli, giriş değerlerine dayanarak yeni bir çiçeğin hangi sınıfa ait olduğunu tahmin etmek için de kullanabiliriz:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Modelin bu yeni gözlemin setosa adı verilen türe ait olduğunu öngördüğünü görüyoruz.
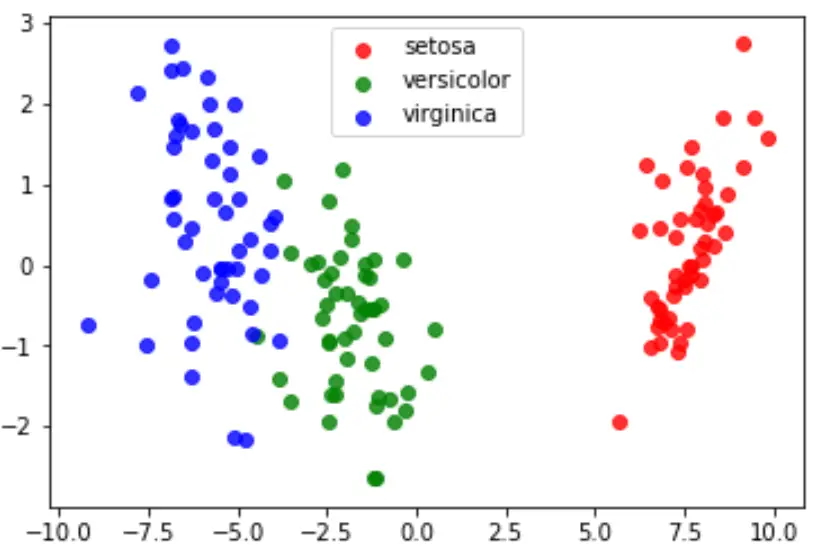
5. Adım: Sonuçları görselleştirin
Son olarak, modelin doğrusal ayırıcılarını görselleştirmek ve veri setimizdeki üç farklı türü ne kadar iyi ayırdığını görselleştirmek için bir LDA grafiği oluşturabiliriz:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
Bu eğitimde kullanılan Python kodunun tamamını burada bulabilirsiniz.
yazar hakkında
Dr.benjamin anderson
Merhaba, ben Benjamin, emekli bir istatistik profesörü ve Statorials öğretmenine dönüştüm. İstatistik alanındaki kapsamlı deneyimim ve uzmanlığımla, öğrencilerimi Statorials aracılığıyla güçlendirmek için bilgilerimi paylaşmaya can atıyorum. Daha fazlasını bil